 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Hybrid and Ensemble Models for Multiclass Prediction of Mental Health Status on Social Media
Dec 19, 2022



In recent years, there has been a surge of interest in research on automatic mental health detection (MHD) from social media data leveraging advances in natural language processing and machine learning techniques. While significant progress has been achieved in this interdisciplinary research area, the vast majority of work has treated MHD as a binary classification task. The multiclass classification setup is, however, essential if we are to uncover the subtle differences among the statistical patterns of language use associated with particular mental health conditions. Here, we report on experiments aimed at predicting six conditions (anxiety, attention deficit hyperactivity disorder, bipolar disorder, post-traumatic stress disorder, depression, and psychological stress) from Reddit social media posts. We explore and compare the performance of hybrid and ensemble models leveraging transformer-based architectures (BERT and RoBERTa) and BiLSTM neural networks trained on within-text distributions of a diverse set of linguistic features. This set encompasses measures of syntactic complexity, lexical sophistication and diversity, readability, and register-specific ngram frequencies, as well as sentiment and emotion lexicons. In addition, we conduct feature ablation experiments to investigate which types of features are most indicative of particular mental health conditions.
Improving the Generalizability of Text-Based Emotion Detection by Leveraging Transformers with Psycholinguistic Features
Dec 19, 2022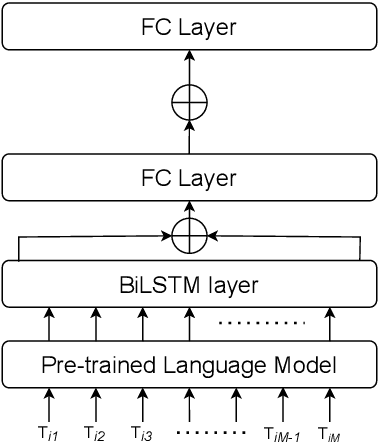
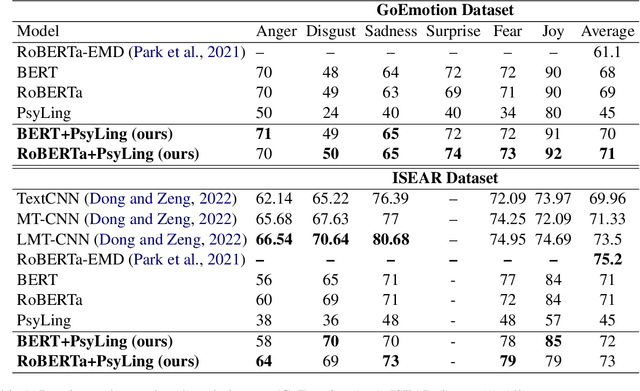
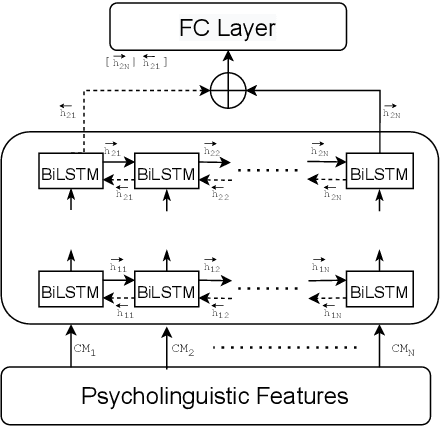
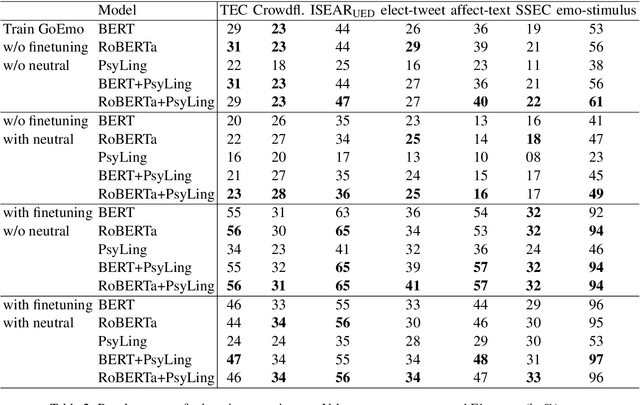
In recent years, there has been increased interest in building predictive models that harness natural language processing and machine learning techniques to detect emotions from various text sources, including social media posts, micro-blogs or news articles. Yet, deployment of such models in real-world sentiment and emotion applications faces challenges, in particular poor out-of-domain generalizability. This is likely due to domain-specific differences (e.g., topics, communicative goals, and annotation schemes) that make transfer between different models of emotion recognition difficult. In this work we propose approaches for text-based emotion detection that leverage transformer models (BERT and RoBERTa) in combination with Bidirectional Long Short-Term Memory (BiLSTM) networks trained on a comprehensive set of psycholinguistic features. First, we evaluate the performance of our models within-domain on two benchmark datasets: GoEmotion and ISEAR. Second, we conduct transfer learning experiments on six datasets from the Unified Emotion Dataset to evaluate their out-of-domain robustness. We find that the proposed hybrid models improve the ability to generalize to out-of-distribution data compared to a standard transformer-based approach. Moreover, we observe that these models perform competitively on in-domain data.
