 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Writes the Review, Human or AI?
May 30, 2024


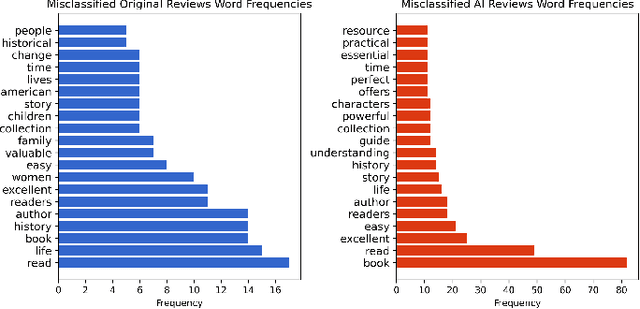
With the increasing use of Artificial Intelligence in Natural Language Processing, concerns have been raised regarding the detection of AI-generated text in various domains. This study aims to investigate this issue by proposing a methodology to accurately distinguish AI-generated and human-written book reviews. Our approach utilizes transfer learning, enabling the model to identify generated text across different topics while improving its ability to detect variations in writing style and vocabulary. To evaluate the effectiveness of the proposed methodology, we developed a dataset consisting of real book reviews and AI-generated reviews using the recently proposed Vicuna open-source language model. The experimental results demonstrate that it is feasible to detect the original source of text, achieving an accuracy rate of 96.86%. Our efforts are oriented toward the exploration of the capabilities and limitations of Large Language Models in the context of text identification. Expanding our knowledge in these aspects will be valuable for effectively navigating similar models in the future and ensuring the integrity and authenticity of human-generated content.
Detection of Fake Generated Scientific Abstracts
Apr 12, 2023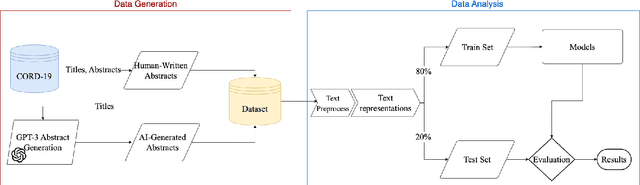
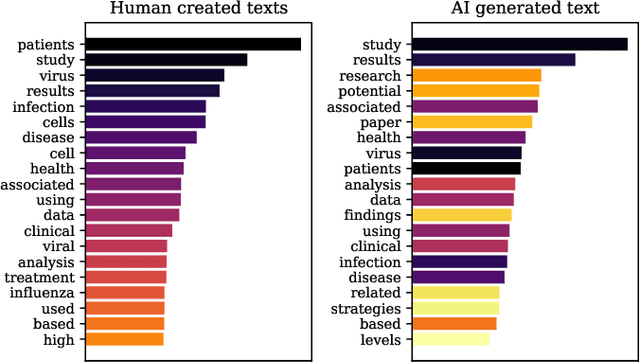
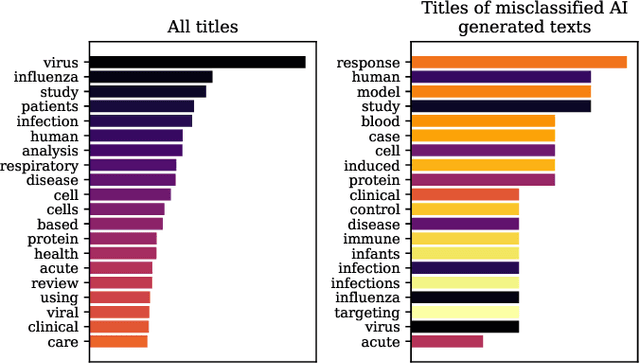
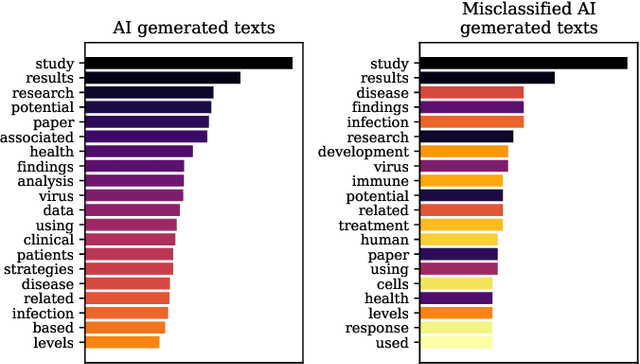
The widespread adoption of Large Language Models and publicly available ChatGPT has marked a significant turning point in the integration of Artificial Intelligence into people's everyday lives. The academic community has taken notice of these technological advancements and has expressed concerns regarding the difficulty of discriminating between what is real and what is artificially generated. Thus, researchers have been working on developing effective systems to identify machine-generated text. In this study, we utilize the GPT-3 model to generate scientific paper abstracts through Artificial Intelligence and explore various text representation methods when combined with Machine Learning models with the aim of identifying machine-written text. We analyze the models' performance and address several research questions that rise during the analysis of the results. By conducting this research, we shed light on the capabilities and limitations of Artificial Intelligence generated text.
