 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHilbert Curve Based Molecular Sequence Analysis
Dec 29, 2024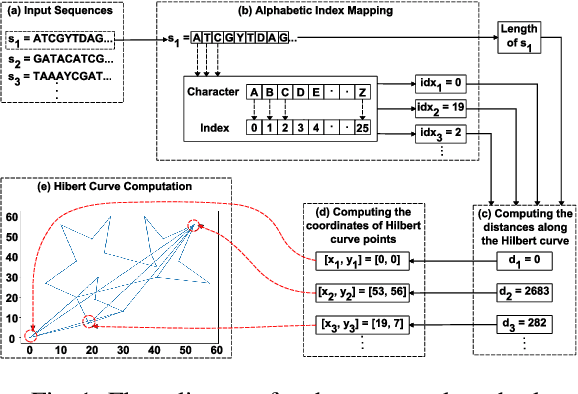
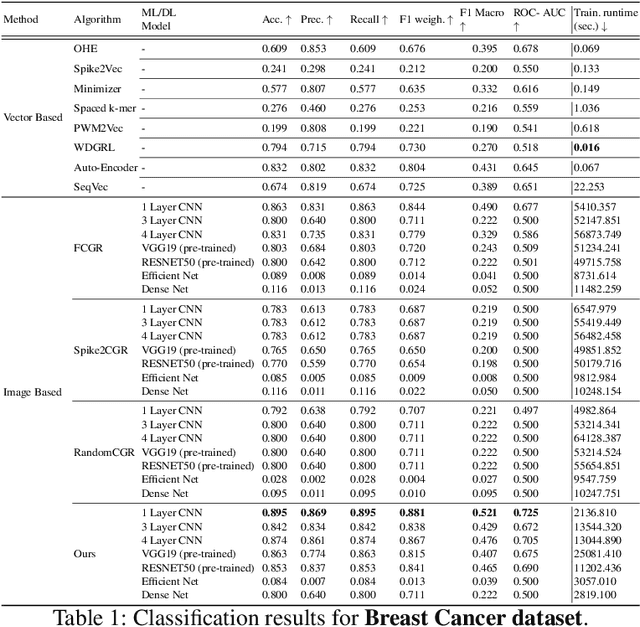
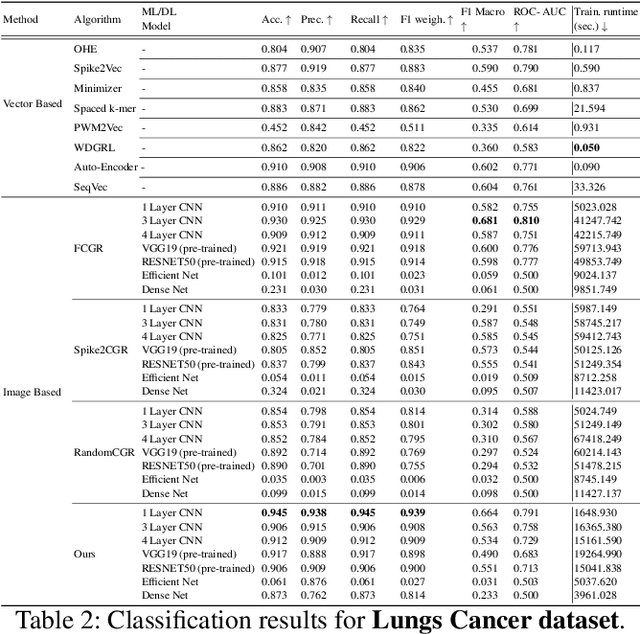
Accurate molecular sequence analysis is a key task in the field of bioinformatics. To apply molecular sequence classification algorithms, we first need to generate the appropriate representations of the sequences. Traditional numeric sequence representation techniques are mostly based on sequence alignment that faces limitations in the form of lack of accuracy. Although several alignment-free techniques have also been introduced, their tabular data form results in low performance when used with Deep Learning (DL) models compared to the competitive performance observed in the case of image-based data. To find a solution to this problem and to make Deep Learning (DL) models function to their maximum potential while capturing the important spatial information in the sequence data, we propose a universal Hibert curve-based Chaos Game Representation (CGR) method. This method is a transformative function that involves a novel Alphabetic index mapping technique used in constructing Hilbert curve-based image representation from molecular sequences. Our method can be globally applied to any type of molecular sequence data. The Hilbert curve-based image representations can be used as input to sophisticated vision DL models for sequence classification. The proposed method shows promising results as it outperforms current state-of-the-art methods by achieving a high accuracy of $94.5$\% and an F1 score of $93.9\%$ when tested with the CNN model on the lung cancer dataset. This approach opens up a new horizon for exploring molecular sequence analysis using image classification methods.
