 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePATENTWRITER: A Benchmarking Study for Patent Drafting with LLMs
Jul 30, 2025

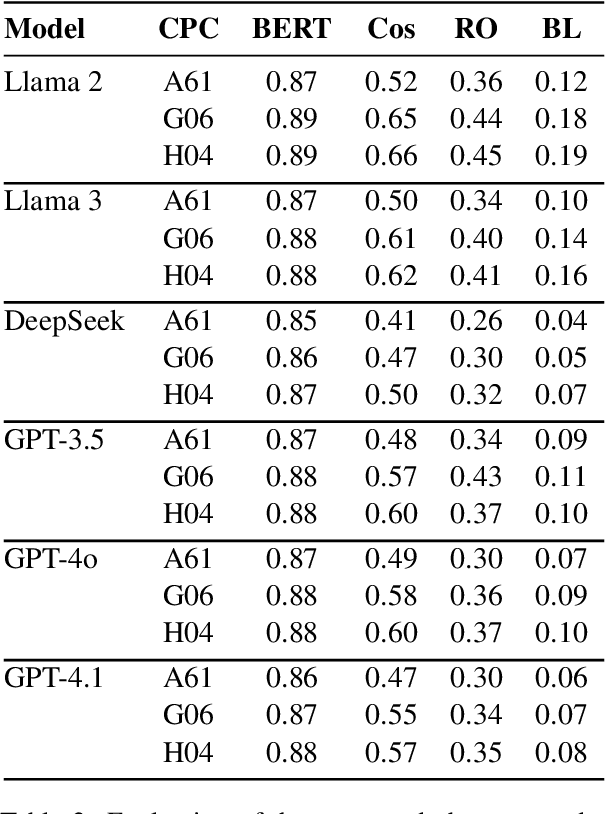
Large language models (LLMs) have emerged as transformative approaches in several important fields. This paper aims for a paradigm shift for patent writing by leveraging LLMs to overcome the tedious patent-filing process. In this work, we present PATENTWRITER, the first unified benchmarking framework for evaluating LLMs in patent abstract generation. Given the first claim of a patent, we evaluate six leading LLMs -- including GPT-4 and LLaMA-3 -- under a consistent setup spanning zero-shot, few-shot, and chain-of-thought prompting strategies to generate the abstract of the patent. Our benchmark PATENTWRITER goes beyond surface-level evaluation: we systematically assess the output quality using a comprehensive suite of metrics -- standard NLP measures (e.g., BLEU, ROUGE, BERTScore), robustness under three types of input perturbations, and applicability in two downstream patent classification and retrieval tasks. We also conduct stylistic analysis to assess length, readability, and tone. Experimental results show that modern LLMs can generate high-fidelity and stylistically appropriate patent abstracts, often surpassing domain-specific baselines. Our code and dataset are open-sourced to support reproducibility and future research.
Competing Topic Naming Conventions in Quora: Predicting Appropriate Topic Merges and Winning Topics from Millions of Topic Pairs
Sep 10, 2019



Quora is a popular Q&A site which provides users with the ability to tag questions with multiple relevant topics which helps to attract quality answers. These topics are not predefined but user-defined conventions and it is not so rare to have multiple such conventions present in the Quora ecosystem describing exactly the same concept. In almost all such cases, users (or Quora moderators) manually merge the topic pair into one of the either topics, thus selecting one of the competing conventions. An important application for the site therefore is to identify such competing conventions early enough that should merge in future. In this paper, we propose a two-step approach that uniquely combines the anomaly detection and the supervised classification frameworks to predict whether two topics from among millions of topic pairs are indeed competing conventions, and should merge, achieving an F-score of 0.711. We also develop a model to predict the direction of the topic merge, i.e., the winning convention, achieving an F-score of 0.898. Our system is also able to predict ~ 25% of the correct case of merges within the first month of the merge and ~ 40% of the cases within a year. This is an encouraging result since Quora users on average take 936 days to identify such a correct merge. Human judgment experiments show that our system is able to predict almost all the correct cases that humans can predict plus 37.24% correct cases which the humans are not able to identify at all.
