 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Personal Traits from Facial Images using Convolutional Neural Networks Augmented with Facial Landmark Information
May 29, 2016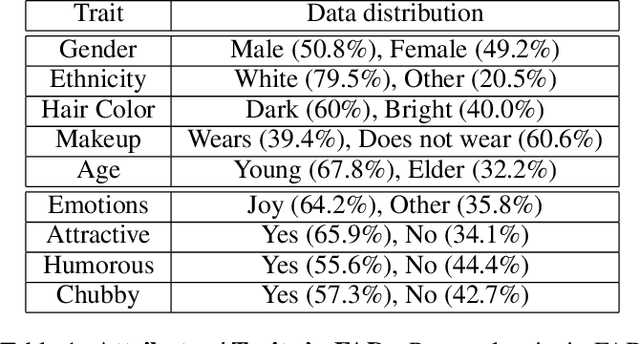
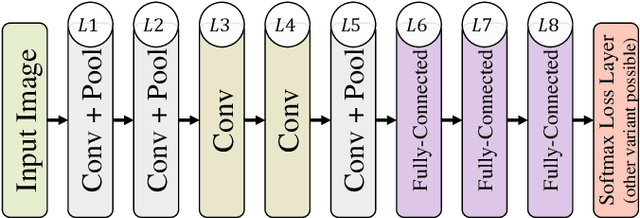
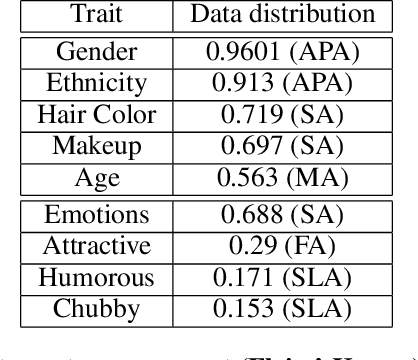

We consider the task of predicting various traits of a person given an image of their face. We estimate both objective traits, such as gender, ethnicity and hair-color; as well as subjective traits, such as the emotion a person expresses or whether he is humorous or attractive. For sizeable experimentation, we contribute a new Face Attributes Dataset (FAD), having roughly 200,000 attribute labels for the above traits, for over 10,000 facial images. Due to the recent surge of research on Deep Convolutional Neural Networks (CNNs), we begin by using a CNN architecture for estimating facial attributes and show that they indeed provide an impressive baseline performance. To further improve performance, we propose a novel approach that incorporates facial landmark information for input images as an additional channel, helping the CNN learn better attribute-specific features so that the landmarks across various training images hold correspondence. We empirically analyse the performance of our method, showing consistent improvement over the baseline across traits.
Refining Architectures of Deep Convolutional Neural Networks
Apr 22, 2016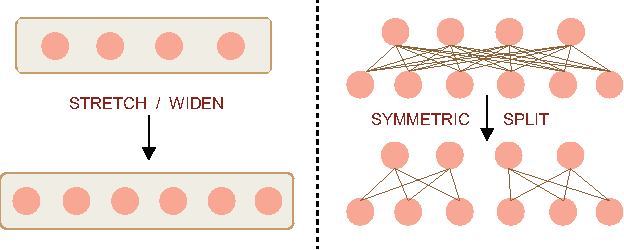
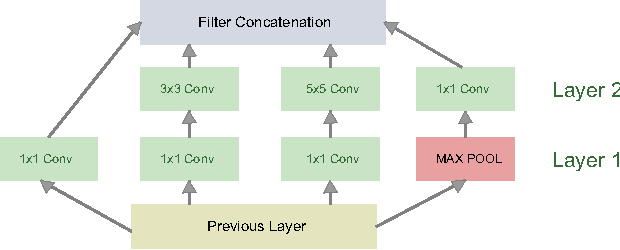

Deep Convolutional Neural Networks (CNNs) have recently evinced immense success for various image recognition tasks. However, a question of paramount importance is somewhat unanswered in deep learning research - is the selected CNN optimal for the dataset in terms of accuracy and model size? In this paper, we intend to answer this question and introduce a novel strategy that alters the architecture of a given CNN for a specified dataset, to potentially enhance the original accuracy while possibly reducing the model size. We use two operations for architecture refinement, viz. stretching and symmetrical splitting. Our procedure starts with a pre-trained CNN for a given dataset, and optimally decides the stretch and split factors across the network to refine the architecture. We empirically demonstrate the necessity of the two operations. We evaluate our approach on two natural scenes attributes datasets, SUN Attributes and CAMIT-NSAD, with architectures of GoogleNet and VGG-11, that are quite contrasting in their construction. We justify our choice of datasets, and show that they are interestingly distinct from each other, and together pose a challenge to our architectural refinement algorithm. Our results substantiate the usefulness of the proposed method.
DEEP-CARVING: Discovering Visual Attributes by Carving Deep Neural Nets
Apr 19, 2015

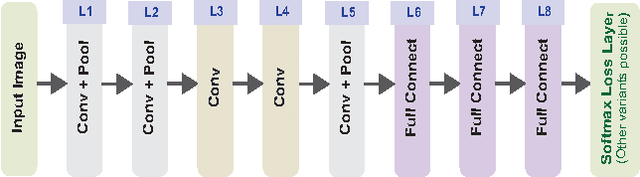

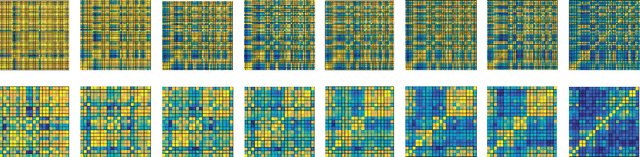
Most of the approaches for discovering visual attributes in images demand significant supervision, which is cumbersome to obtain. In this paper, we aim to discover visual attributes in a weakly supervised setting that is commonly encountered with contemporary image search engines. Deep Convolutional Neural Networks (CNNs) have enjoyed remarkable success in vision applications recently. However, in a weakly supervised scenario, widely used CNN training procedures do not learn a robust model for predicting multiple attribute labels simultaneously. The primary reason is that the attributes highly co-occur within the training data. To ameliorate this limitation, we propose Deep-Carving, a novel training procedure with CNNs, that helps the net efficiently carve itself for the task of multiple attribute prediction. During training, the responses of the feature maps are exploited in an ingenious way to provide the net with multiple pseudo-labels (for training images) for subsequent iterations. The process is repeated periodically after a fixed number of iterations, and enables the net carve itself iteratively for efficiently disentangling features. Additionally, we contribute a noun-adjective pairing inspired Natural Scenes Attributes Dataset to the research community, CAMIT - NSAD, containing a number of co-occurring attributes within a noun category. We describe, in detail, salient aspects of this dataset. Our experiments on CAMIT-NSAD and the SUN Attributes Dataset, with weak supervision, clearly demonstrate that the Deep-Carved CNNs consistently achieve considerable improvement in the precision of attribute prediction over popular baseline methods.