 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-treatment of outliers and anomalies in plant data: Methodology and case study of a Vacuum Distillation Unit
Paper and Code
Jun 17, 2021
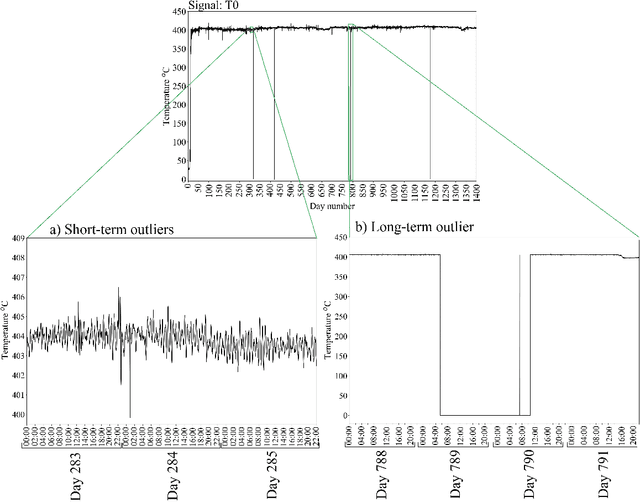
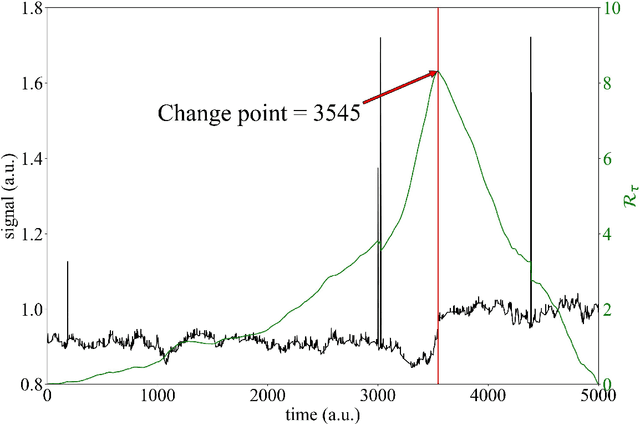

Data pre-treatment plays a significant role in improving data quality, thus allowing extraction of accurate information from raw data. One of the data pre-treatment techniques commonly used is outliers detection. The so-called 3${\sigma}$ method is a common practice to identify the outliers. As shown in the manuscript, it does not identify all outliers, resulting in possible distortion of the overall statistics of the data. This problem can have a significant impact on further data analysis and can lead to reduction in the accuracy of predictive models. There is a plethora of various techniques for outliers detection, however, aside from theoretical work, they all require case study work. Two types of outliers were considered: short-term (erroneous data, noise) and long-term outliers (e.g. malfunctioning for longer periods). The data used were taken from the vacuum distillation unit (VDU) of an Asian refinery and included 40 physical sensors (temperature, pressure and flow rate). We used a modified method for 3${\sigma}$ thresholds to identify the short-term outliers, i.e. ensors data are divided into chunks determined by change points and 3${\sigma}$ thresholds are calculated within each chunk representing near-normal distribution. We have shown that piecewise 3${\sigma}$ method offers a better approach to short-term outliers detection than 3${\sigma}$ method applied to the entire time series. Nevertheless, this does not perform well for long-term outliers (which can represent another state in the data). In this case, we used principal component analysis (PCA) with Hotelling's $T^2$ statistics to identify the long-term outliers. The results obtained with PCA were subject to DBSCAN clustering method. The outliers (which were visually obvious and correctly detected by the PCA method) were also correctly identified by DBSCAN which supported the consistency and accuracy of the PCA method.