Deep Dive into Anonymity: A Large Scale Analysis of Quora Questions
Nov 17, 2018
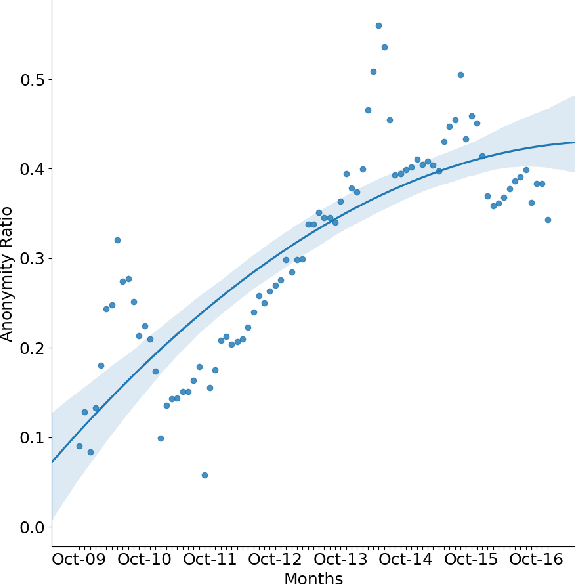
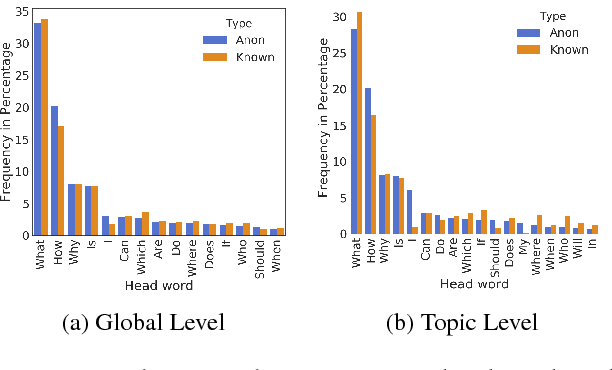
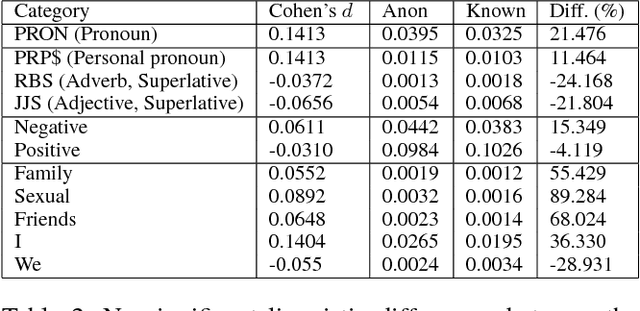
Anonymity forms an integral and important part of our digital life. It enables us to express our true selves without the fear of judgment. In this paper, we investigate the different aspects of anonymity in the social Q&A site Quora. The choice of Quora is motivated by the fact that this is one of the rare social Q&A sites that allow users to explicitly post anonymous questions and such activity in this forum has become normative rather than a taboo. Through an analysis of 5.1 million questions, we observe that at a global scale almost no difference manifests between the linguistic structure of the anonymous and the non-anonymous questions. We find that topical mixing at the global scale to be the primary reason for the absence. However, the differences start to feature once we "deep dive" and (topically) cluster the questions and compare the clusters that have high volumes of anonymous questions with those that have low volumes of anonymous questions. In particular, we observe that the choice to post the question as anonymous is dependent on the user's perception of anonymity and they often choose to speak about depression, anxiety, social ties and personal issues under the guise of anonymity. We further perform personality trait analysis and observe that the anonymous group of users has positive correlation with extraversion, agreeableness, and negative correlation with openness. Subsequently, to gain further insights, we build an anonymity grid to identify the differences in the perception on anonymity of the user posting the question and the community of users answering it. We also look into the first response time of the questions and observe that it is lowest for topics which talk about personal and sensitive issues, which hints toward a higher degree of community support and user engagement.
