Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Historical Significance of Textual Distances
Paper and Code
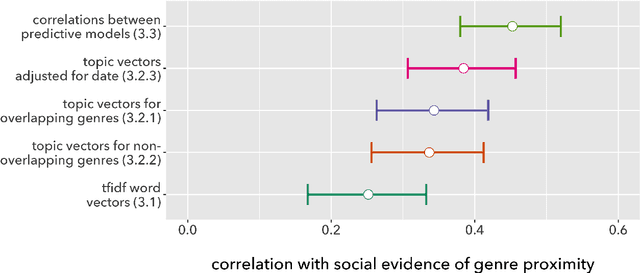
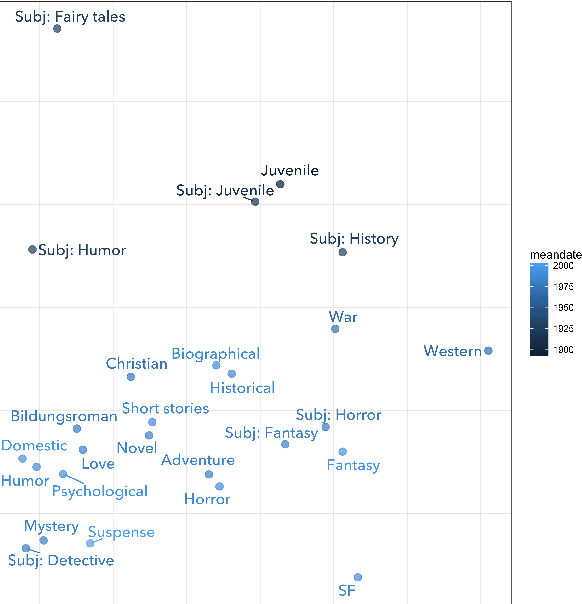
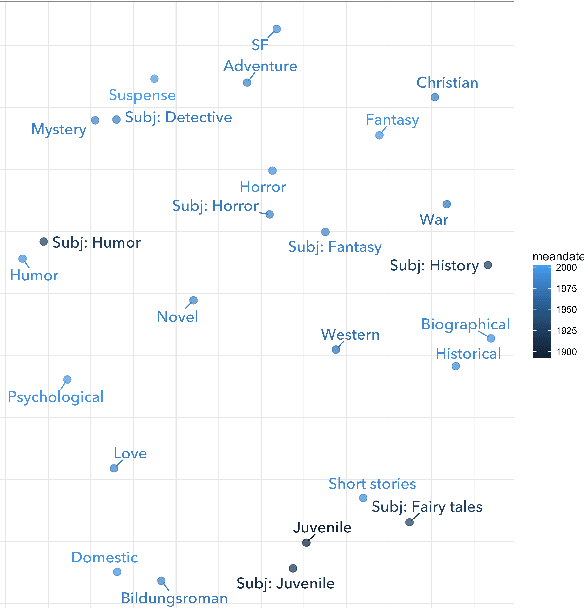

Measuring similarity is a basic task in information retrieval, and now often a building-block for more complex arguments about cultural change. But do measures of textual similarity and distance really correspond to evidence about cultural proximity and differentiation? To explore that question empirically, this paper compares textual and social measures of the similarities between genres of English-language fiction. Existing measures of textual similarity (cosine similarity on tf-idf vectors or topic vectors) are also compared to new strategies that use supervised learning to anchor textual measurement in a social context.
* Preprint of a paper for the 2nd Joint SIGHUM Workshop on
Computational Linguistics for Cultural Heritage, Social Sciences, Humanities
and Literature (LaTeCH-CLfL 2018). Code is available at
https://github.com/tedunderwood/genredistance or, archivally, at
https://zenodo.org/record/1300934
View paper on