 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment among Language, Vision and Action Representations
Jan 30, 2026A fundamental question in cognitive science and AI concerns whether different learning modalities: language, vision, and action, give rise to distinct or shared internal representations. Traditional views assume that models trained on different data types develop specialized, non-transferable representations. However, recent evidence suggests unexpected convergence: models optimized for distinct tasks may develop similar representational geometries. We investigate whether this convergence extends to embodied action learning by training a transformer-based agent to execute goal-directed behaviors in response to natural language instructions. Using behavioral cloning on the BabyAI platform, we generated action-grounded language embeddings shaped exclusively by sensorimotor control requirements. We then compared these representations with those extracted from state-of-the-art large language models (LLaMA, Qwen, DeepSeek, BERT) and vision-language models (CLIP, BLIP). Despite substantial differences in training data, modality, and objectives, we observed robust cross-modal alignment. Action representations aligned strongly with decoder-only language models and BLIP (precision@15: 0.70-0.73), approaching the alignment observed among language models themselves. Alignment with CLIP and BERT was significantly weaker. These findings indicate that linguistic, visual, and action representations converge toward partially shared semantic structures, supporting modality-independent semantic organization and highlighting potential for cross-domain transfer in embodied AI systems.
Large Language Models as Simulative Agents for Neurodivergent Adult Psychometric Profiles
Jan 16, 2026Adult neurodivergence, including Attention-Deficit/Hyperactivity Disorder (ADHD), high-functioning Autism Spectrum Disorder (ASD), and Cognitive Disengagement Syndrome (CDS), is marked by substantial symptom overlap that limits the discriminant sensitivity of standard psychometric instruments. While recent work suggests that Large Language Models (LLMs) can simulate human psychometric responses from qualitative data, it remains unclear whether they can accurately and stably model neurodevelopmental traits rather than broad personality characteristics. This study examines whether LLMs can generate psychometric responses that approximate those of real individuals when grounded in a structured qualitative interview, and whether such simulations are sensitive to variations in trait intensity. Twenty-six adults completed a 29-item open-ended interview and four standardized self-report measures (ASRS, BAARS-IV, AQ, RAADS-R). Two LLMs (GPT-4o and Qwen3-235B-A22B) were prompted to infer an individual psychological profile from interview content and then respond to each questionnaire in-role. Accuracy, reliability, and sensitivity were assessed using group-level comparisons, error metrics, exact-match scoring, and a randomized baseline. Both models outperformed random responses across instruments, with GPT-4o showing higher accuracy and reproducibility. Simulated responses closely matched human data for ASRS, BAARS-IV, and RAADS-R, while the AQ revealed subscale-specific limitations, particularly in Attention to Detail. Overall, the findings indicate that interview-grounded LLMs can produce coherent and above-chance simulations of neurodevelopmental traits, supporting their potential use as synthetic participants in early-stage psychometric research, while highlighting clear domain-specific constraints.
Comparing Human Expertise and Large Language Models Embeddings in Content Validity Assessment of Personality Tests
Mar 15, 2025In this article we explore the application of Large Language Models (LLMs) in assessing the content validity of psychometric instruments, focusing on the Big Five Questionnaire (BFQ) and Big Five Inventory (BFI). Content validity, a cornerstone of test construction, ensures that psychological measures adequately cover their intended constructs. Using both human expert evaluations and advanced LLMs, we compared the accuracy of semantic item-construct alignment. Graduate psychology students employed the Content Validity Ratio (CVR) to rate test items, forming the human baseline. In parallel, state-of-the-art LLMs, including multilingual and fine-tuned models, analyzed item embeddings to predict construct mappings. The results reveal distinct strengths and limitations of human and AI approaches. Human validators excelled in aligning the behaviorally rich BFQ items, while LLMs performed better with the linguistically concise BFI items. Training strategies significantly influenced LLM performance, with models tailored for lexical relationships outperforming general-purpose LLMs. Here we highlights the complementary potential of hybrid validation systems that integrate human expertise and AI precision. The findings underscore the transformative role of LLMs in psychological assessment, paving the way for scalable, objective, and robust test development methodologies.
