 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Learning of Features for Control: Experiments with Embodied and Situated Agents
Paper and Code

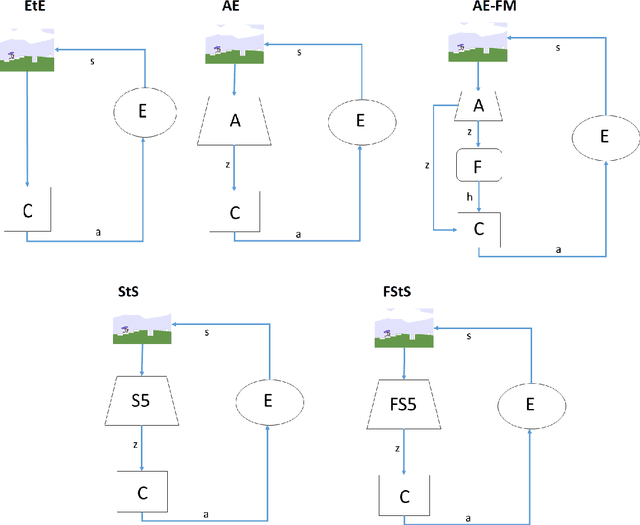
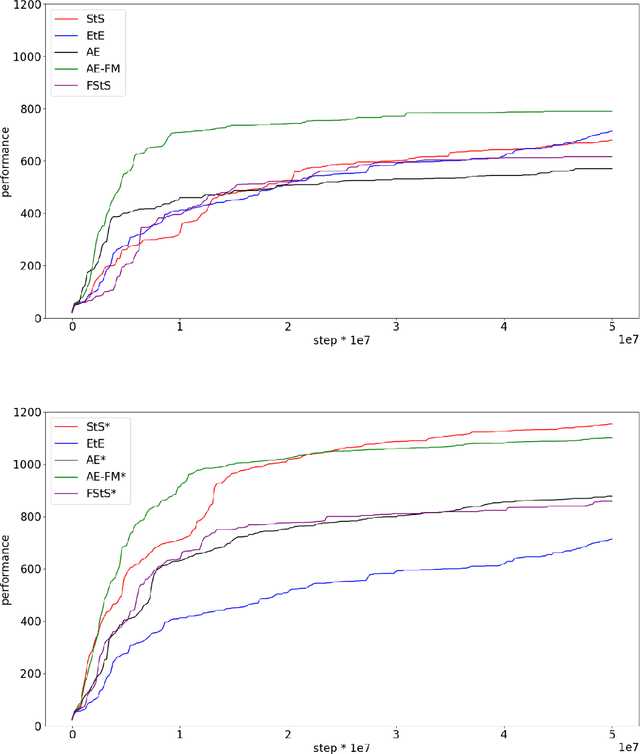
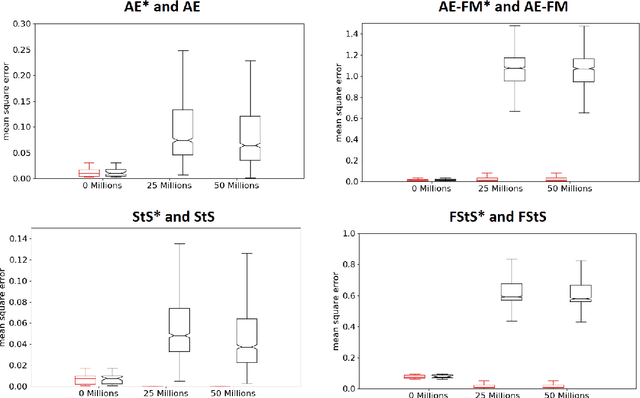
As discussed in previous studies, the efficacy of evolutionary or reinforcement learning algorithms for continuous control optimization can be enhanced by including a neural module dedicated to feature extraction trained through self-supervised methods. In this paper we report additional experiments supporting this hypothesis and we demonstrate how the advantage provided by feature extraction is not limited to problems that benefit from dimensionality reduction or that involve agents operating on the basis of allocentric perception. We introduce a method that permits to continue the training of the feature-extraction module during the training of the policy network and that increases the efficacy of feature extraction. Finally, we compare alternative feature-extracting methods and we show that sequence-to-sequence learning yields better results than the methods considered in previous studies.