 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment among Language, Vision and Action Representations
Jan 30, 2026A fundamental question in cognitive science and AI concerns whether different learning modalities: language, vision, and action, give rise to distinct or shared internal representations. Traditional views assume that models trained on different data types develop specialized, non-transferable representations. However, recent evidence suggests unexpected convergence: models optimized for distinct tasks may develop similar representational geometries. We investigate whether this convergence extends to embodied action learning by training a transformer-based agent to execute goal-directed behaviors in response to natural language instructions. Using behavioral cloning on the BabyAI platform, we generated action-grounded language embeddings shaped exclusively by sensorimotor control requirements. We then compared these representations with those extracted from state-of-the-art large language models (LLaMA, Qwen, DeepSeek, BERT) and vision-language models (CLIP, BLIP). Despite substantial differences in training data, modality, and objectives, we observed robust cross-modal alignment. Action representations aligned strongly with decoder-only language models and BLIP (precision@15: 0.70-0.73), approaching the alignment observed among language models themselves. Alignment with CLIP and BERT was significantly weaker. These findings indicate that linguistic, visual, and action representations converge toward partially shared semantic structures, supporting modality-independent semantic organization and highlighting potential for cross-domain transfer in embodied AI systems.
LLMs for sensory-motor control: Combining in-context and iterative learning
Jun 05, 2025We propose a method that enables large language models (LLMs) to control embodied agents by directly mapping continuous observation vectors to continuous action vectors. Initially, the LLMs generate a control strategy based on a textual description of the agent, its environment, and the intended goal. This strategy is then iteratively refined