 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and explainable clustering in the Manhattan and Tanimoto distance
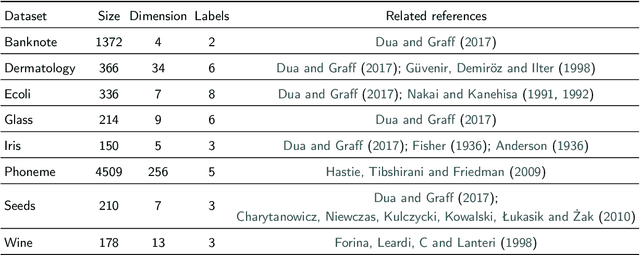
Jan 13, 2026The CLASSIX algorithm is a fast and explainable approach to data clustering. In its original form, this algorithm exploits the sorting of the data points by their first principal component to truncate the search for nearby data points, with nearness being defined in terms of the Euclidean distance. Here we extend CLASSIX to other distance metrics, including the Manhattan distance and the Tanimoto distance. Instead of principal components, we use an appropriate norm of the data vectors as the sorting criterion, combined with the triangle inequality for search termination. In the case of Tanimoto distance, a provably sharper intersection inequality is used to further boost the performance of the new algorithm. On a real-world chemical fingerprint benchmark, CLASSIX Tanimoto is about 30 times faster than the Taylor--Butina algorithm, and about 80 times faster than DBSCAN, while computing higher-quality clusters in both cases.
Exact fixed-radius nearest neighbor search with an application to clustering
Dec 15, 2022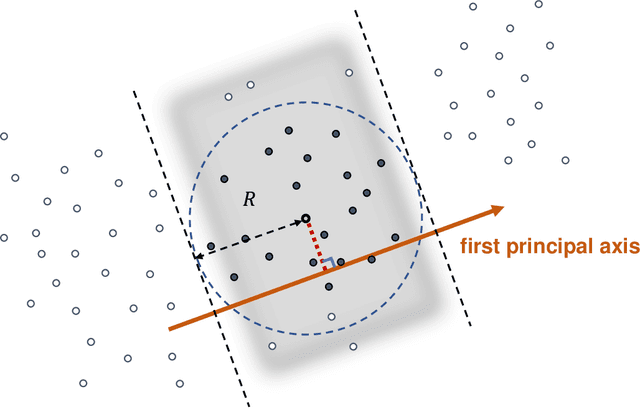
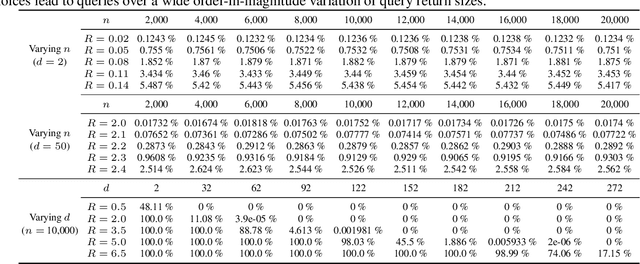
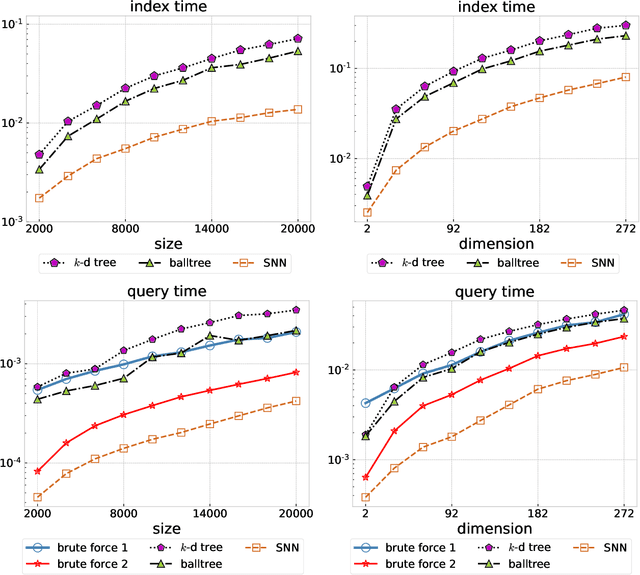
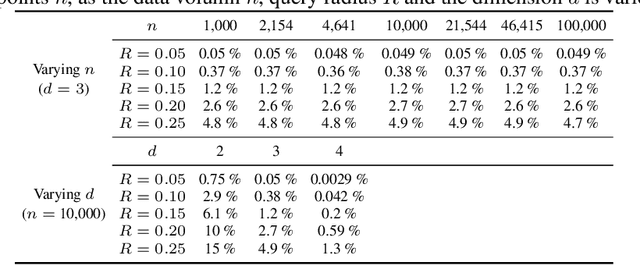
Fixed-radius nearest-neighbor search is a common database operation that retrieves all data points within a user-specified distance to a query point. There are efficient approximate nearest neighbor search algorithms that provide fast query responses but they often have a very compute-intensive indexing phase and require parameter tuning. Therefore, exact brute force and tree-based search methods are still widely used. Here we propose a new fixed-radius nearest neighbor search method that significantly improves over brute force and tree-based methods in terms of index and query time, returns exact results, and requires no parameter tuning. The method exploits a sorting of the data points by their first principal component, thereby facilitating a reduction in query search space. Further speedup is gained from an efficient implementation using high-level Basic Linear Algebra Subprograms (BLAS). We provide theoretical analysis of our method and demonstrate its practical performance when used stand-alone and when applied within a clustering algorithm.
