 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing on Personality Detection from Verbal Behavior: A Transformer Meets Text Contours of Psycholinguistic Features
Paper and Code
Apr 10, 2022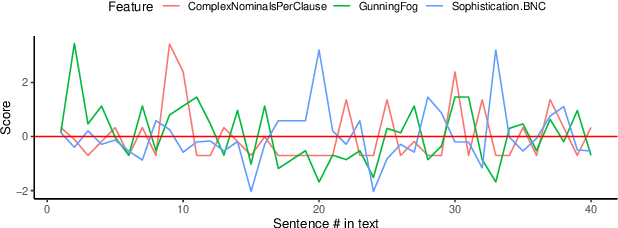
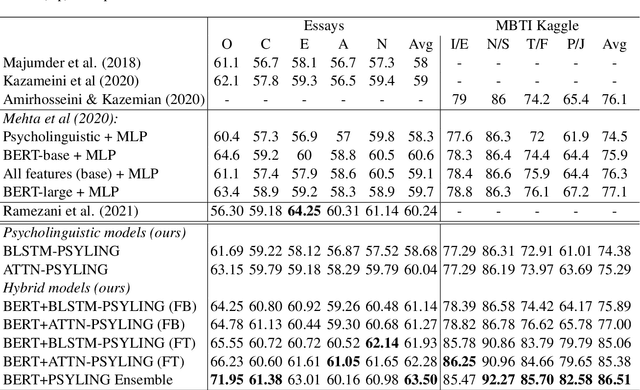
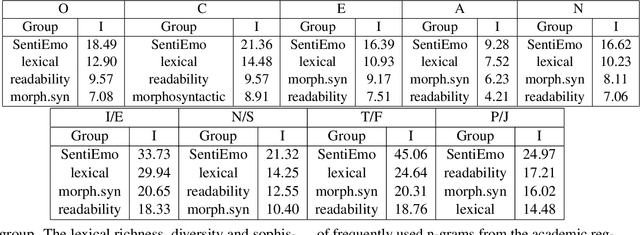
Research at the intersection of personality psychology, computer science, and linguistics has recently focused increasingly on modeling and predicting personality from language use. We report two major improvements in predicting personality traits from text data: (1) to our knowledge, the most comprehensive set of theory-based psycholinguistic features and (2) hybrid models that integrate a pre-trained Transformer Language Model BERT and Bidirectional Long Short-Term Memory (BLSTM) networks trained on within-text distributions ('text contours') of psycholinguistic features. We experiment with BLSTM models (with and without Attention) and with two techniques for applying pre-trained language representations from the transformer model - 'feature-based' and 'fine-tuning'. We evaluate the performance of the models we built on two benchmark datasets that target the two dominant theoretical models of personality: the Big Five Essay dataset and the MBTI Kaggle dataset. Our results are encouraging as our models outperform existing work on the same datasets. More specifically, our models achieve improvement in classification accuracy by 2.9% on the Essay dataset and 8.28% on the Kaggle MBTI dataset. In addition, we perform ablation experiments to quantify the impact of different categories of psycholinguistic features in the respective personality prediction models.