through a learning process in which the LLMs are repeatedly prompted to improve the current strategy, using performance feedback and sensory-motor data collected during its evaluation. The method is validated on classic control tasks from the Gymnasium library and the inverted pendulum task from the MuJoCo library. In most cases, it successfully identifies optimal or high-performing solutions by integrating symbolic knowledge derived through reasoning with sub-symbolic sensory-motor data gathered as the agent interacts with its environment.
On the Unexpected Abilities of Large Language Models
Aug 09, 2023Large language models are capable of displaying a wide range of abilities that are not directly connected with the task for which they are trained: predicting the next words of human-written texts. In this article, I discuss the nature of this indirect acquisition process and its relation to other known indirect processes. I argue that an important side effect of such indirect acquisition is the development of integrated abilities. I discuss the extent to which the abilities developed by large language models are predictable. Finally, I briefly discuss the relation between the cognitive skills acquired by these systems and human cognition.
The Role of Environmental Variations in Evolutionary Robotics: Maximizing Performance and Robustness
Aug 04, 2022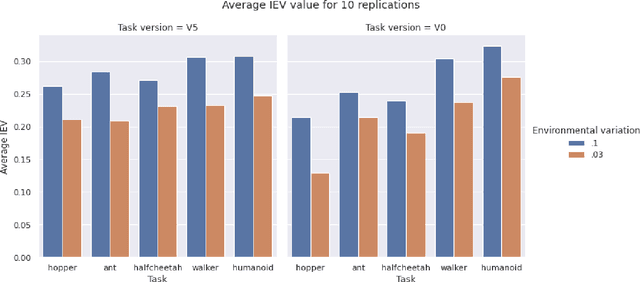
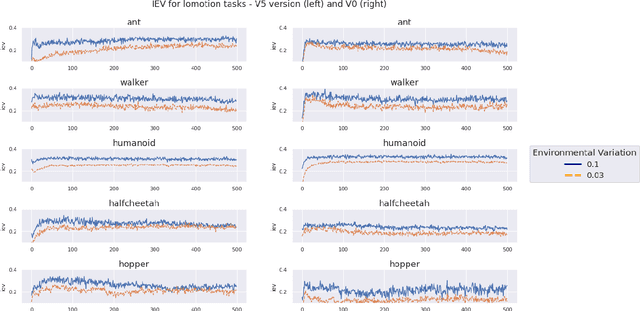
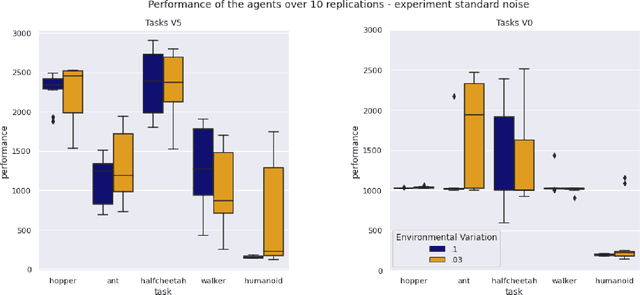
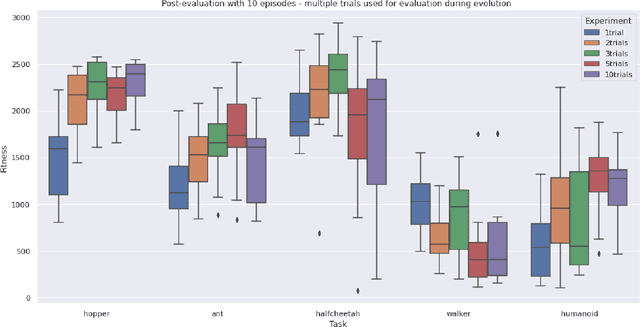
Exposing evolving robots to variable conditions is necessary to obtain solutions which are robust to environmental variations and which can cross the reality gap. However, we do not yet have methods for analyzing and understanding the impact of environmental variations on the evolutionary process, and therefore for choosing suitable variation ranges. In this article we introduce a method that permits us to measure the impact of environmental variations and we analyze the relation between the amplitude of variations, the modality with which they are introduced, and the performance and robustness of