Fast and explainable clustering based on sorting
Feb 03, 2022

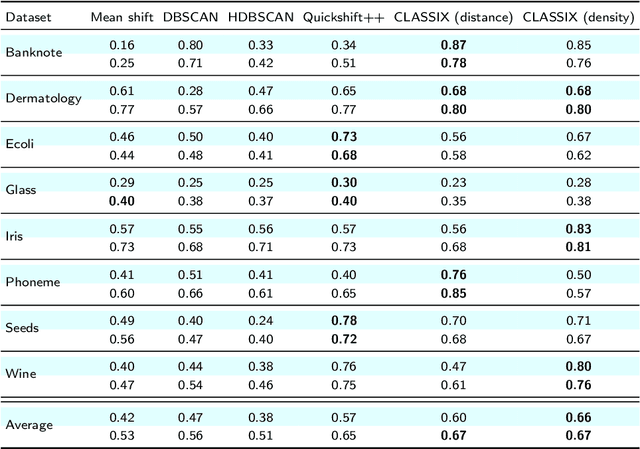
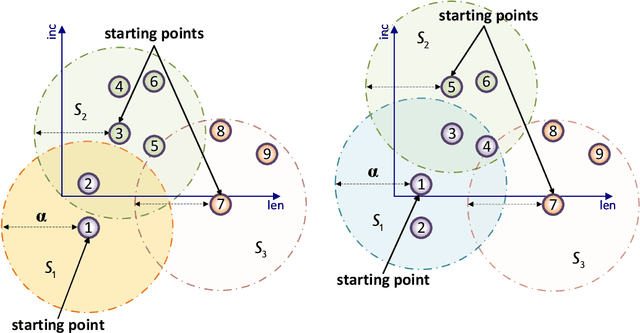
We introduce a fast and explainable clustering method called CLASSIX. It consists of two phases, namely a greedy aggregation phase of the sorted data into groups of nearby data points, followed by the merging of groups into clusters. The algorithm is controlled by two scalar parameters, namely a distance parameter for the aggregation and another parameter controlling the minimal cluster size. Extensive experiments are conducted to give a comprehensive evaluation of the clustering performance on synthetic and real-world datasets, with various cluster shapes and low to high feature dimensionality. Our experiments demonstrate that CLASSIX competes with state-of-the-art clustering algorithms. The algorithm has linear space complexity and achieves near linear time complexity on a wide range of problems. Its inherent simplicity allows for the generation of intuitive explanations of the computed clusters.
An efficient aggregation method for the symbolic representation of temporal data
Jan 14, 2022


Symbolic representations are a useful tool for the dimension reduction of temporal data, allowing for the efficient storage of and information retrieval from time series. They can also enhance the training of machine learning algorithms on time series data through noise reduction and reduced sensitivity to hyperparameters. The adaptive Brownian bridge-based aggregation (ABBA) method is one such effective and robust symbolic representation, demonstrated to accurately capture important trends and shapes in time series. However, in its current form the method struggles to process very large time series. Here we present a new variant of the ABBA method, called fABBA. This variant utilizes a new aggregation approach tailored to the piecewise representation of time series. By replacing the k-means clustering used in ABBA with a sorting-based aggregation technique, and thereby avoiding repeated sum-of-squares error computations, the computational complexity is significantly reduced. In contrast to the original method, the new approach does not require the number of time series symbols to be specified in advance. Through extensive tests we demonstrate that the new method significantly outperforms ABBA with a considerable reduction in runtime while also outperforming the popular SAX and 1d-SAX representations in terms of reconstruction accuracy. We further demonstrate that fABBA can compress other data types such as images.
