 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Anomaly Detection for Auditing Data and Impact of Categorical Encodings
Oct 26, 2022



In this paper, we introduce the Vehicle Claims dataset, consisting of fraudulent insurance claims for automotive repairs. The data belongs to the more broad category of Auditing data, which includes also Journals and Network Intrusion data. Insurance claim data are distinctively different from other auditing data (such as network intrusion data) in their high number of categorical attributes. We tackle the common problem of missing benchmark datasets for anomaly detection: datasets are mostly confidential, and the public tabular datasets do not contain relevant and sufficient categorical attributes. Therefore, a large-sized dataset is created for this purpose and referred to as Vehicle Claims (VC) dataset. The dataset is evaluated on shallow and deep learning methods. Due to the introduction of categorical attributes, we encounter the challenge of encoding them for the large dataset. As One Hot encoding of high cardinal dataset invokes the "curse of dimensionality", we experiment with GEL encoding and embedding layer for representing categorical attributes. Our work compares competitive learning, reconstruction-error, density estimation and contrastive learning approaches for Label, One Hot, GEL encoding and embedding layer to handle categorical values.
Estimating the Value-at-Risk by Temporal VAE
Dec 03, 2021
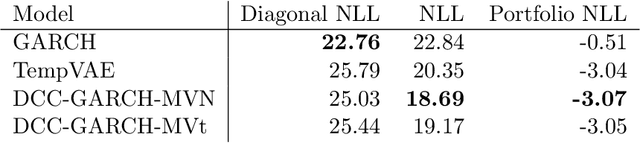
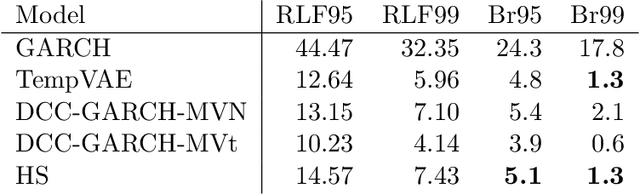
Estimation of the value-at-risk (VaR) of a large portfolio of assets is an important task for financial institutions. As the joint log-returns of asset prices can often be projected to a latent space of a much smaller dimension, the use of a variational autoencoder (VAE) for estimating the VaR is a natural suggestion. To ensure the bottleneck structure of autoencoders when learning sequential data, we use a temporal VAE (TempVAE) that avoids an auto-regressive structure for the observation variables. However, the low signal- to-noise ratio of financial data in combination with the auto-pruning property of a VAE typically makes the use of a VAE prone to posterior collapse. Therefore, we propose to use annealing of the regularization to mitigate this effect. As a result, the auto-pruning of the TempVAE works properly which also results in excellent estimation results for the VaR that beats classical GARCH-type and historical simulation approaches when applied to real data.