Converting Time Series Data to Numeric Representations Using Alphabetic Mapping and k-mer strategy
Dec 29, 2024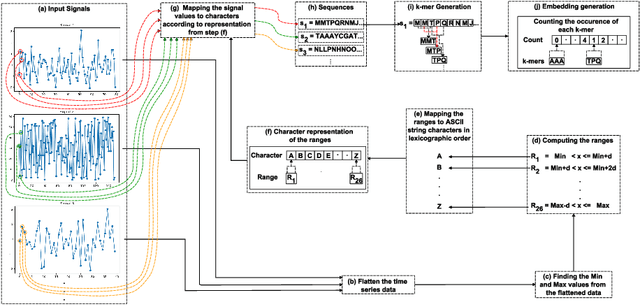
In the realm of data analysis and bioinformatics, representing time series data in a manner akin to biological sequences offers a novel approach to leverage sequence analysis techniques. Transforming time series signals into molecular sequence-type representations allows us to enhance pattern recognition by applying sophisticated sequence analysis techniques (e.g. $k$-mers based representation) developed in bioinformatics, uncovering hidden patterns and relationships in complex, non-linear time series data. This paper proposes a method to transform time series signals into biological/molecular sequence-type representations using a unique alphabetic mapping technique. By generating 26 ranges corresponding to the 26 letters of the English alphabet, each value within the time series is mapped to a specific character based on its range. This conversion facilitates the application of sequence analysis algorithms, typically used in bioinformatics, to analyze time series data. We demonstrate the effectiveness of this approach by converting real-world time series signals into character sequences and performing sequence classification. The resulting sequences can be utilized for various sequence-based analysis techniques, offering a new perspective on time series data representation and analysis.
DWFL: Enhancing Federated Learning through Dynamic Weighted Averaging
Nov 07, 2024
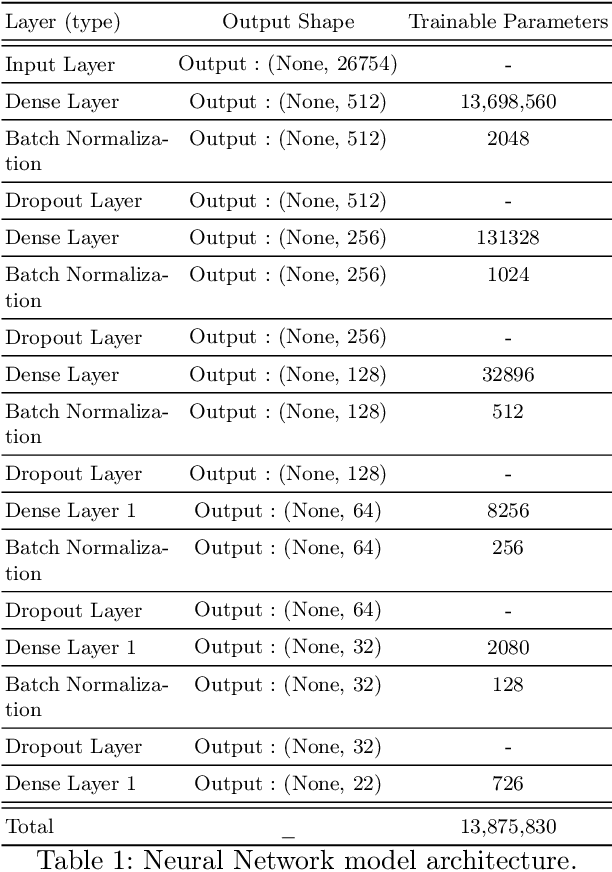
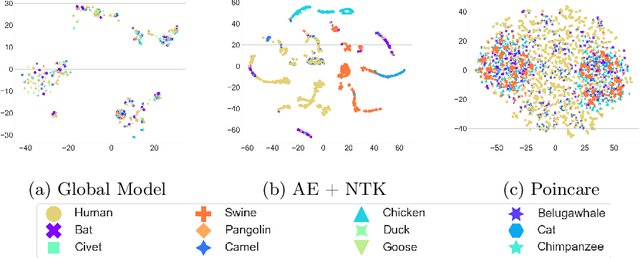
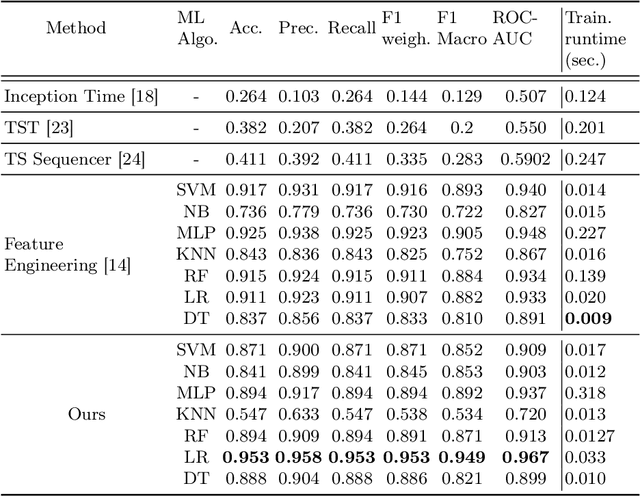
Federated Learning (FL) is a distributed learning technique that maintains data privacy by providing a decentralized training method for machine learning models using distributed big data. This promising Federated Learning approach has also gained popularity in bioinformatics, where the privacy of biomedical data holds immense importance, especially when patient data is involved. Despite the successful implementation of Federated learning in biological sequence analysis, rigorous consideration is still required to improve accuracy in a way that data privacy should not be compromised. Additionally, the optimal integration of federated learning, especially in protein sequence analysis, has not been fully explored. We propose a deep feed-forward neural network-based enhanced federated learning method for protein sequence classification to overcome these challenges. Our method introduces novel enhancements to improve