Pushing on Personality Detection from Verbal Behavior: A Transformer Meets Text Contours of Psycholinguistic Features
Apr 10, 2022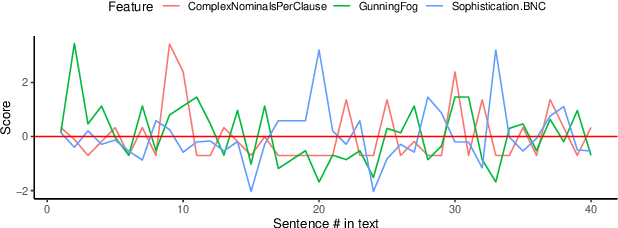
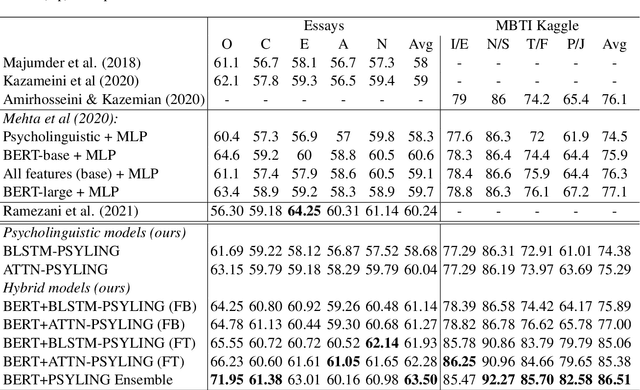
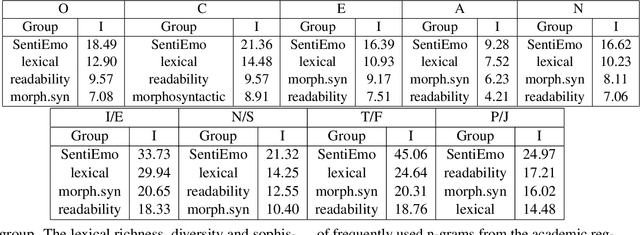
Research at the intersection of personality psychology, computer science, and linguistics has recently focused increasingly on modeling and predicting personality from language use. We report two major improvements in predicting personality traits from text data: (1) to our knowledge, the most comprehensive set of theory-based psycholinguistic features and (2) hybrid models that integrate a pre-trained Transformer Language Model BERT and Bidirectional Long Short-Term Memory (BLSTM) networks trained on within-text distributions ('text contours') of psycholinguistic features. We experiment with BLSTM models (with and without Attention) and with two techniques for applying pre-trained language representations from the transformer model - 'feature-based' and 'fine-tuning'. We evaluate the performance of the models we built on two benchmark datasets that target the two dominant theoretical models of personality: the Big Five Essay dataset and the MBTI Kaggle dataset. Our results are encouraging as our models outperform existing work on the same datasets. More specifically, our models achieve improvement in classification accuracy by 2.9% on the Essay dataset and 8.28% on the Kaggle MBTI dataset. In addition, we perform ablation experiments to quantify the impact of different categories of psycholinguistic features in the respective personality prediction models.
