 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction of Listener Perception of Argumentative Speech in a Crowdsourced Dataset Using (Psycho-)Linguistic and Fluency Features
Paper and Code
Nov 30, 2021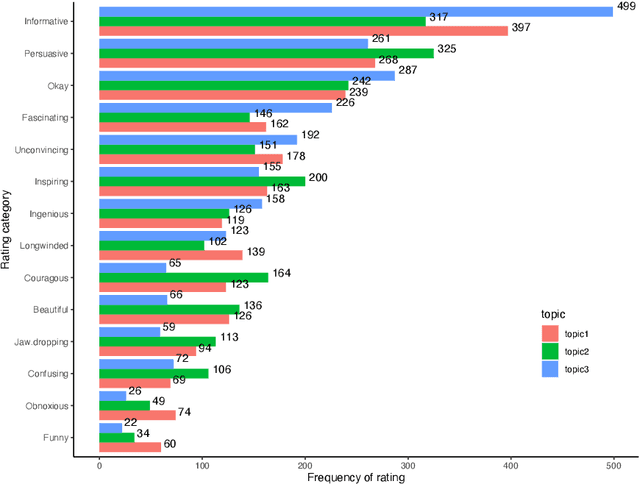
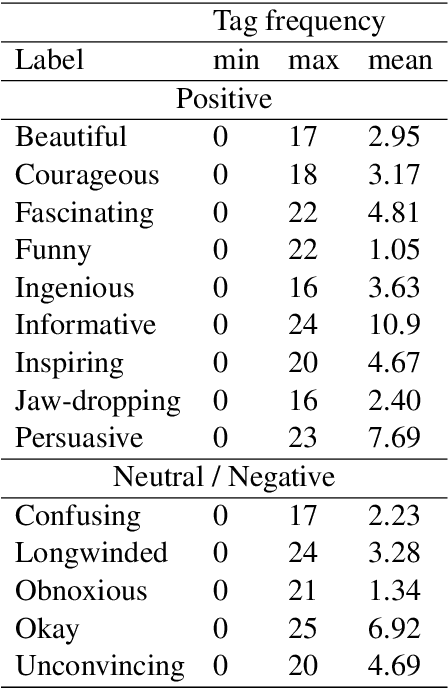
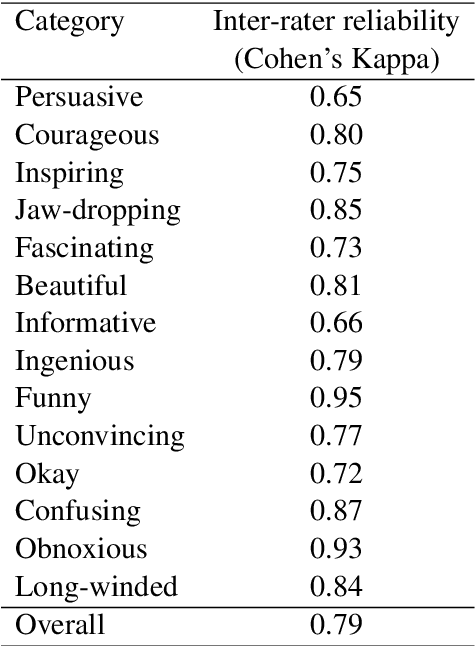
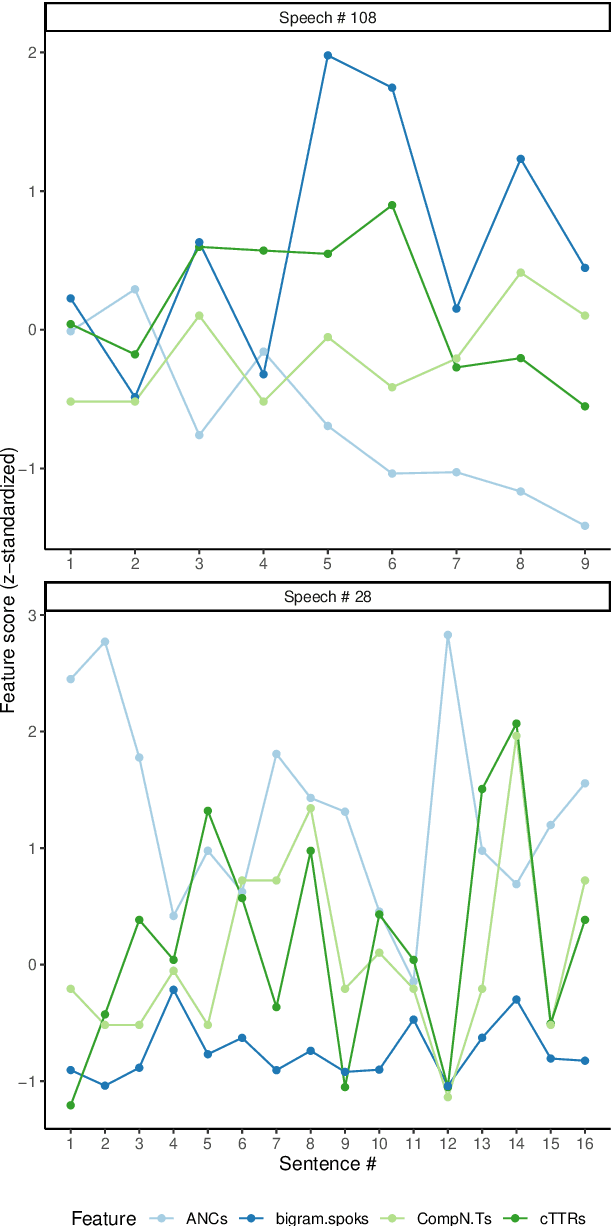
One of the key communicative competencies is the ability to maintain fluency in monologic speech and the ability to produce sophisticated language to argue a position convincingly. In this paper we aim to predict TED talk-style affective ratings in a crowdsourced dataset of argumentative speech consisting of 7 hours of speech from 110 individuals. The speech samples were elicited through task prompts relating to three debating topics. The samples received a total of 2211 ratings from 737 human raters pertaining to 14 affective categories. We present an effective approach to the classification task of predicting these categories through fine-tuning a model pre-trained on a large dataset of TED talks public speeches. We use a combination of fluency features derived from a state-of-the-art automatic speech recognition system and a large set of human-interpretable linguistic features obtained from an automatic text analysis system. Classification accuracy was greater than 60% for all 14 rating categories, with a peak performance of 72% for the rating category 'informative'. In a secondary experiment, we determined the relative importance of features from different groups using SP-LIME.