 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFALO: Fast and Accurate LiDAR 3D Object Detection on Resource-Constrained Devices
Jun 04, 2025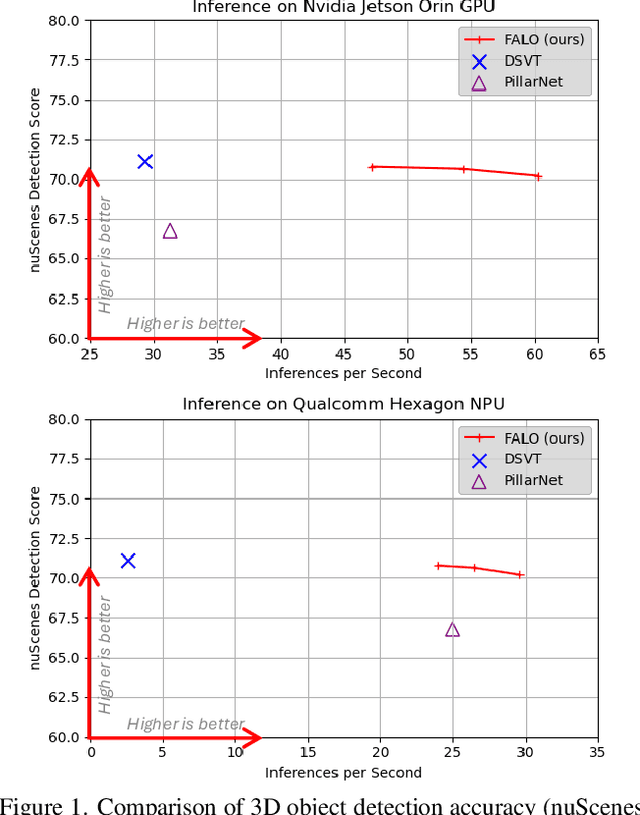

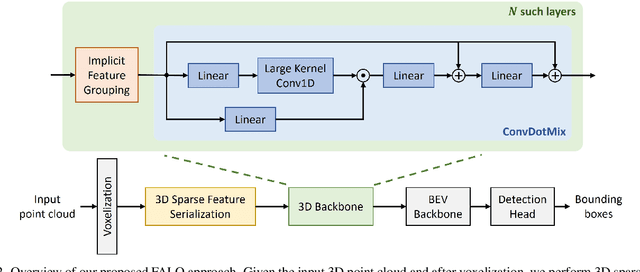
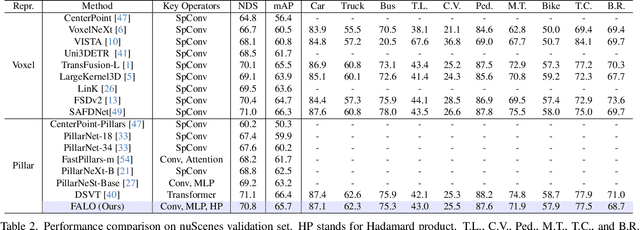
Existing LiDAR 3D object detection methods predominantely rely on sparse convolutions and/or transformers, which can be challenging to run on resource-constrained edge devices, due to irregular memory access patterns and high computational costs. In this paper, we propose FALO, a hardware-friendly approach to LiDAR 3D detection, which offers both state-of-the-art (SOTA) detection accuracy and fast inference speed. More specifically, given the 3D point cloud and after voxelization, FALO first arranges sparse 3D voxels into a 1D sequence based on their coordinates and proximity. The sequence is then processed by our proposed ConvDotMix blocks, consisting of large-kernel convolutions, Hadamard products, and linear layers. ConvDotMix provides sufficient mixing capability in both spatial and embedding dimensions, and introduces higher-order nonlinear interaction among spatial features. Furthermore, when going through the ConvDotMix layers, we introduce implicit grouping, which balances the tensor dimensions for more efficient inference and takes into account the growing receptive field. All these operations are friendly to run on resource-constrained platforms and proposed FALO can readily deploy on compact, embedded devices. Our extensive evaluation on LiDAR 3D detection benchmarks such as nuScenes and Waymo shows that FALO achieves competitive performance. Meanwhile, FALO is 1.6~9.8x faster than the latest SOTA on mobile Graphics Processing Unit (GPU) and mobile Neural Processing Unit (NPU).
YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
Apr 14, 2022
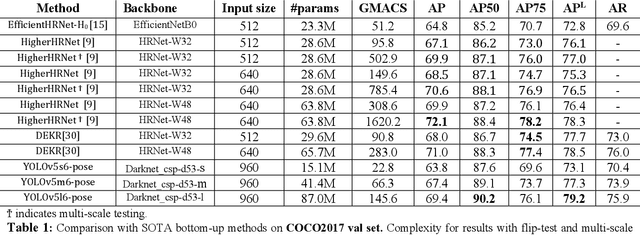

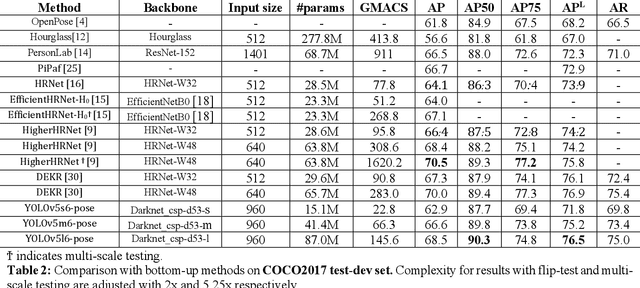
We introduce YOLO-pose, a novel heatmap-free approach for joint detection, and 2D multi-person pose estimation in an image based on the popular YOLO object detection framework. Existing heatmap based two-stage approaches are sub-optimal as they are not end-to-end trainable and training relies on a surrogate L1 loss that is not equivalent to maximizing the evaluation metric, i.e. Object Keypoint Similarity (OKS). Our framework allows us to train the model end-to-end and optimize the OKS metric itself. The proposed model learns to jointly detect bounding boxes for multiple persons and their corresponding 2D poses in a single forward pass and thus bringing in the best of both top-down and bottom-up approaches. Proposed approach doesn't require the postprocessing of bottom-up approaches to group detected keypoints into a skeleton as each bounding box has an associated pose, resulting in an inherent grouping of the keypoints. Unlike top-down approaches, multiple forward passes are done away with since all persons are localized along with their pose in a single inference. YOLO-pose achieves new state-of-the-art results on COCO validation (90.2% AP50) and test-dev set (90.3% AP50), surpassing all existing bottom-up approaches in a single forward pass without flip test, multi-scale testing, or any other test time augmentation. All experiments and results reported in this paper are without any test time augmentation, unlike traditional approaches that use flip-test and multi-scale testing to boost performance. Our training codes will be made publicly available at https://github.com/TexasInstruments/edgeai-yolov5 and https://github.com/TexasInstruments/edgeai-yolox
SS3D: Single Shot 3D Object Detector
May 02, 2020

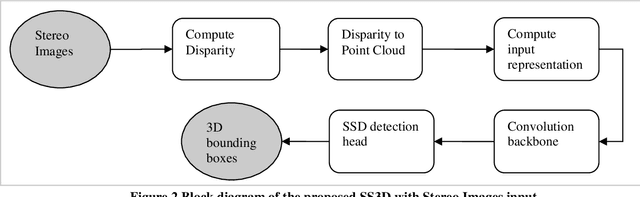
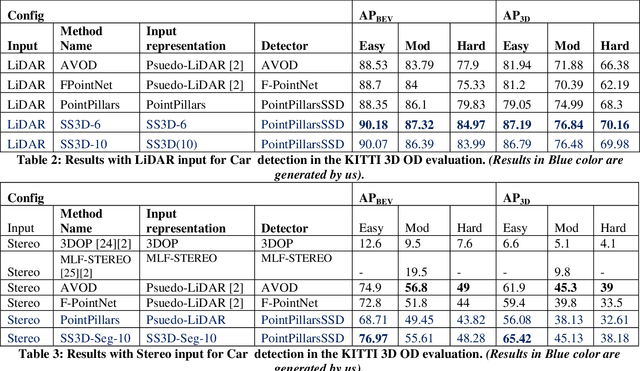
Single stage deep learning algorithm for 2D object detection was made popular by Single Shot MultiBox Detector (SSD) and it was heavily adopted in several embedded applications. PointPillars is a state of the art 3D object detection algorithm that uses a Single Shot Detector adapted for 3D object detection. The main downside of PointPillars is that it has a two stage approach with learned input representation based on fully connected layers followed by the Single Shot Detector for 3D detection. In this paper we present Single Shot 3D Object Detection (SS3D) - a single stage 3D object detection algorithm which combines straight forward, statistically computed input representation and a Single Shot Detector (based on PointPillars). Computing the input representation is straight forward, does not involve learning and does not have much computational cost. We also extend our method to stereo input and show that, aided by additional semantic segmentation input; our method produces similar accuracy as state of the art stereo based detectors. Achieving the accuracy of two stage detectors using a single stage approach is important as single stage approaches are simpler to implement in embedded, real-time applications. With LiDAR as well as stereo input, our method outperforms PointPillars. When using LiDAR input, our input representation is able to improve the AP3D of Cars objects in the moderate category from 74.99 to 76.84. When using stereo input, our input representation is able to improve the AP3D of Cars objects in the moderate category from 38.13 to 45.13. Our results are also better than other popular 3D object detectors such as AVOD and F-PointNet.