Machine Learning-Based Soft Sensors for Vacuum Distillation Unit
Nov 19, 2021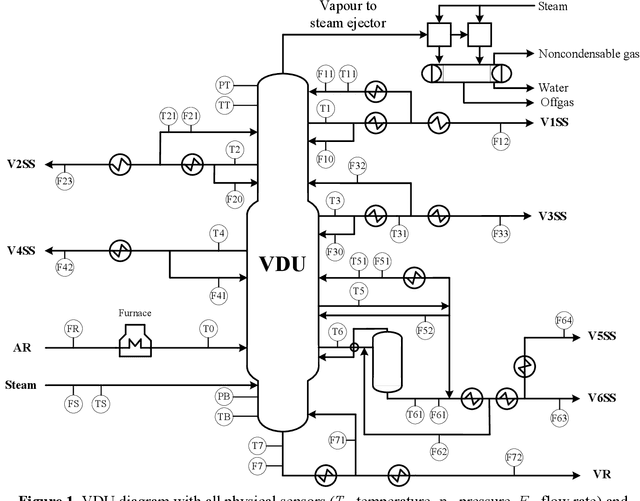
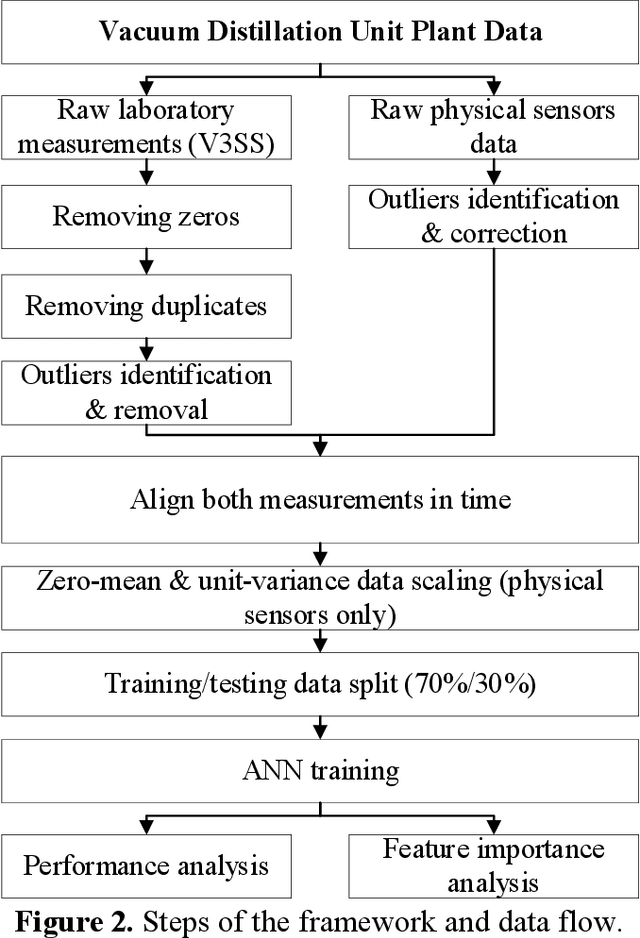
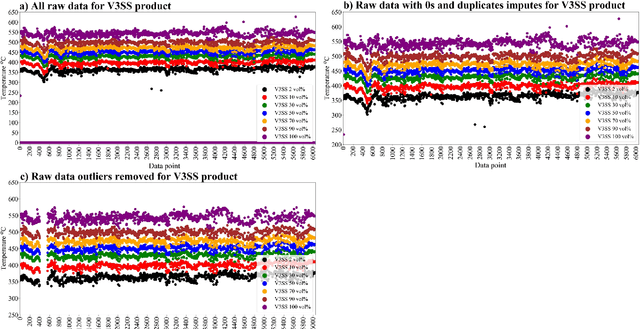
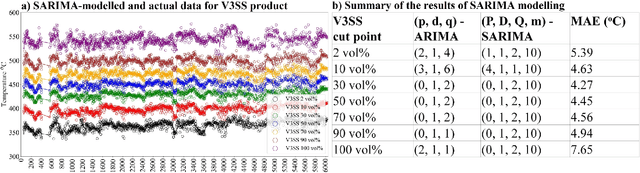
Product quality assessment in the petroleum processing industry can be difficult and time-consuming, e.g. due to a manual collection of liquid samples from the plant and subsequent chemical laboratory analysis of the samples. The product quality is an important property that informs whether the products of the process are within the specifications. In particular, the delays caused by sample processing (collection, laboratory measurements, results analysis, reporting) can lead to detrimental economic effects. One of the strategies to deal with this problem is soft sensors. Soft sensors are a collection of models that can be used to predict and forecast some infrequently measured properties (such as laboratory measurements of petroleum products) based on more frequent measurements of quantities like temperature, pressure and flow rate provided by physical sensors. Soft sensors short-cut the pathway to obtain relevant information about the product quality, often providing measurements as frequently as every minute. One of the applications of soft sensors is for the real-time optimization of a chemical process by a targeted adaptation of operating parameters. Models used for soft sensors can have various forms, however, among the most common are those based on artificial neural networks (ANNs). While soft sensors can deal with some of the issues in the refinery processes, their development and deployment can pose other challenges that are addressed in this paper. Firstly, it is important to enhance the quality of both sets of data (laboratory measurements and physical sensors) in a data pre-processing stage (as described in Methodology section). Secondly, once the data sets are pre-processed, different models need to be tested against prediction error and the model's interpretability. In this work, we present a framework for soft sensor development from raw data to ready-to-use models.
