 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Power Control for Large Energy Harvesting Networks: A Multi-Agent Deep Reinforcement Learning Approach
Apr 01, 2019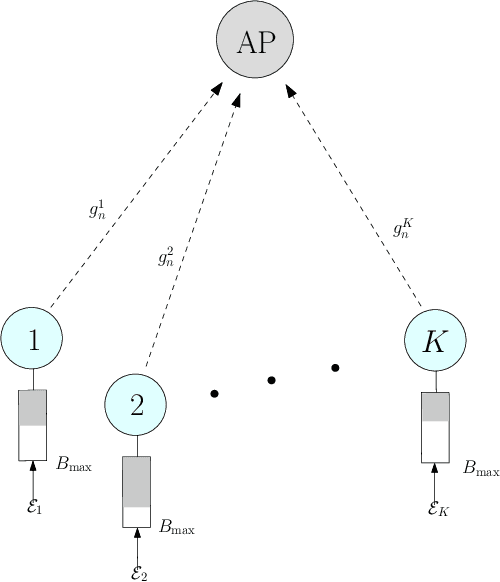
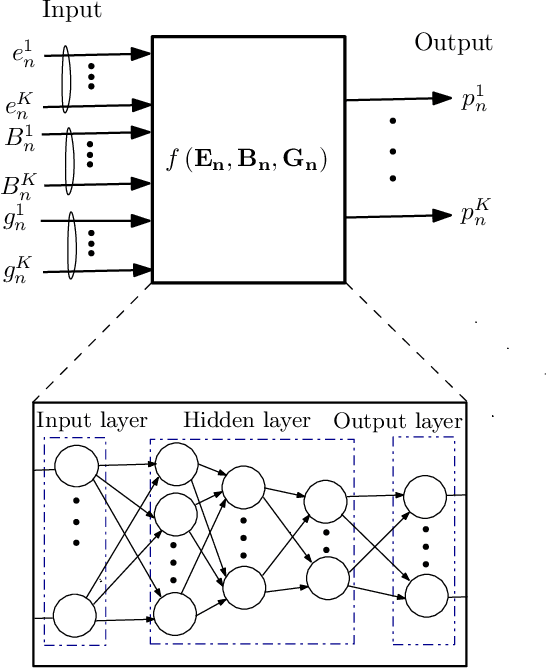
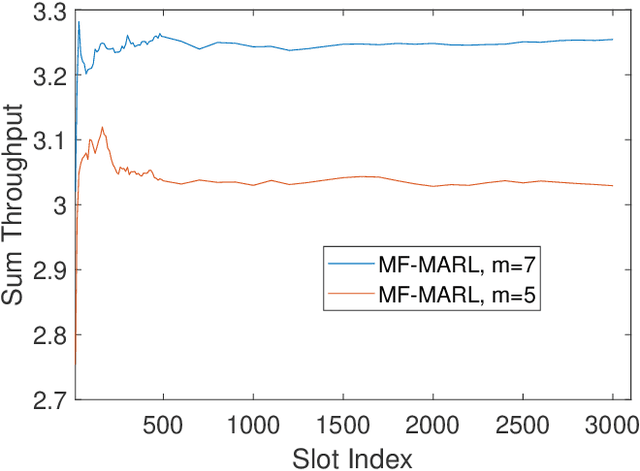
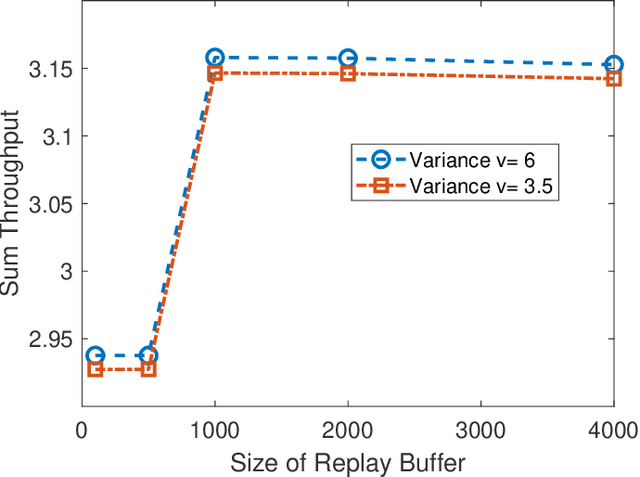
In this paper, we develop a multi-agent reinforcement learning (MARL) framework to obtain online power control policies for a large energy harvesting (EH) multiple access channel, when only the causal information about the EH process and wireless channel is available. In the proposed framework, we model the online power control problem as a discrete-time mean-field game (MFG), and leverage the deep reinforcement learning technique to learn the stationary solution of the game in a distributed fashion. We analytically show that the proposed procedure converges to the unique stationary solution of the MFG. Using the proposed framework, the power control policies are learned in a completely distributed fashion. In order to benchmark the performance of the distributed policies, we also develop a deep neural network (DNN) based centralized as well as distributed online power control schemes. Our simulation results show the efficacy of the proposed power control policies. In particular, the DNN based centralized power control policies provide a very good performance for large EH networks for which the design of optimal policies is intractable using the conventional methods such as Markov decision processes. Further, performance of both the distributed policies is close to the throughput achieved by the centralized policies.
