 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-vocabulary Audio-visual Speech Recognition in Noisy Environments
Sep 10, 2021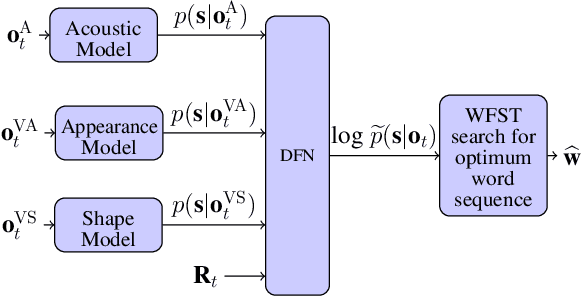
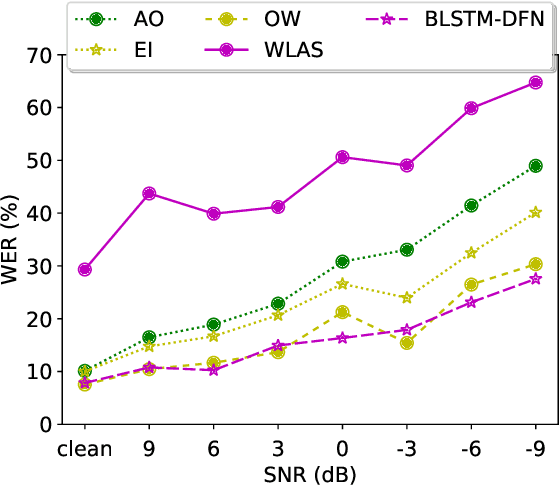

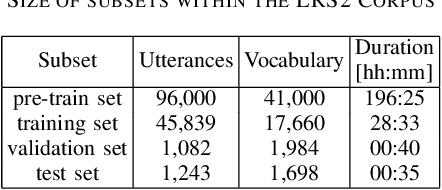
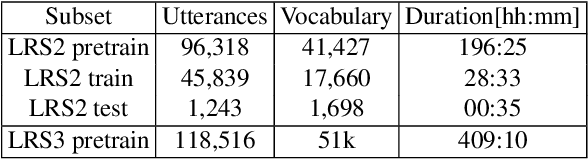
Audio-visual speech recognition (AVSR) can effectively and significantly improve the recognition rates of small-vocabulary systems, compared to their audio-only counterparts. For large-vocabulary systems, however, there are still many difficulties, such as unsatisfactory video recognition accuracies, that make it hard to improve over audio-only baselines. In this paper, we specifically consider such scenarios, focusing on the large-vocabulary task of the LRS2 database, where audio-only performance is far superior to video-only accuracies, making this an interesting and challenging setup for multi-modal integration. To address the inherent difficulties, we propose a new fusion strategy: a recurrent integration network is trained to fuse the state posteriors of multiple single-modality models, guided by a set of model-based and signal-based stream reliability measures. During decoding, this network is used for stream integration within a hybrid recognizer, where it can thus cope with the time-variant reliability and information content of its multiple feature inputs. We compare the results with end-to-end AVSR systems as well as with competitive hybrid baseline models, finding that the new fusion strategy shows superior results, on average even outperforming oracle dynamic stream weighting, which has so far marked the -- realistically unachievable -- upper bound for standard stream weighting. Even though the pure lipreading performance is low, audio-visual integration is helpful under all -- clean, noisy, and reverberant -- conditions. On average, the new system achieves a relative word error rate reduction of 42.18\% compared to the audio-only model, pointing at a high effectiveness of the proposed integration approach.