evolving agents. Our results demonstrate that (i) the evolutionary algorithm can tolerate environmental variations which have a very high impact, (ii) variations affecting the actions of the agent are tolerated much better than variations affecting the initial state of the agent or of the environment, and (iii) improving the accuracy of the fitness measure through multiple evaluations is not always useful. Moreover, our results show that environmental variations permit generating solutions which perform better both in varying and non-varying environments.
Qualitative Differences Between Evolutionary Strategies and Reinforcement Learning Methods for Control of Autonomous Agents
May 16, 2022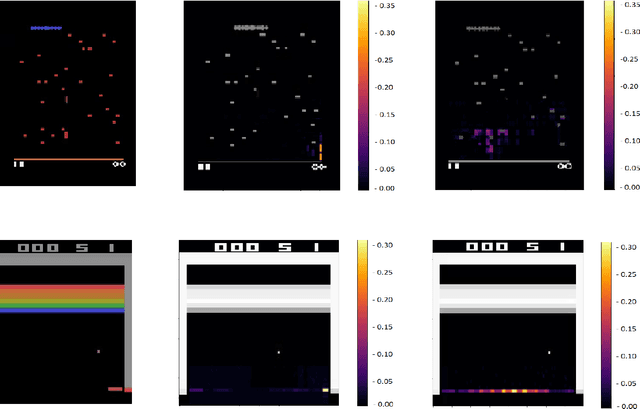
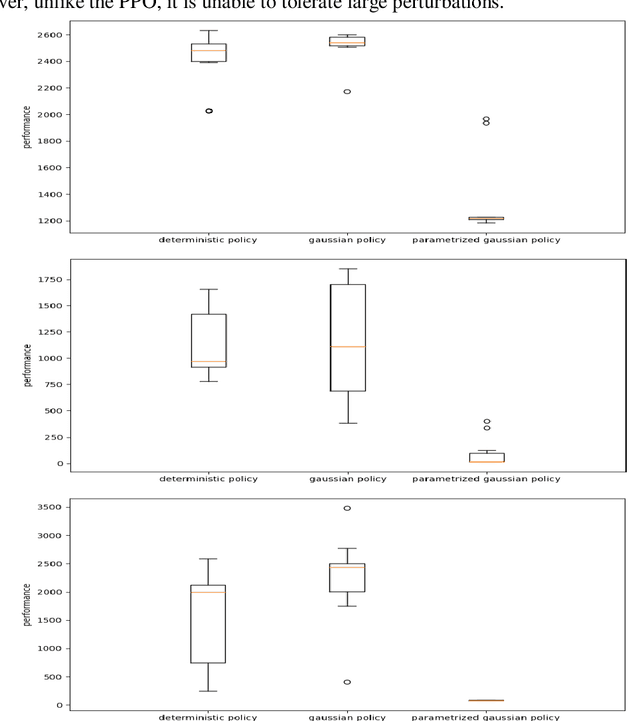
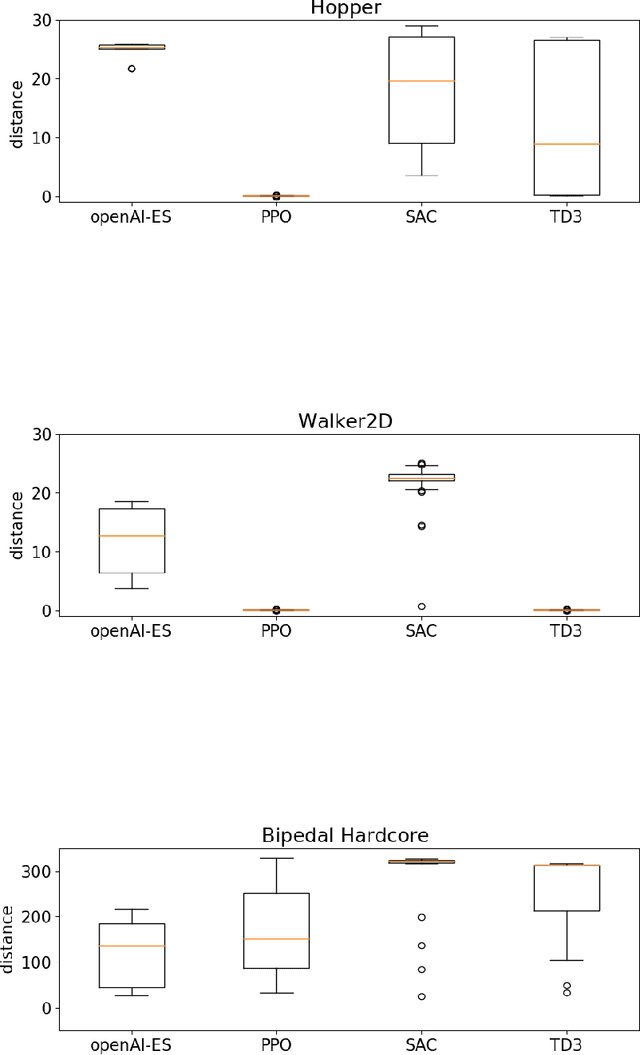
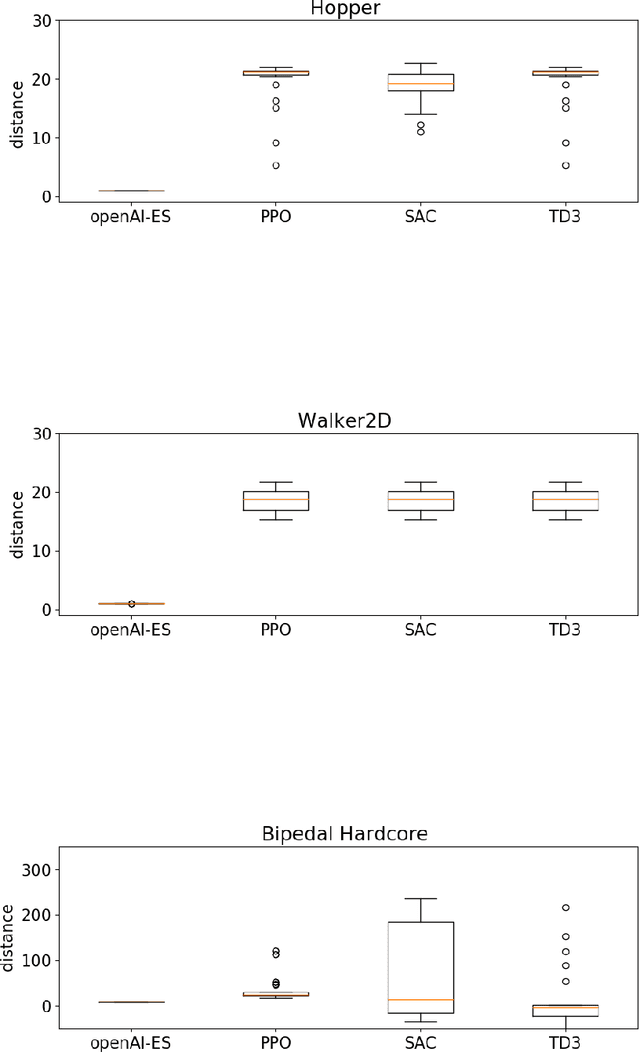
In this paper we analyze the qualitative differences between evolutionary strategies and reinforcement learning algorithms by focusing on two popular state-of-the-art algorithms: the OpenAI-ES evolutionary strategy and the Proximal Policy Optimization (PPO) reinforcement learning algorithm -- the most similar methods of the two families. We analyze how the methods differ with respect to: (i) general efficacy, (ii) ability to cope with sparse rewards, (iii) propensity/capacity to discover minimal solutions, (iv) dependency on reward shaping, and (v) ability to cope with variations of the environmental conditions. The analysis of the performance and of the behavioral strategies displayed by the agents trained with the two methods on benchmark problems enable us to demonstrate qualitative differences which were not identified in previous studies, to identify the relative weakness of the two methods, and to propose ways to ameliorate some of those weakness. We show that the characteristics of the reward function has a strong impact which vary qualitatively not only for the OpenAI-ES and the PPO but also for alternative reinforcement learning algorithms, thus demonstrating the importance of optimizing the characteristic of the reward function to the algorithm used.