A comparison of LSTM and GRU networks for learning symbolic sequences
Jul 05, 2021

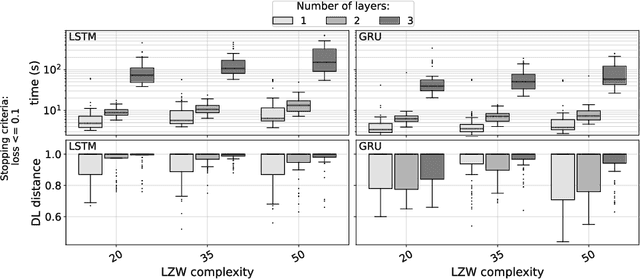
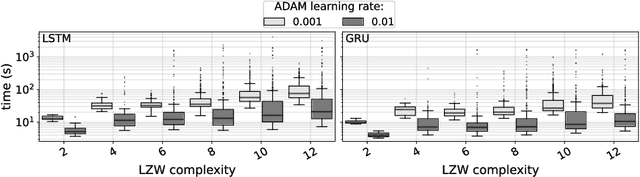
We explore relations between the hyper-parameters of a recurrent neural network (RNN) and the complexity of string sequences it is able to memorize. We compare long short-term memory (LSTM) networks and gated recurrent units (GRUs). We find that an increase of RNN depth does not necessarily result in better memorization capability when the training time is constrained. Our results also indicate that the learning rate and the number of units per layer are among the most important hyper-parameters to be tuned. Generally, GRUs outperform LSTM networks on low complexity sequences while on high complexity sequences LSTMs perform better.
Pre-treatment of outliers and anomalies in plant data: Methodology and case study of a Vacuum Distillation Unit
Jun 17, 2021
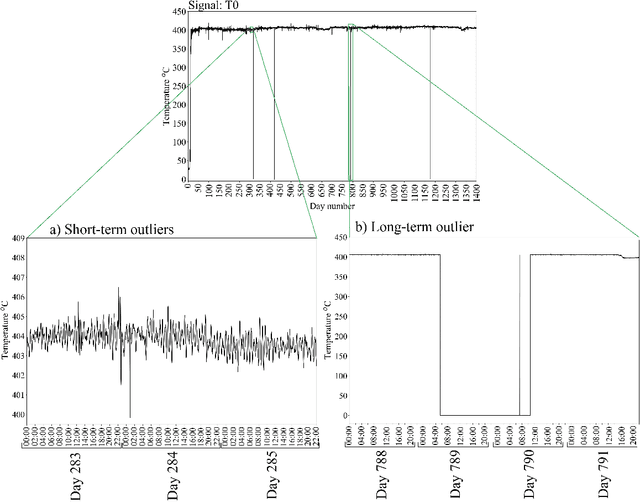
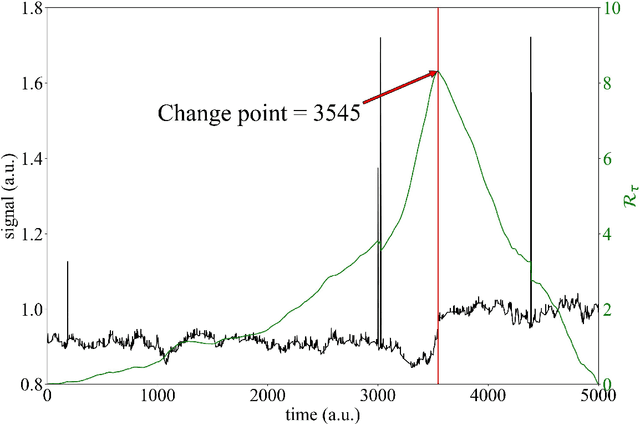

Data pre-treatment plays a significant role in improving data quality, thus allowing extraction of accurate information from raw data. One of the data pre-treatment techniques commonly used is outliers detection. The so-called 3${\sigma}$ method is a common practice to identify the outliers. As shown in the manuscript, it does not identify all outliers, resulting in possible distortion of the overall statistics of the data. This problem can have a significant impact on further data analysis and can lead to reduction in the accuracy of predictive models. There is a plethora of various techniques for outliers detection, however, aside from theoretical work, they all require case study work. Two types of outliers were considered: short-term (erroneous data, noise) and long-term outliers (e.g. malfunctioning for longer periods). The data used were taken from the vacuum distillation unit (VDU) of an Asian refinery and included 40 physical sensors (temperature, pressure and flow rate). We used a modified method for 3${\sigma}$ thresholds to identify the short-term outliers, i.e. ensors data are divided into chunks determined by change points and 3${\sigma}$ thresholds are calculated within each chunk representing near-normal distribution. We have shown that piecewise 3${\sigma}$ method offers a better approach to short-term