Fusing information streams in end-to-end audio-visual speech recognition
Apr 19, 2021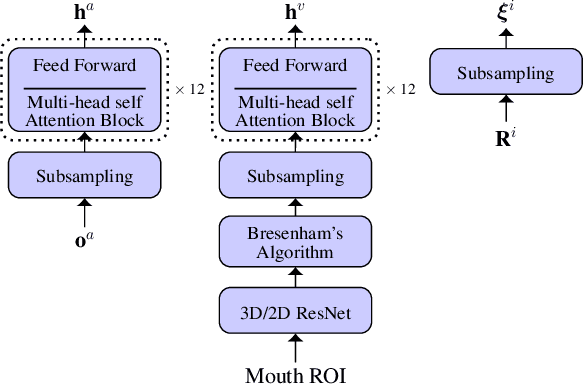
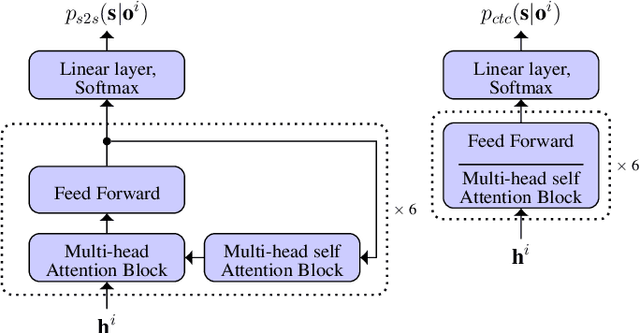
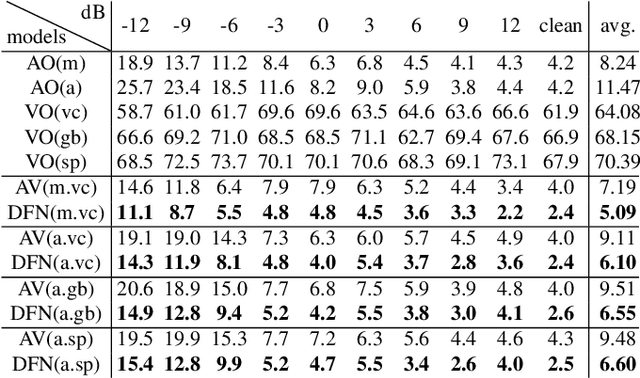
End-to-end acoustic speech recognition has quickly gained widespread popularity and shows promising results in many studies. Specifically the joint transformer/CTC model provides very good performance in many tasks. However, under noisy and distorted conditions, the performance still degrades notably. While audio-visual speech recognition can significantly improve the recognition rate of end-to-end models in such poor conditions, it is not obvious how to best utilize any available information on acoustic and visual signal quality and reliability in these models. We thus consider the question of how to optimally inform the transformer/CTC model of any time-variant reliability of the acoustic and visual information streams. We propose a new fusion strategy, incorporating reliability information in a decision fusion net that considers the temporal effects of the attention mechanism. This approach yields significant improvements compared to a state-of-the-art baseline model on the Lip Reading Sentences 2 and 3 (LRS2 and LRS3) corpus. On average, the new system achieves a relative word error rate reduction of 43% compared to the audio-only setup and 31% compared to the audiovisual end-to-end baseline.