Prediction of Listener Perception of Argumentative Speech in a Crowdsourced Dataset Using (Psycho-)Linguistic and Fluency Features
Nov 30, 2021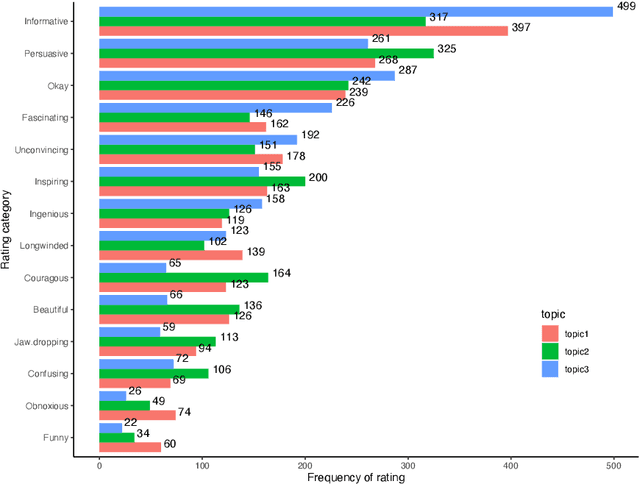
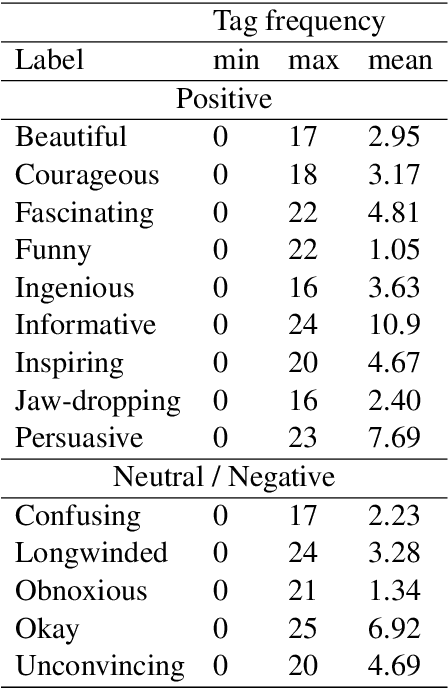
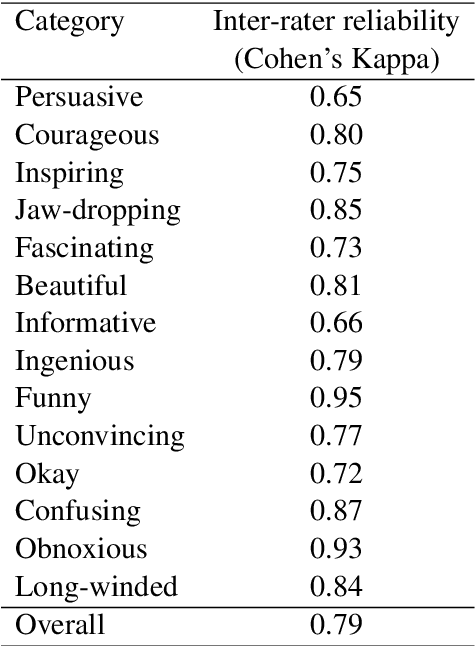
One of the key communicative competencies is the ability to maintain fluency in monologic speech and the ability to produce sophisticated language to argue a position convincingly. In this paper we aim to predict TED talk-style affective ratings in a crowdsourced dataset of argumentative speech consisting of 7 hours of speech from 110 individuals. The speech samples were elicited through task prompts relating to three debating topics. The samples received a total of 2211 ratings from 737 human raters pertaining to 14 affective categories. We present an effective approach to the classification task of predicting these categories through fine-tuning a model pre-trained on a large dataset of TED talks public speeches. We use a combination of fluency features derived from a state-of-the-art automatic speech recognition system and a large set of human-interpretable linguistic features obtained from an automatic text analysis system. Classification accuracy was greater than 60% for all 14 rating categories, with a peak performance of 72% for the rating category 'informative'. In a secondary experiment, we determined the relative importance of features from different groups using SP-LIME.