 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Universal Non-Parametric Approach For Improved Molecular Sequence Analysis
Paper and Code


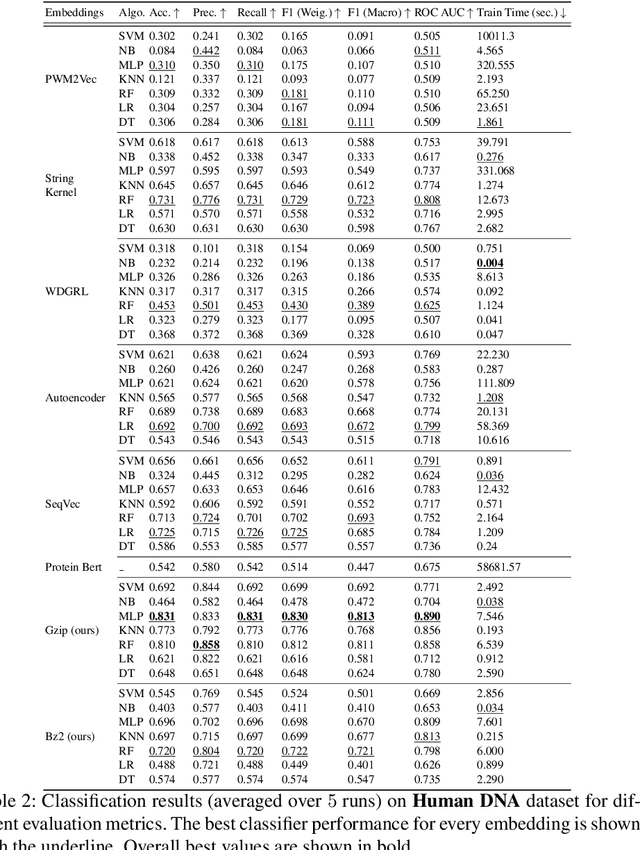
In the field of biological research, it is essential to comprehend the characteristics and functions of molecular sequences. The classification of molecular sequences has seen widespread use of neural network-based techniques. Despite their astounding accuracy, these models often require a substantial number of parameters and more data collection. In this work, we present a novel approach based on the compression-based Model, motivated from \cite{jiang2023low}, which combines the simplicity of basic compression algorithms like Gzip and Bz2, with Normalized Compression Distance (NCD) algorithm to achieve better performance on classification tasks without relying on handcrafted features or pre-trained models. Firstly, we compress the molecular sequence using well-known compression algorithms, such as Gzip and Bz2. By leveraging the latent structure encoded in compressed files, we compute the Normalized Compression Distance between each pair of molecular sequences, which is derived from the Kolmogorov complexity. This gives us a distance matrix, which is the input for generating a kernel matrix using a Gaussian kernel. Next, we employ kernel Principal Component Analysis (PCA) to get the vector representations for the corresponding molecular sequence, capturing important structural and functional information. The resulting vector representations provide an efficient yet effective solution for molecular sequence analysis and can be used in ML-based downstream tasks. The proposed approach eliminates the need for computationally intensive Deep Neural Networks (DNNs), with their large parameter counts and data requirements. Instead, it leverages a lightweight and universally accessible compression-based model.