* 5 pages
Unsupervised Classification of Voiced Speech and Pitch Tracking Using Forward-Backward Kalman Filtering
Mar 01, 2021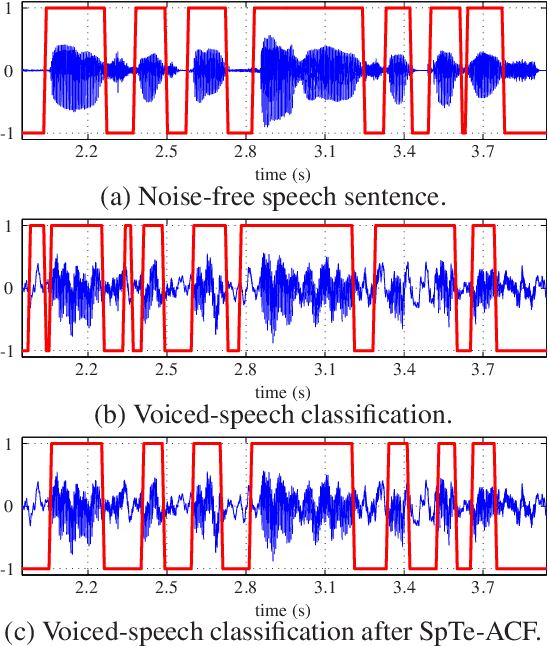
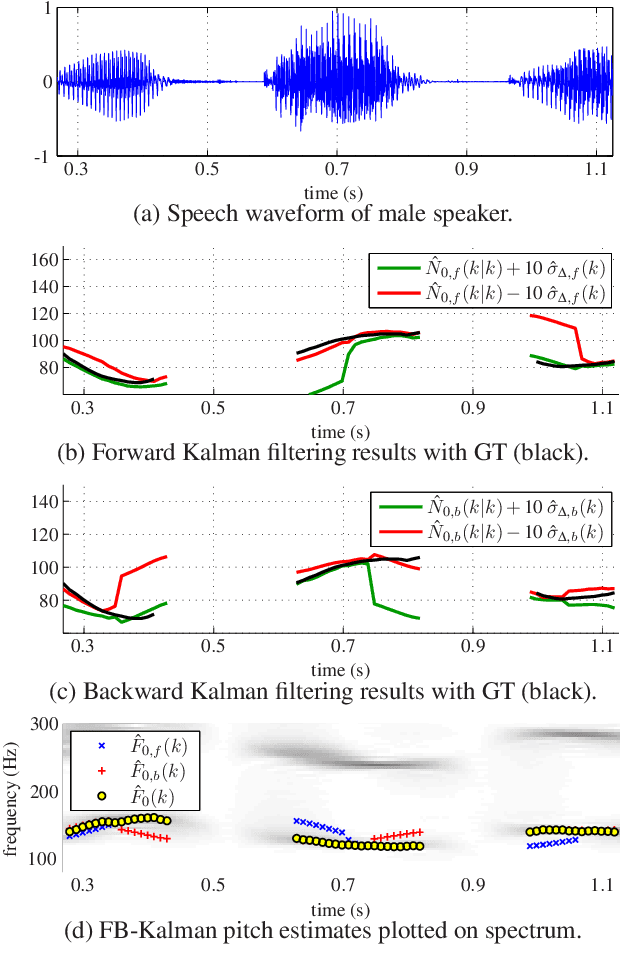
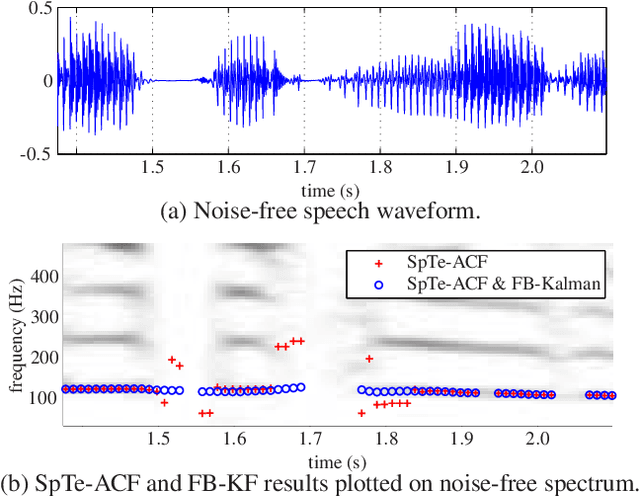
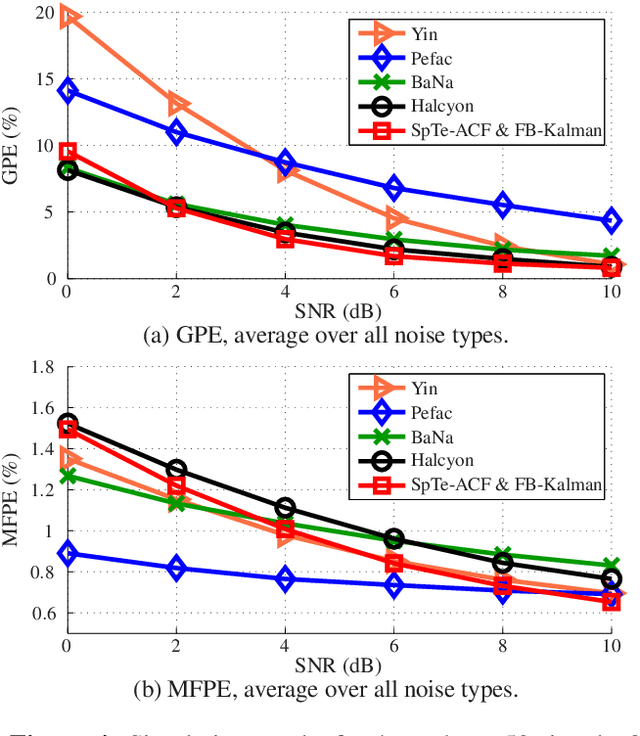
The detection of voiced speech, the estimation of the fundamental frequency, and the tracking of pitch values over time are crucial subtasks for a variety of speech processing techniques. Many different algorithms have been developed for each of the three subtasks. We present a new algorithm that integrates the three subtasks into a single procedure. The algorithm can be applied to pre-recorded speech utterances in the presence of considerable amounts of background noise. We combine a collection of standard metrics, such as the zero-crossing rate, for example, to formulate an unsupervised voicing classifier. The estimation of pitch values is accomplished with a hybrid autocorrelation-based technique. We propose a forward-backward Kalman filter to smooth the estimated pitch contour. In experiments, we are able to show that the proposed method compares favorably with current, state-of-the-art pitch detection algorithms.
Variational Autoencoder with Embedded Student-$t$ Mixture Model for Authorship Attribution