classification accuracy. We introduce dynamic weighted federated learning (DWFL) which is a federated learning-based approach, where local model weights are adjusted using weighted averaging based on their performance metrics. By assigning higher weights to well-performing models, we aim to create a more potent initial global model for the federated learning process, leading to improved accuracy. We conduct experiments using real-world protein sequence datasets to assess the effectiveness of DWFL. The results obtained using our proposed approach demonstrate significant improvements in model accuracy, making federated learning a preferred, more robust, and privacy-preserving approach for collaborative machine-learning tasks.
A Universal Non-Parametric Approach For Improved Molecular Sequence Analysis
Feb 12, 2024

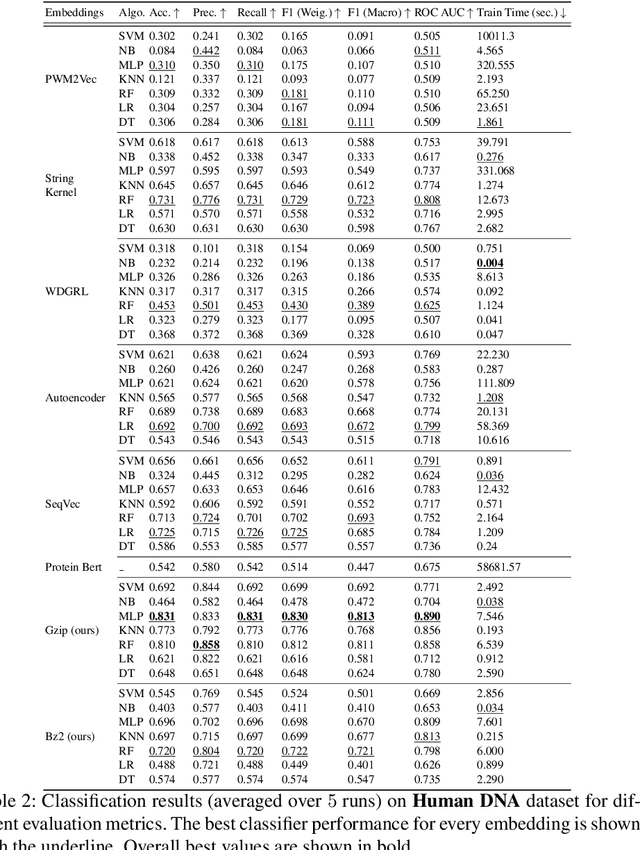
In the field of biological research, it is essential to comprehend the characteristics and functions of molecular sequences. The classification of molecular sequences has seen widespread use of neural network-based techniques. Despite their astounding accuracy, these models often require a substantial number of parameters and more data collection. In this work, we present a novel approach based on the compression-based Model, motivated from \cite{jiang2023low}, which combines the simplicity of basic compression algorithms like Gzip and Bz2, with Normalized Compression Distance (NCD) algorithm to achieve better performance on classification tasks without relying on handcrafted features or pre-trained models. Firstly, we compress the molecular sequence using well-known compression algorithms, such as Gzip and Bz2. By leveraging the latent structure encoded in compressed files, we compute the Normalized Compression Distance between each pair of molecular sequences, which is derived from the Kolmogorov complexity. This gives us a distance matrix, which is the input for generating a kernel matrix using a Gaussian kernel. Next, we employ kernel Principal Component Analysis (PCA) to get the vector representations for the corresponding molecular sequence, capturing important structural and functional information. The resulting vector representations provide an efficient yet effective solution for molecular sequence analysis and can be used in ML-based downstream tasks. The proposed approach eliminates the need for computationally intensive Deep Neural Networks (DNNs), with their large parameter counts and data requirements. Instead, it leverages a lightweight and universally accessible compression-based model.