 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation/Entity-Centric Reading Comprehension
Aug 27, 2020
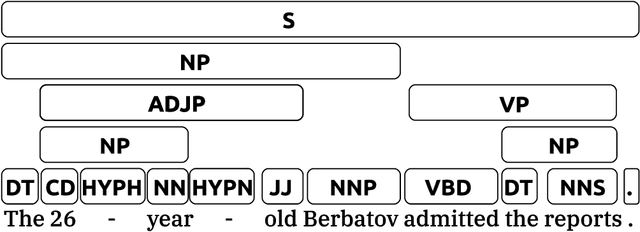
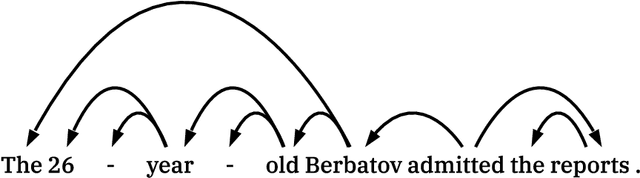

Constructing a machine that understands human language is one of the most elusive and long-standing challenges in artificial intelligence. This thesis addresses this challenge through studies of reading comprehension with a focus on understanding entities and their relationships. More specifically, we focus on question answering tasks designed to measure reading comprehension. We focus on entities and relations because they are typically used to represent the semantics of natural language.
Visual Reasoning of Feature Attribution with Deep Recurrent Neural Networks
Jan 17, 2019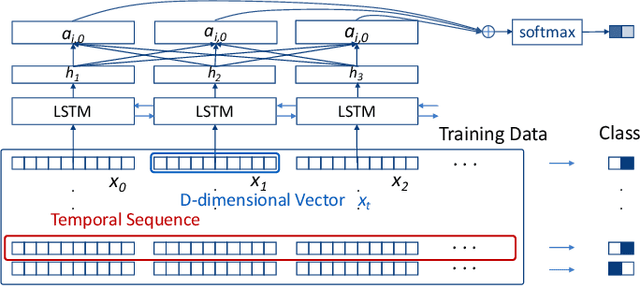


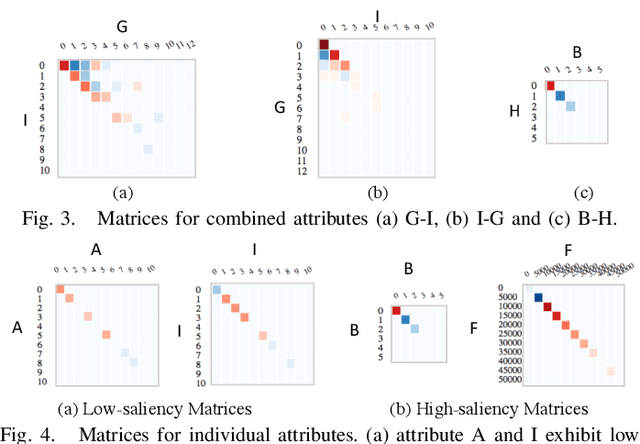
Deep Recurrent Neural Network (RNN) has gained popularity in many sequence classification tasks. Beyond predicting a correct class for each data instance, data scientists also want to understand what differentiating factors in the data have contributed to the classification during the learning process. We present a visual analytics approach to facilitate this task by revealing the RNN attention for all data instances, their temporal positions in the sequences, and the attribution of variables at each value level. We demonstrate with real-world datasets that our approach can help data scientists to understand such dynamics in deep RNNs from the training results, hence guiding their modeling process.
Emergent Predication Structure in Hidden State Vectors of Neural Readers
May 31, 2017


A significant number of neural architectures for reading comprehension have recently been developed and evaluated on large cloze-style datasets. We present experiments supporting the emergence of "predication structure" in the hidden state vectors of these readers. More specifically, we provide evidence that the hidden state vectors represent atomic formulas $\Phi[c]$ where $\Phi$ is a semantic property (predicate) and $c$ is a constant symbol entity identifier.
Who did What: A Large-Scale Person-Centered Cloze Dataset
Aug 19, 2016
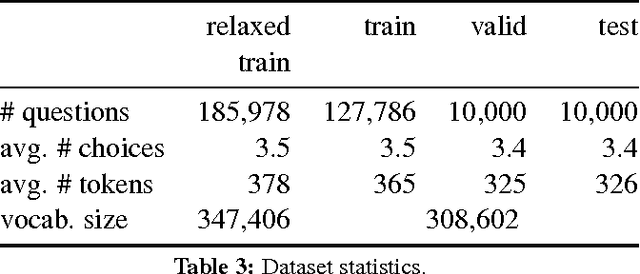
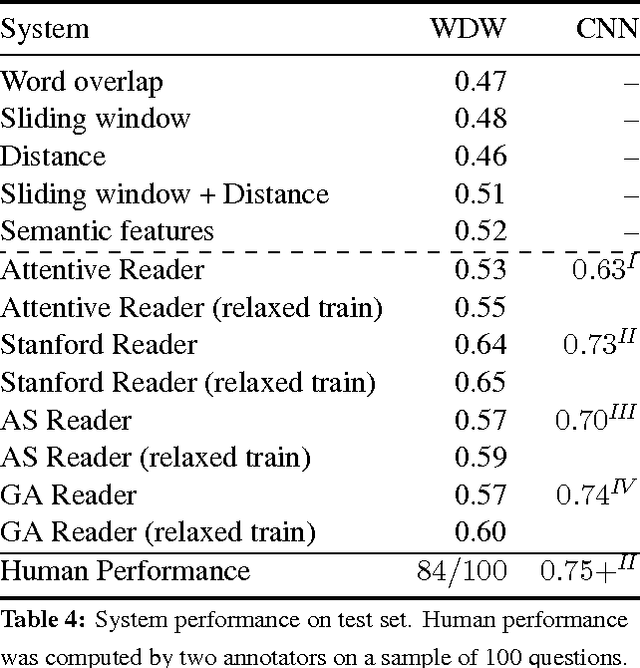
We have constructed a new "Who-did-What" dataset of over 200,000 fill-in-the-gap (cloze) multiple choice reading comprehension problems constructed from the LDC English Gigaword newswire corpus. The WDW dataset has a variety of novel features. First, in contrast with the CNN and Daily Mail datasets (Hermann et al., 2015) we avoid using article summaries for question formation. Instead, each problem is formed from two independent articles --- an article given as the passage to be read and a separate article on the same events used to form the question. Second, we avoid anonymization --- each choice is a person named entity. Third, the problems have been filtered to remove a fraction that are easily solved by simple baselines, while remaining 84% solvable by humans. We report performance benchmarks of standard systems and propose the WDW dataset as a challenge task for the community.