May 28, 2020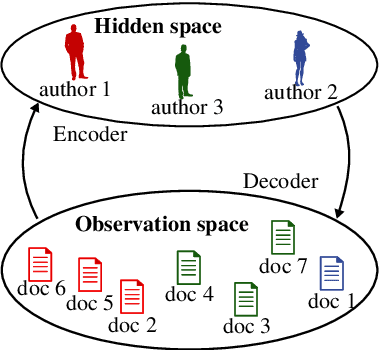
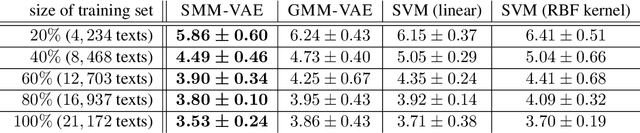
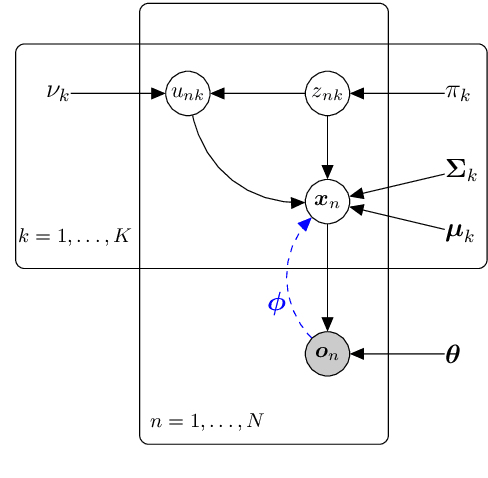
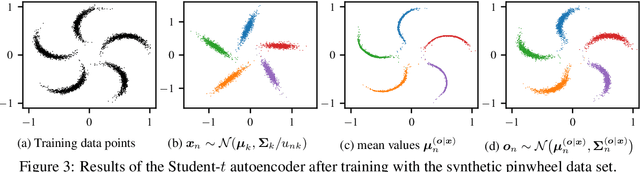
Traditional computational authorship attribution describes a classification task in a closed-set scenario. Given a finite set of candidate authors and corresponding labeled texts, the objective is to determine which of the authors has written another set of anonymous or disputed texts. In this work, we propose a probabilistic autoencoding framework to deal with this supervised classification task. More precisely, we are extending a variational autoencoder (VAE) with embedded Gaussian mixture model to a Student-$t$ mixture model. Autoencoders have had tremendous success in learning latent representations. However, existing VAEs are currently still bound by limitations imposed by the assumed Gaussianity of the underlying probability distributions in the latent space. In this work, we are extending the Gaussian model for the VAE to a Student-$t$ model, which allows for an independent control of the "heaviness" of the respective tails of the implied probability densities. Experiments over an Amazon review dataset indicate superior performance of the proposed method.