Model-Driven Artificial Intelligence for Online Network Optimization
May 30, 2018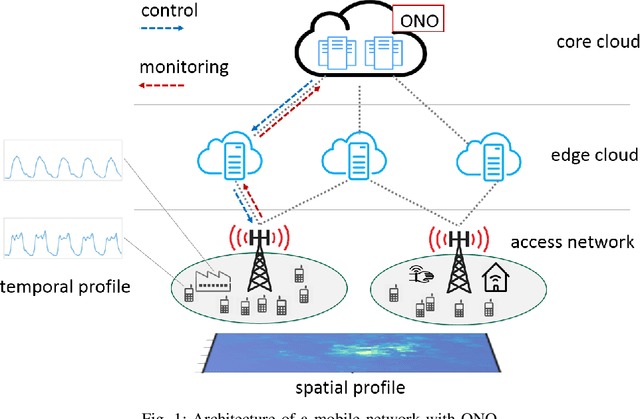
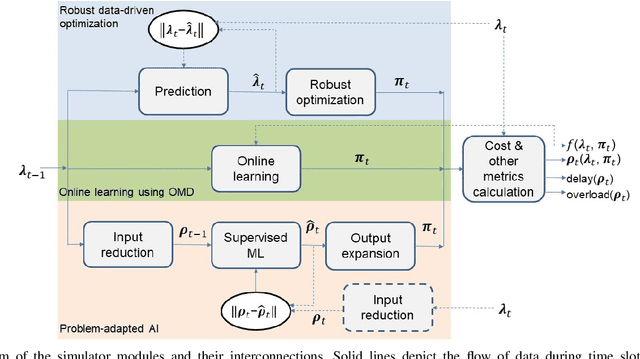
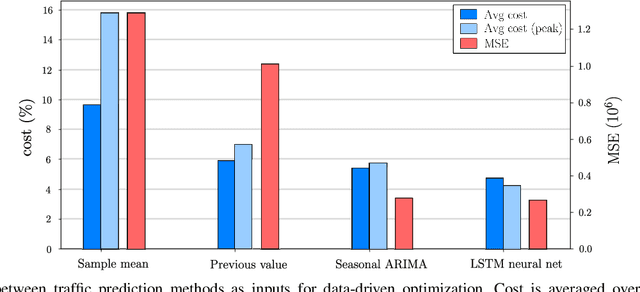
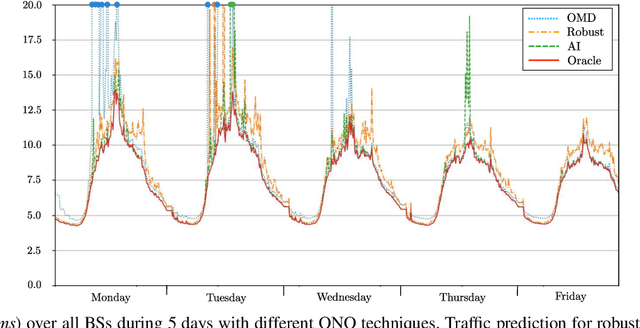
Future 5G wireless networks will rely on agile and automated network management, where the usage of diverse resources must be jointly optimized with surgical accuracy. A number of key wireless network functionalities (e.g., traffic steering, energy savings) give rise to hard optimization problems. What is more, high spatio-temporal traffic variability coupled with the need to satisfy strict per slice/service SLAs in modern networks, suggest that these problems must be constantly (re-)solved, to maintain close-to-optimal performance. To this end, in this paper we propose the framework of Online Network Optimization (ONO), which seeks to maintain both agile and efficient control over time, using an arsenal of data-driven, adaptive, and AI-based techniques. Since the mathematical tools and the studied regimes vary widely among these methodologies, a theoretical comparison is often out of reach. Therefore, the important question "what is the right ONO technique?" remains open to date. In this paper, we discuss the pros and cons of each technique and further attempt a direct quantitative comparison for a specific use case, using real data. Our results suggest that carefully combining the insights of problem modeling with state-of-the-art AI techniques provides significant advantages at reasonable complexity.