Automated Curriculum Learning for Embodied Agents: A Neuroevolutionary Approach
Feb 17, 2021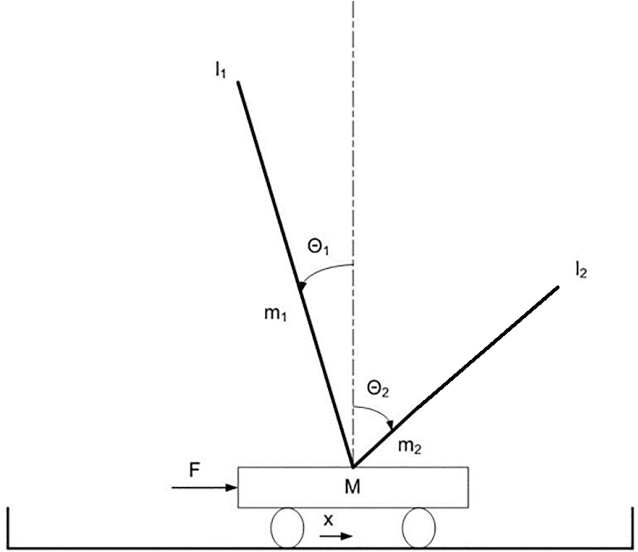



We demonstrate how an evolutionary algorithm can be extended with a curriculum learning process that selects automatically the environmental conditions in which the evolving agents are evaluated. The environmental conditions are selected so to adjust the level of difficulty to the ability level of the current evolving agents and so to challenge the weaknesses of the evolving agents. The method does not require domain knowledge and does not introduce additional hyperparameters. The results collected on two benchmark problems, that require to solve a task in significantly varying environmental conditions, demonstrate that the method proposed outperforms conventional algorithms and generates solutions that are robust to variations
The Dynamic of Body and Brain Co-Evolution
Nov 23, 2020



We introduce a method that permits to co-evolve the body and the control properties of robots. It can be used to adapt the morphological traits of robots with a hand-designed morphological bauplan or to evolve the morphological bauplan as well. Our results indicate that robots with co-adapted body and control traits outperform robots with fixed hand-designed morphologies. Interestingly, the advantage is not due to the selection of better morphologies but rather to the mutual scaffolding process that results from the possibility to co-adapt the morphological traits to the control traits and vice versa. Our results also demonstrate that morphological variations do not necessarily have destructive effects on robot skills.
Autonomous Learning of Features for Control: Experiments with Embodied and Situated Agents
Sep 15, 2020
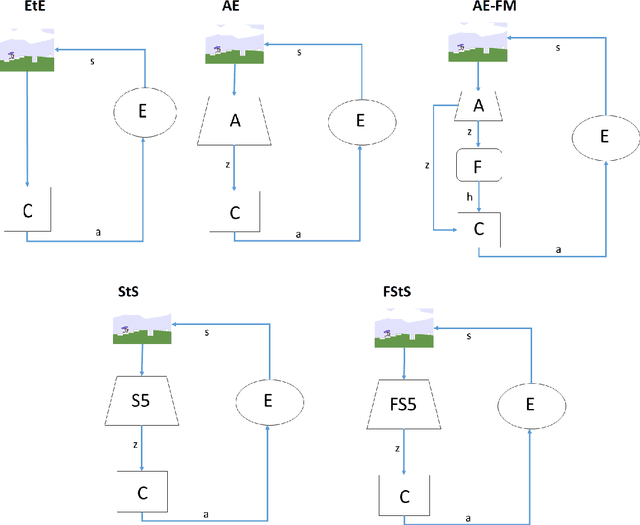
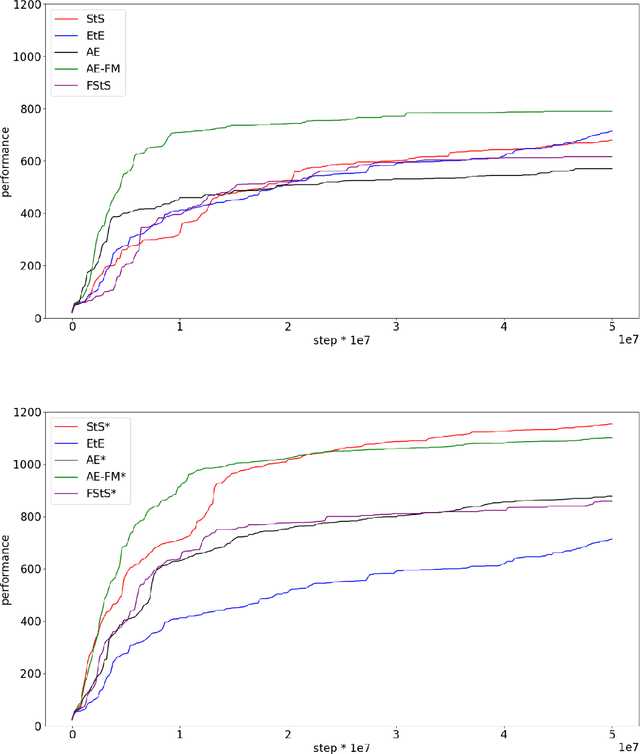
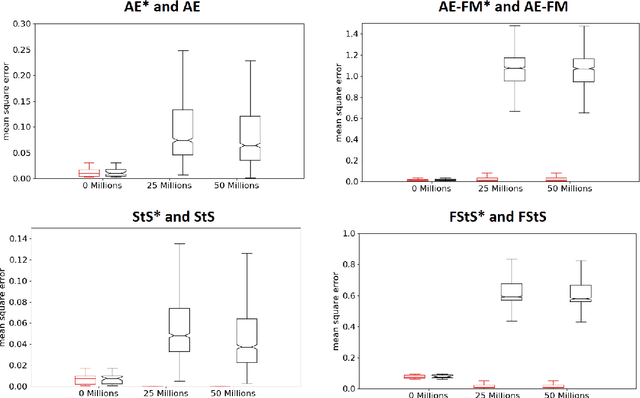
As discussed in previous studies, the efficacy of evolutionary or reinforcement learning algorithms for continuous control optimization can be enhanced by including a neural module dedicated to feature extraction trained through self-supervised methods. In this paper we report additional experiments supporting this hypothesis and we demonstrate how the advantage provided by feature extraction is not limited to problems that benefit from dimensionality reduction or that involve agents operating on the basis of allocentric perception. We introduce a method that permits to continue the training of the feature-extraction module during the training of the policy network and that increases the efficacy of feature extraction. Finally, we compare alternative feature-extracting methods and we show that sequence-to-sequence learning yields better results than the methods considered in previous studies.