Imperio: Robust Over-the-Air Adversarial Examples for Automatic Speech Recognition Systems
Sep 09, 2019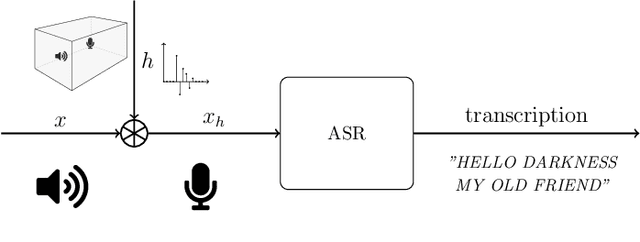
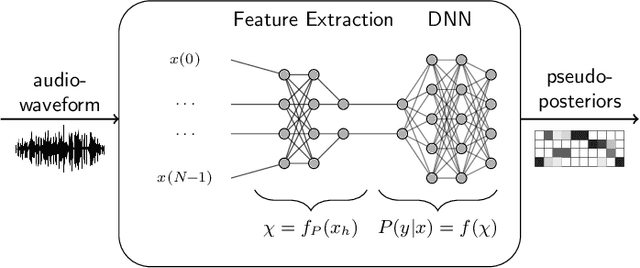

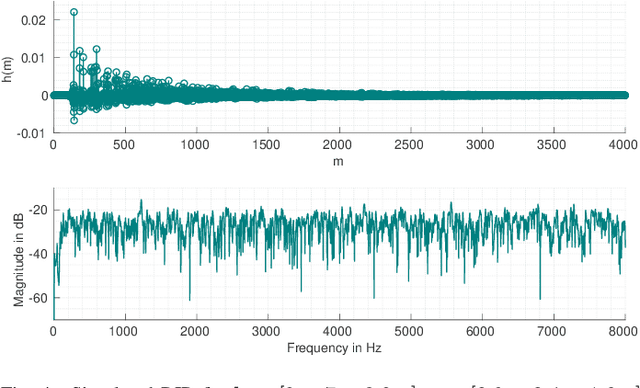
Automatic speech recognition (ASR) systems are possible to fool via targeted adversarial examples. These can induce the ASR to produce arbitrary transcriptions in response to any type of audio signal, be it speech, environmental sounds, or music. However, in general, those adversarial examples did not work in a real-world setup, where the examples are played over the air but have to be fed into the ASR system directly. In some cases, where the adversarial examples could be successfully played over the air, the attacks require precise information about the room where the attack takes place in order to tailor the adversarial examples to a specific setup and are not transferable to other rooms. Other attacks, which are robust in an over-the-air attack, are either handcrafted examples or human listeners can easily recognize the target transcription, once they have been alerted to its content. In this paper, we demonstrate the first generic algorithm that produces adversarial examples which remain robust in an over-the-air attack such that the ASR system transcribes the target transcription after actually being replayed. For the proposed algorithm, guessing a rough approximation of the room characteristics is enough and no actual access to the room is required. We use the ASR system Kaldi to demonstrate the attack and employ a room-impulse-response simulator to harden the adversarial examples against varying room characteristics. Further, the algorithm can also utilize psychoacoustics to hide changes of the original audio signal below the human thresholds of hearing. We show that the adversarial examples work for varying room setups, but also can be tailored to specific room setups. As a result, an attacker can optimize adversarial examples for any target transcription and to arbitrary rooms. Additionally, the adversarial examples remain transferable to varying rooms with a high probability.