Qualitative Differences Between Evolutionary Strategies and Reinforcement Learning Methods for Control of Autonomous Agents
May 16, 2022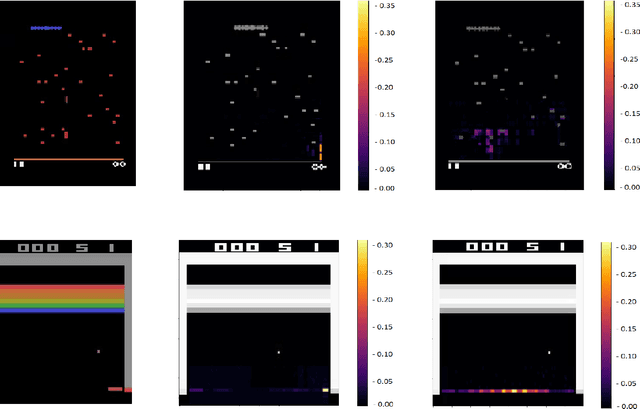
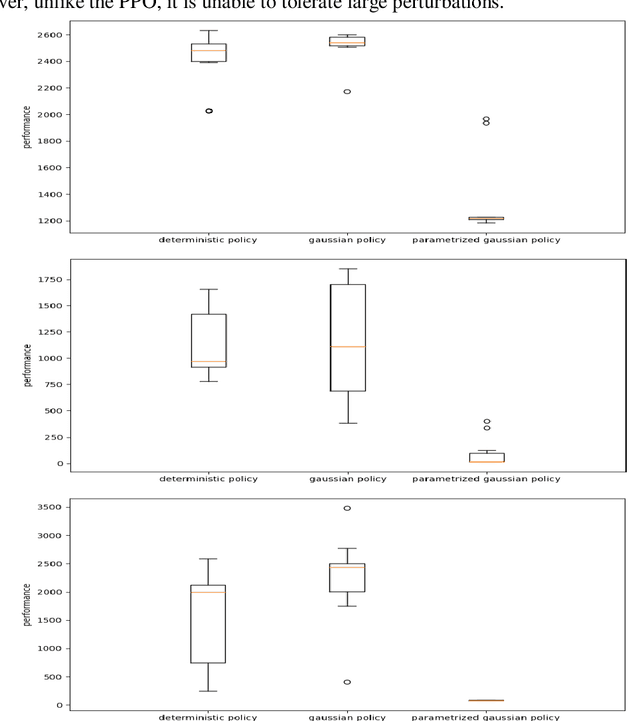
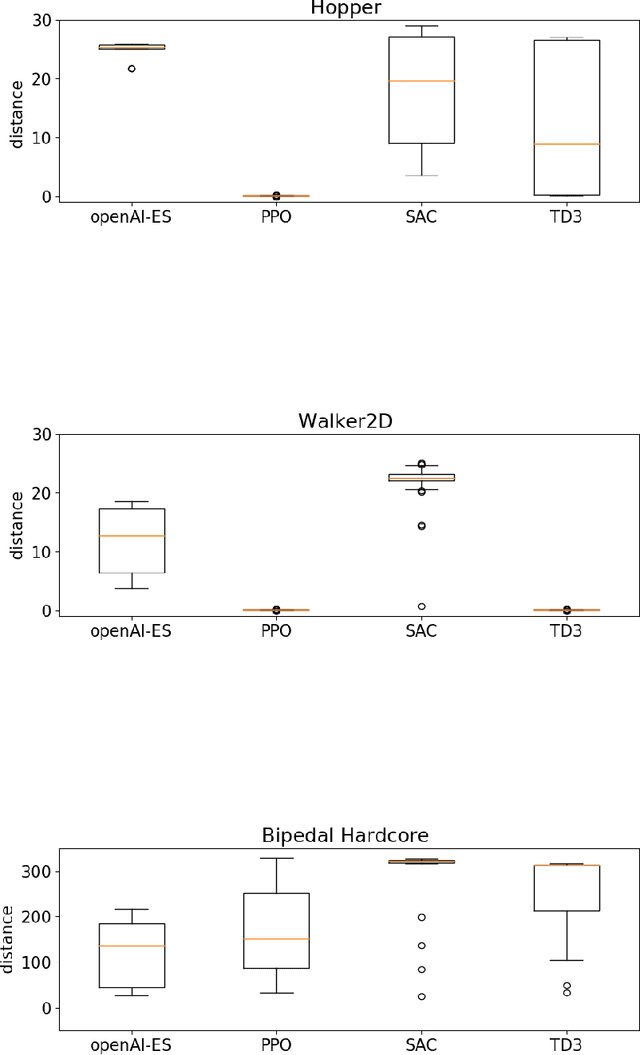
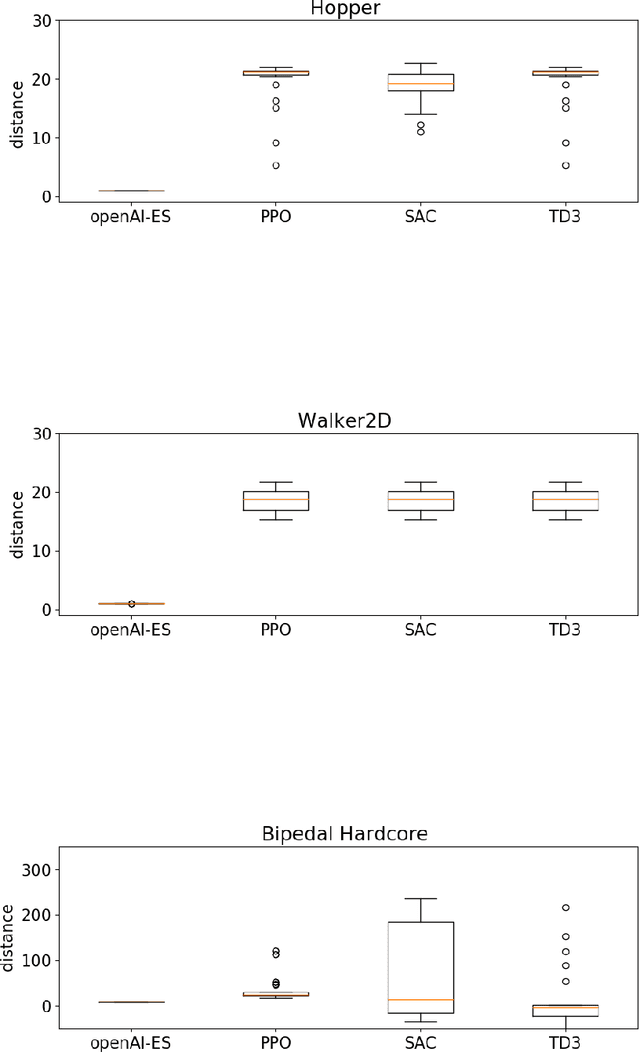
In this paper we analyze the qualitative differences between evolutionary strategies and reinforcement learning algorithms by focusing on two popular state-of-the-art algorithms: the OpenAI-ES evolutionary strategy and the Proximal Policy Optimization (PPO) reinforcement learning algorithm -- the most similar methods of the two families. We analyze how the methods differ with respect to: (i) general efficacy, (ii) ability to cope with sparse rewards, (iii) propensity/capacity to discover minimal solutions, (iv) dependency on reward shaping, and (v) ability to cope with variations of the environmental conditions. The analysis of the performance and of the behavioral strategies displayed by the agents trained with the two methods on benchmark problems enable us to demonstrate qualitative differences which were not identified in previous studies, to identify the relative weakness of the two methods, and to propose ways to ameliorate some of those weakness. We show that the characteristics of the reward function has a strong impact which vary qualitatively not only for the OpenAI-ES and the PPO but also for alternative reinforcement learning algorithms, thus demonstrating the importance of optimizing the characteristic of the reward function to the algorithm used.