outliers detection than 3${\sigma}$ method applied to the entire time series. Nevertheless, this does not perform well for long-term outliers (which can represent another state in the data). In this case, we used principal component analysis (PCA) with Hotelling's $T^2$ statistics to identify the long-term outliers. The results obtained with PCA were subject to DBSCAN clustering method. The outliers (which were visually obvious and correctly detected by the PCA method) were also correctly identified by DBSCAN which supported the consistency and accuracy of the PCA method.
ABBA: Adaptive Brownian bridge-based symbolic aggregation of time series
Mar 27, 2020

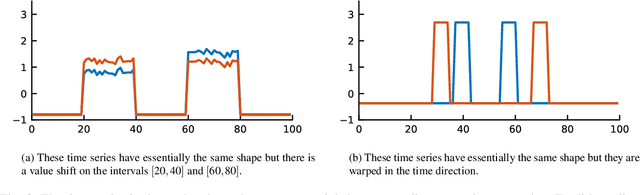

A new symbolic representation of time series, called ABBA, is introduced. It is based on an adaptive polygonal chain approximation of the time series into a sequence of tuples, followed by a mean-based clustering to obtain the symbolic representation. We show that the reconstruction error of this representation can be modelled as a random walk with pinned start and end points, a so-called Brownian bridge. This insight allows us to make ABBA essentially parameter-free, except for the approximation tolerance which must be chosen. Extensive comparisons with the SAX and 1d-SAX representations are included in the form of performance profiles, showing that ABBA is able to better preserve the essential shape information of time series compared to other approaches. Advantages and applications of ABBA are discussed, including its in-built differencing property and use for anomaly detection, and Python implementations provided.
Time Series Forecasting Using LSTM Networks: A Symbolic Approach
Mar 12, 2020
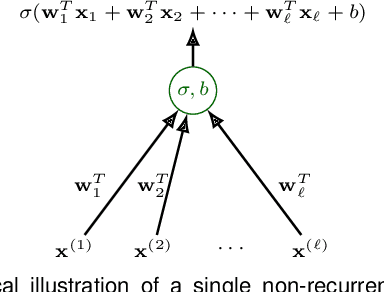

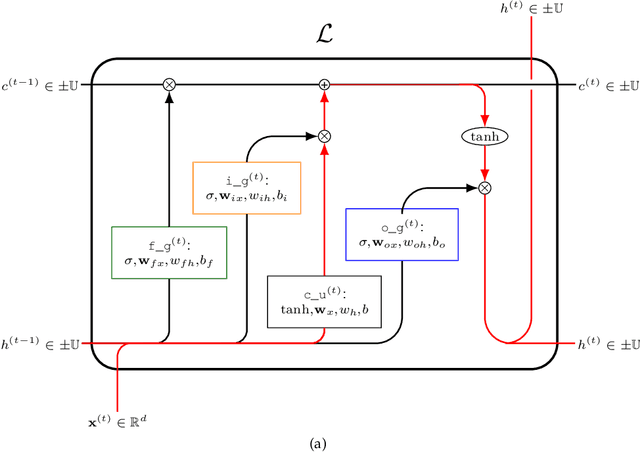
Machine learning methods trained on raw numerical time series data exhibit fundamental limitations such as a high sensitivity to the hyper parameters and even to the initialization of random weights. A combination of a recurrent neural network with a dimension-reducing symbolic representation is proposed and applied for the purpose of time series forecasting. It is shown that the symbolic representation can help to alleviate some of the aforementioned problems and, in addition, might allow for faster training without sacrificing the forecast performance.