Efficient Semantic Segmentation using Gradual Grouping
Jun 22, 2018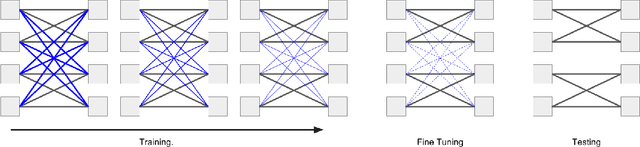
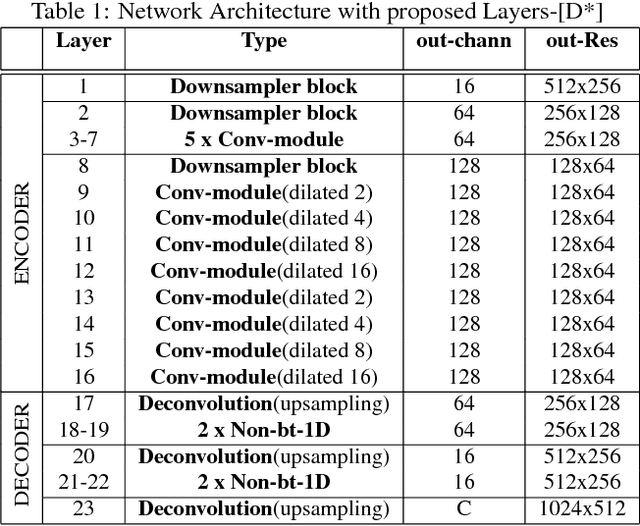

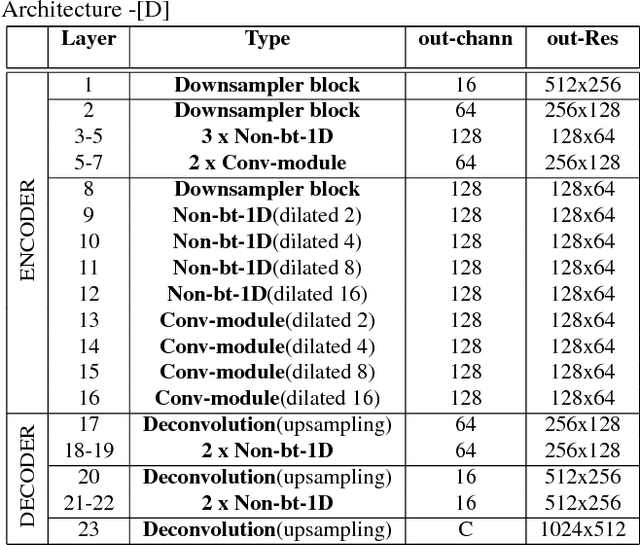
Deep CNNs for semantic segmentation have high memory and run time requirements. Various approaches have been proposed to make CNNs efficient like grouped, shuffled, depth-wise separable convolutions. We study the effectiveness of these techniques on a real-time semantic segmentation architecture like ERFNet for improving run time by over 5X. We apply these techniques to CNN layers partially or fully and evaluate the testing accuracies on Cityscapes dataset. We obtain accuracy vs parameters/FLOPs trade offs, giving accuracy scores for models that can run under specified runtime budgets. We further propose a novel training procedure which starts out with a dense convolution but gradually evolves towards a grouped convolution. We show that our proposed training method and efficient architecture design can improve accuracies by over 8% with depth wise separable convolutions applied on the encoder of ERFNet and attaching a light weight decoder. This results in a model which has a 5X improvement in FLOPs while only suffering a 4% degradation in accuracy with respect to ERFNet.