Automated Curriculum Learning for Embodied Agents: A Neuroevolutionary Approach
Feb 17, 2021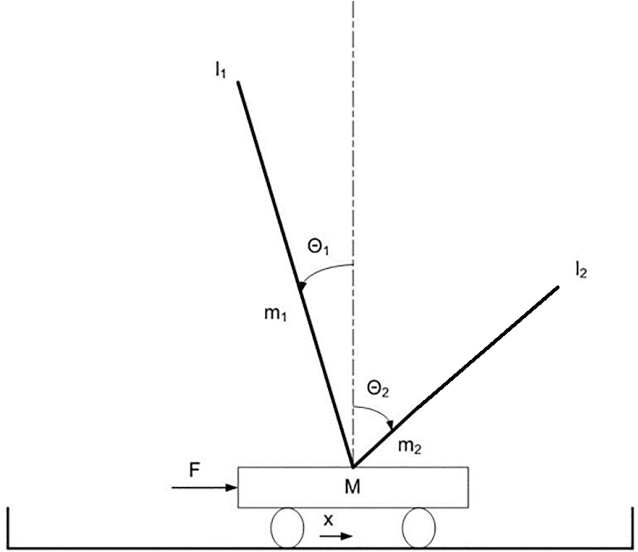



We demonstrate how an evolutionary algorithm can be extended with a curriculum learning process that selects automatically the environmental conditions in which the evolving agents are evaluated. The environmental conditions are selected so to adjust the level of difficulty to the ability level of the current evolving agents and so to challenge the weaknesses of the evolving agents. The method does not require domain knowledge and does not introduce additional hyperparameters. The results collected on two benchmark problems, that require to solve a task in significantly varying environmental conditions, demonstrate that the method proposed outperforms conventional algorithms and generates solutions that are robust to variations
Autonomous Learning of Features for Control: Experiments with Embodied and Situated Agents
Sep 15, 2020
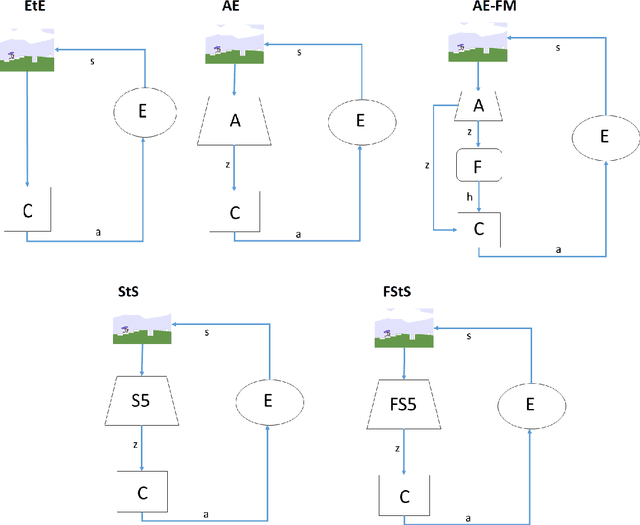
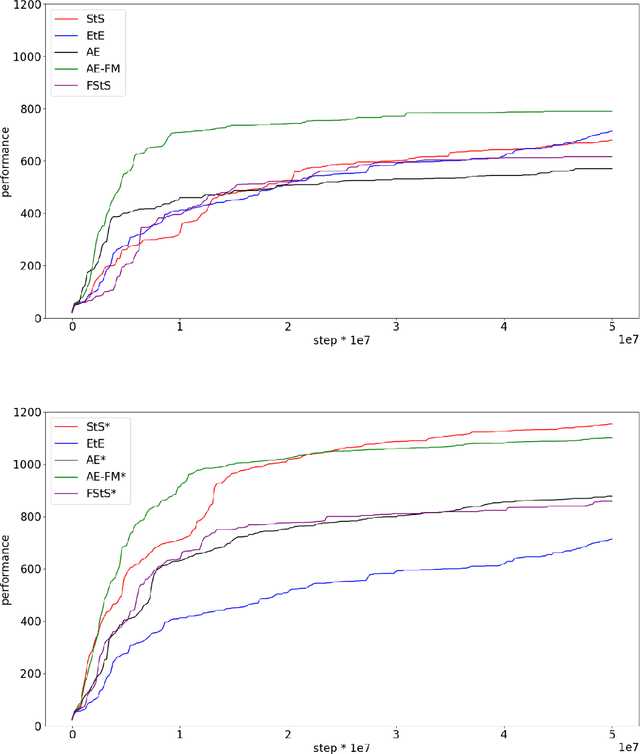
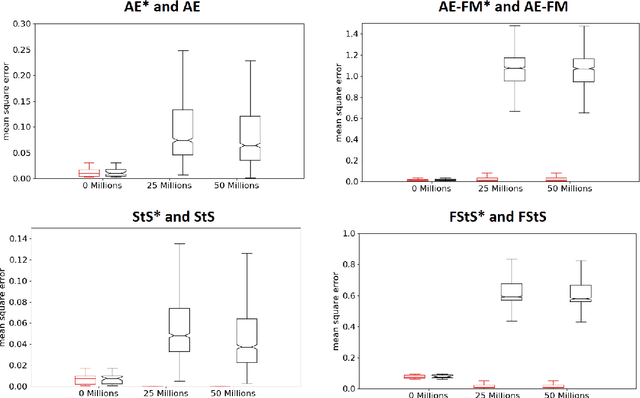
As discussed in previous studies, the efficacy of evolutionary or reinforcement learning algorithms for continuous control optimization can be enhanced by including a neural module dedicated to feature extraction trained through self-supervised methods. In this paper we report additional experiments supporting this hypothesis and we demonstrate how the advantage provided by feature extraction is not limited to problems that benefit from dimensionality reduction or that involve agents operating on the basis of allocentric perception. We introduce a method that permits to continue the training of the feature-extraction module during the training of the policy network and that increases the efficacy of feature extraction. Finally, we compare alternative feature-extracting methods and we show that sequence-to-sequence learning yields better results than the methods considered in previous studies.