Efficacy of Modern Neuro-Evolutionary Strategies for Continuous Control Optimization
Dec 11, 2019



We analyze the efficacy of modern neuro-evolutionary strategies for continuous control optimization. Overall the results collected on a wide variety of qualitatively different benchmark problems indicate that these methods are generally effective and scale well with respect to the number of parameters and the complexity of the problem. We demonstrate the importance of using suitable fitness functions or reward criteria since functions that are optimal for reinforcement learning algorithms tend to be sub-optimal for evolutionary strategies and vice versa. Finally, we provide an analysis of the role of hyper-parameters that demonstrates the importance of normalization techniques, especially in complex problems.
Long-Term Progress and Behavior Complexification in Competitive Co-Evolution
Sep 18, 2019



The possibility to use competitive evolutionary algorithms to generate long-term progress is normally prevented by the convergence on limit cycle dynamics in which the evolving agents keep progressing against their current competitors by periodically rediscovering solutions adopted previously over and over again. This leads to local but not to global progress, i.e. progress against all possible competitors. We propose a new competitive algorithm capable of leading to long term global progress thanks to its ability to identify and filter out opportunistic variations, i.e. variations leading to progress against current competitors and retrogression against other competitors. The efficacy of the method is validated on the co-evolution of predator and prey robots, a classic scenario that has been used in other related researches. The accumulation of global progress over many generation leads to effective solutions that involve the production of rather articulated behaviors. The complexity of the behavior displayed by the evolving robots tend to increase across generation although progresses in performance are not always accompanied by behavior complexification.