Adapting predominant and novel sense discovery algorithms for identifying corpus-specific sense differences
Feb 01, 2018


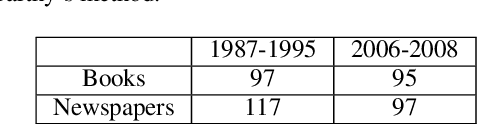
Word senses are not static and may have temporal, spatial or corpus-specific scopes. Identifying such scopes might benefit the existing WSD systems largely. In this paper, while studying corpus specific word senses, we adapt three existing predominant and novel-sense discovery algorithms to identify these corpus-specific senses. We make use of text data available in the form of millions of digitized books and newspaper archives as two different sources of corpora and propose automated methods to identify corpus-specific word senses at various time points. We conduct an extensive and thorough human judgment experiment to rigorously evaluate and compare the performance of these approaches. Post adaptation, the output of the three algorithms are in the same format and the accuracy results are also comparable, with roughly 45-60% of the reported corpus-specific senses being judged as genuine.
ENWalk: Learning Network Features for Spam Detection in Twitter
Apr 11, 2017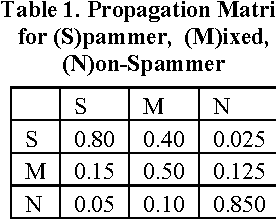
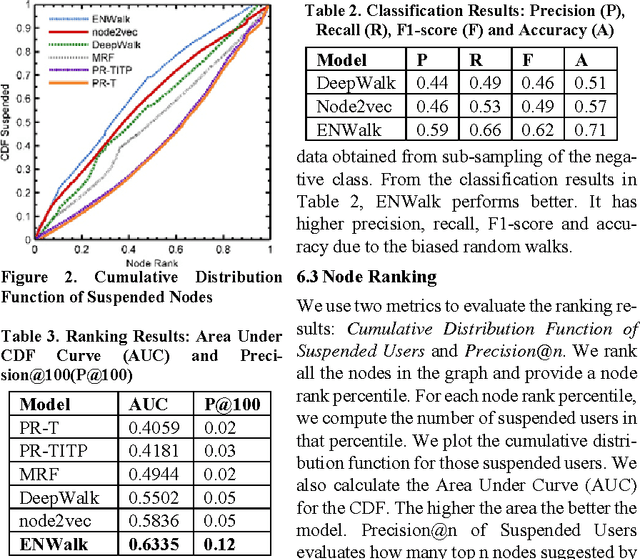
Social medias are increasing their influence with the vast public information leading to their active use for marketing by the companies and organizations. Such marketing promotions are difficult to identify unlike the traditional medias like TV and newspaper. So, it is very much important to identify the promoters in the social media. Although, there are active ongoing researches, existing approaches are far from solving the problem. To identify such imposters, it is very much important to understand their strategies of social circle creation and dynamics of content posting. Are there any specific spammer types? How successful are each types? We analyze these questions in the light of social relationships in Twitter. Our analyses discover two types of spammers and their relationships with the dynamics of content posts. Our results discover novel dynamics of spamming which are intuitive and arguable. We propose ENWalk, a framework to detect the spammers by learning the feature representations of the users in the social media. We learn the feature representations using the random walks biased on the spam dynamics. Experimental results on large-scale twitter network and the corresponding tweets show the effectiveness of our approach that outperforms the existing approaches
Language Use Matters: Analysis of the Linguistic Structure of Question Texts Can Characterize Answerability in Quora
Mar 11, 2017



Quora is one of the most popular community Q&A sites of recent times. However, many question posts on this Q&A site often do not get answered. In this paper, we quantify various linguistic activities that discriminates an answered question from an unanswered one. Our central finding is that the way users use language while writing the question text can be a very effective means to characterize answerability. This characterization helps us to predict early if a question remaining unanswered for a specific time period t will eventually be answered or not and achieve an accuracy of 76.26% (t = 1 month) and 68.33% (t = 3 months). Notably, features representing the language use patterns of the users are most discriminative and alone account for an accuracy of 74.18%. We also compare our method with some of the similar works (Dror et al., Yang et al.) achieving a maximum improvement of ~39% in terms of accuracy.
WASSUP? LOL : Characterizing Out-of-Vocabulary Words in Twitter
Jan 31, 2016Language in social media is mostly driven by new words and spellings that are constantly entering the lexicon thereby polluting it and resulting in high deviation from the formal written version. The primary entities of such language are the out-of-vocabulary (OOV) words. In this paper, we study various sociolinguistic properties of the OOV words and propose a classification model to categorize them into at least six categories. We achieve 81.26% accuracy with high precision and recall. We observe that the content features are the most discriminative ones followed by lexical and context features.