Efficacy of Modern Neuro-Evolutionary Strategies for Continuous Control Optimization
Dec 11, 2019



We analyze the efficacy of modern neuro-evolutionary strategies for continuous control optimization. Overall the results collected on a wide variety of qualitatively different benchmark problems indicate that these methods are generally effective and scale well with respect to the number of parameters and the complexity of the problem. We demonstrate the importance of using suitable fitness functions or reward criteria since functions that are optimal for reinforcement learning algorithms tend to be sub-optimal for evolutionary strategies and vice versa. Finally, we provide an analysis of the role of hyper-parameters that demonstrates the importance of normalization techniques, especially in complex problems.
Scaling Up Cartesian Genetic Programming through Preferential Selection of Larger Solutions
Oct 22, 2018



We demonstrate how efficiency of Cartesian Genetic Programming method can be scaled up through the preferential selection of phenotypically larger solutions, i.e. through the preferential selection of larger solutions among equally good solutions. The advantage of the preferential selection of larger solutions is validated on the six, seven and eight-bit parity problems, on a dynamically varying problem involving the classification of binary patterns, and on the Paige regression problem. In all cases, the preferential selection of larger solutions provides an advantage in term of the performance of the evolved solutions and in term of speed, the number of evaluations required to evolve optimal or high-quality solutions. The advantage provided by the preferential selection of larger solutions can be further extended by self-adapting the mutation rate through the one-fifth success rule. Finally, for problems like the Paige regression in which neutrality plays a minor role, the advantage of the preferential selection of larger solutions can be extended by preferring larger solutions also among quasi-neutral alternative candidate solutions, i.e. solutions achieving slightly different performance.
Moderate Environmental Variation Promotes the Evolution of Robust Solutions
Mar 01, 2018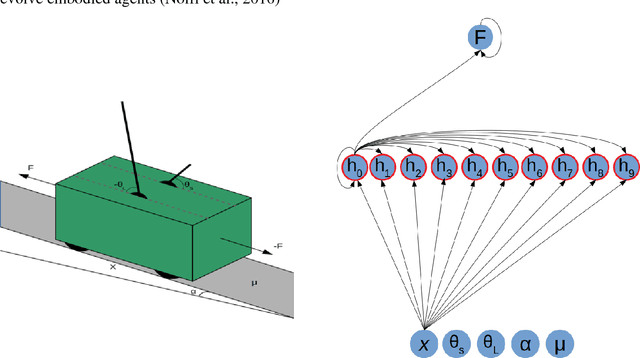
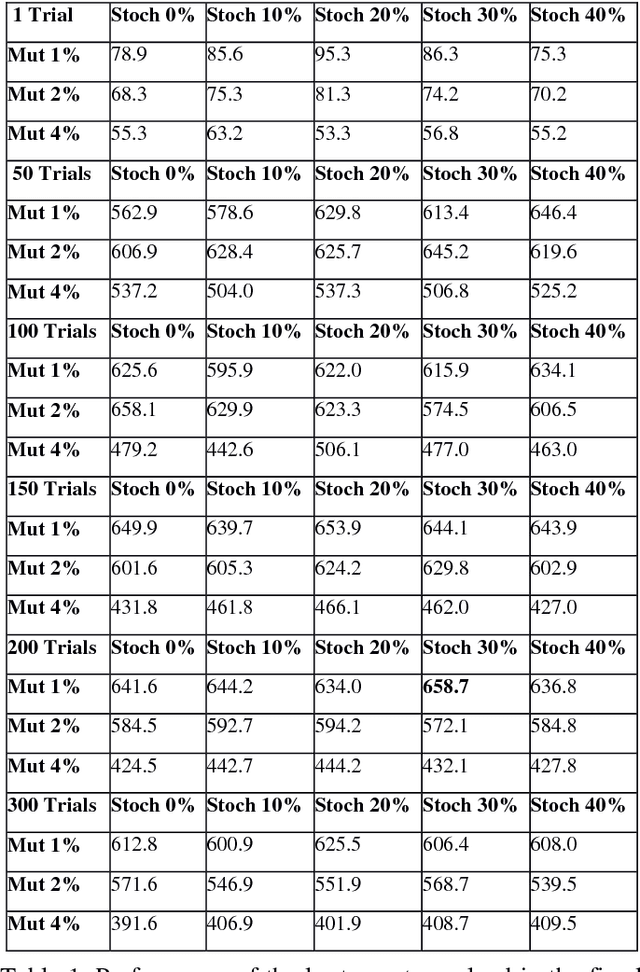
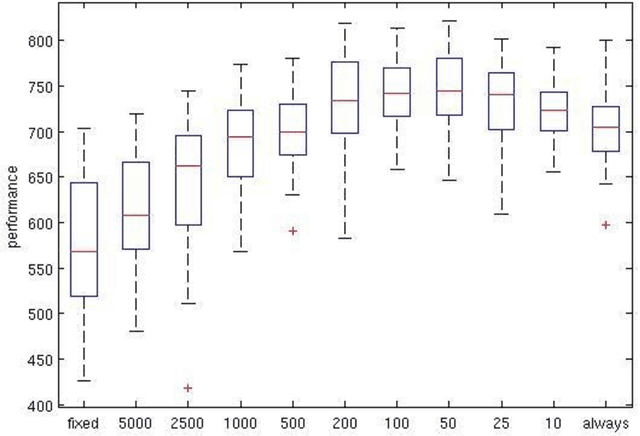