Similarity Learning for Authorship Verification in Social Media
Aug 20, 2019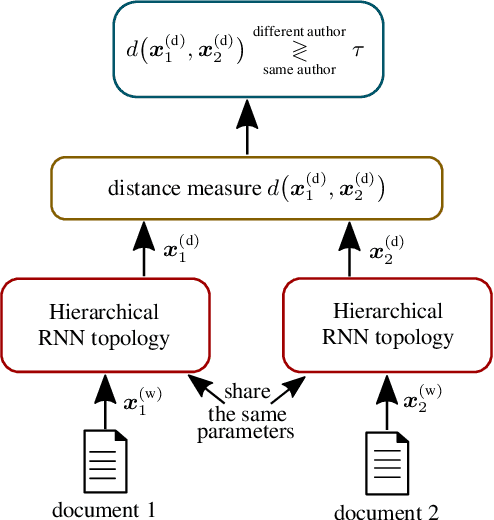
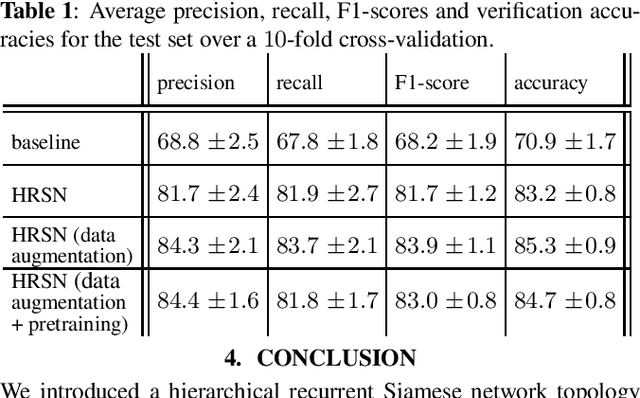
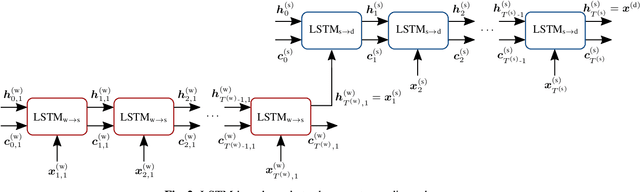
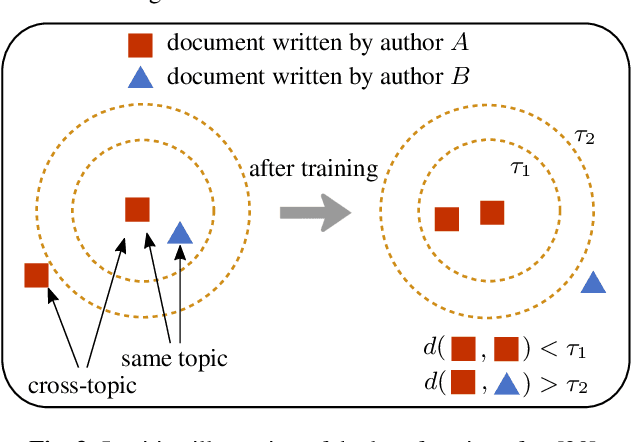
Authorship verification tries to answer the question if two documents with unknown authors were written by the same author or not. A range of successful technical approaches has been proposed for this task, many of which are based on traditional linguistic features such as n-grams. These algorithms achieve good results for certain types of written documents like books and novels. Forensic authorship verification for social media, however, is a much more challenging task since messages tend to be relatively short, with a large variety of different genres and topics. At this point, traditional methods based on features like n-grams have had limited success. In this work, we propose a new neural network topology for similarity learning that significantly improves the performance on the author verification task with such challenging data sets.