 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperio: Robust Over-the-Air Adversarial Examples for Automatic Speech Recognition Systems
Paper and Code
Sep 09, 2019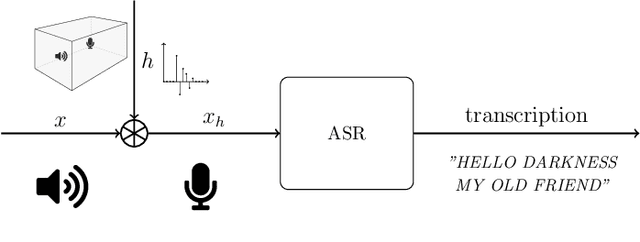
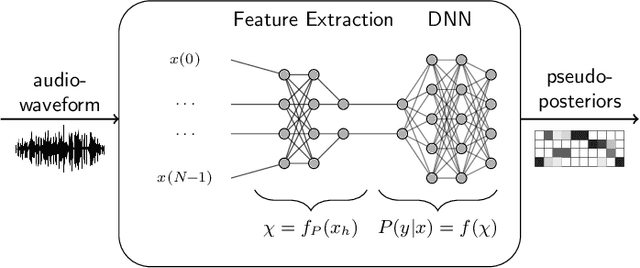

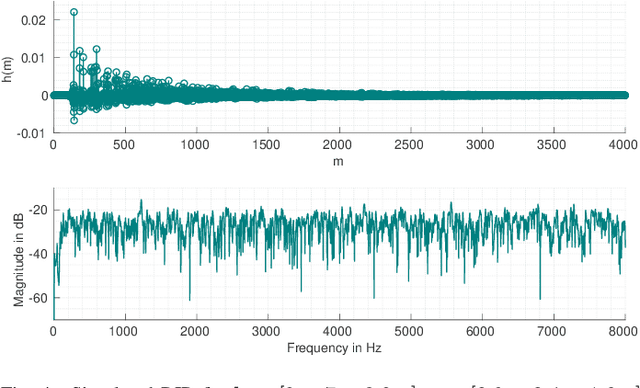
Automatic speech recognition (ASR) systems are possible to fool via targeted adversarial examples. These can induce the ASR to produce arbitrary transcriptions in response to any type of audio signal, be it speech, environmental sounds, or music. However, in general, those adversarial examples did not work in a real-world setup, where the examples are played over the air but have to be fed into the ASR system directly. In some cases, where the adversarial examples could be successfully played over the air, the attacks require precise information about the room where the attack takes place in order to tailor the adversarial examples to a specific setup and are not transferable to other rooms. Other attacks, which are robust in an over-the-air attack, are either handcrafted examples or human listeners can easily recognize the target transcription, once they have been alerted to its content. In this paper, we demonstrate the first generic algorithm that produces adversarial examples which remain robust in an over-the-air attack such that the ASR system transcribes the target transcription after actually being replayed. For the proposed algorithm, guessing a rough approximation of the room characteristics is enough and no actual access to the room is required. We use the ASR system Kaldi to demonstrate the attack and employ a room-impulse-response simulator to harden the adversarial examples against varying room characteristics. Further, the algorithm can also utilize psychoacoustics to hide changes of the original audio signal below the human thresholds of hearing. We show that the adversarial examples work for varying room setups, but also can be tailored to specific room setups. As a result, an attacker can optimize adversarial examples for any target transcription and to arbitrary rooms. Additionally, the adversarial examples remain transferable to varying rooms with a high probability.