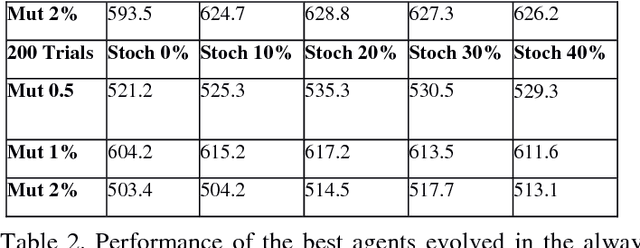
Previous evolutionary studies demonstrated how evaluating evolving agents in variable environmental conditions enable them to develop solutions that are robust to environmental variation. We demonstrate how the robustness of the agents can be further improved by exposing them also to environmental variations throughout generations. These two types of environmental variations play partially distinct roles as demonstrated by the fact that agents evolved in environments that do not vary throughout generations display lower performance than agents evolved in varying environments independently from the amount of environmental variation experienced during evaluation. Moreover, our results demonstrate that performance increases when the amount of variations introduced during agents evaluation and the rate at which the environment varies throughout generations are moderate. This is explained by the fact that the probability to retain genetic variations, including non-neutral variations that alter the behavior of the agents, increases when the environment varies throughout generations but also when new environmental conditions persist over time long enough to enable genetic accommodation.
Robustness, Evolvability and Phenotypic Complexity: Insights from Evolving Digital Circuits
Dec 12, 2017



We show how the characteristics of the evolutionary algorithm influence the evolvability of candidate solutions, i.e. the propensity of evolving individuals to generate better solutions as a result of genetic variation. More specifically, (1+{\lambda}) evolutionary strategies largely outperform ({\mu}+1) evolutionary strategies in the context of the evolution of digital circuits --- a domain characterized by a high level of neutrality. This difference is due to the fact that the competition for robustness to mutations among the circuits evolved with ({\mu}+1) evolutionary strategies leads to the selection of phenotypically simple but low evolvable circuits. These circuits achieve robustness by minimizing the number of functional genes rather than by relying on redundancy or degeneracy to buffer the effects of mutations. The analysis of these factors enabled us to design a new evolutionary algorithm, named Parallel Stochastic Hill Climber (PSHC), which outperforms the other two methods considered.