 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-vocabulary Audio-visual Speech Recognition in Noisy Environments
Paper and Code
Sep 10, 2021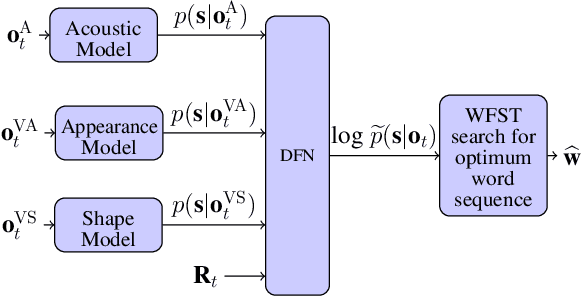
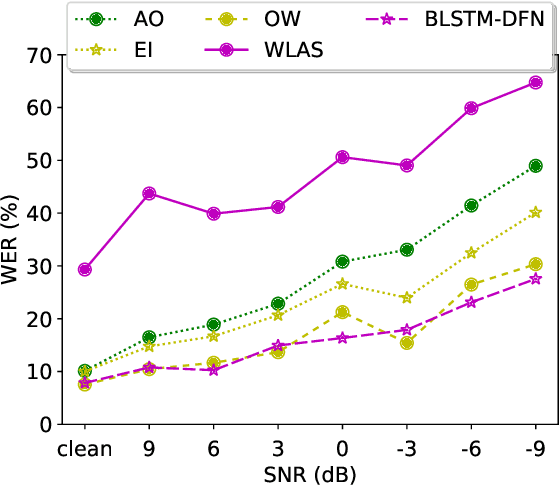

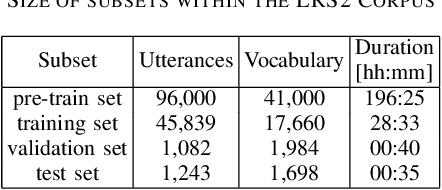
Audio-visual speech recognition (AVSR) can effectively and significantly improve the recognition rates of small-vocabulary systems, compared to their audio-only counterparts. For large-vocabulary systems, however, there are still many difficulties, such as unsatisfactory video recognition accuracies, that make it hard to improve over audio-only baselines. In this paper, we specifically consider such scenarios, focusing on the large-vocabulary task of the LRS2 database, where audio-only performance is far superior to video-only accuracies, making this an interesting and challenging setup for multi-modal integration. To address the inherent difficulties, we propose a new fusion strategy: a recurrent integration network is trained to fuse the state posteriors of multiple single-modality models, guided by a set of model-based and signal-based stream reliability measures. During decoding, this network is used for stream integration within a hybrid recognizer, where it can thus cope with the time-variant reliability and information content of its multiple feature inputs. We compare the results with end-to-end AVSR systems as well as with competitive hybrid baseline models, finding that the new fusion strategy shows superior results, on average even outperforming oracle dynamic stream weighting, which has so far marked the -- realistically unachievable -- upper bound for standard stream weighting. Even though the pure lipreading performance is low, audio-visual integration is helpful under all -- clean, noisy, and reverberant -- conditions. On average, the new system achieves a relative word error rate reduction of 42.18\% compared to the audio-only model, pointing at a high effectiveness of the proposed integration approach.