Supervised Dimensionality Reduction and Classification with Convolutional Autoencoders
Aug 30, 2022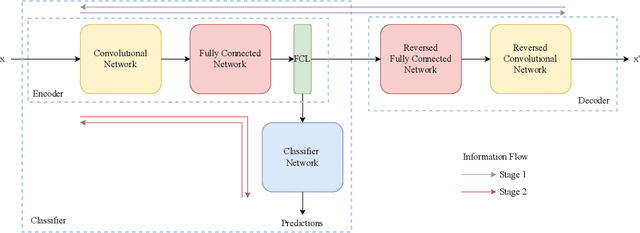
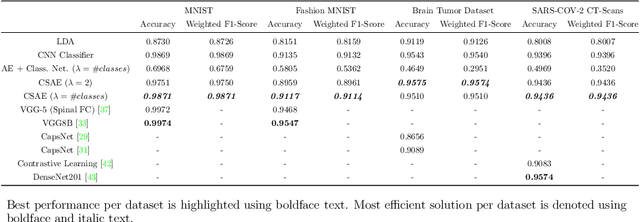

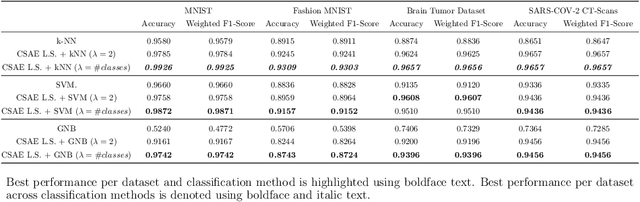
The joint optimization of the reconstruction and classification error is a hard non convex problem, especially when a non linear mapping is utilized. In order to overcome this obstacle, a novel optimization strategy is proposed, in which a Convolutional Autoencoder for dimensionality reduction and a classifier composed by a Fully Connected Network, are combined to simultaneously produce supervised dimensionality reduction and predictions. It turned out that this methodology can also be greatly beneficial in enforcing explainability of deep learning architectures. Additionally, the resulting Latent Space, optimized for the classification task, can be utilized to improve traditional, interpretable classification algorithms. The experimental results, showed that the proposed methodology achieved competitive results against the state of the art deep learning methods, while being much more efficient in terms of parameter count. Finally, it was empirically justified that the proposed methodology introduces advanced explainability regarding, not only the data structure through the produced latent space, but also about the classification behaviour.
Approximate kNN Classification for Biomedical Data
Dec 03, 2020
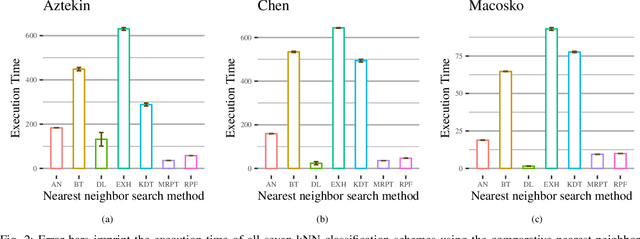
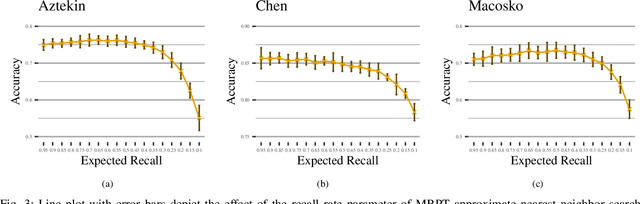
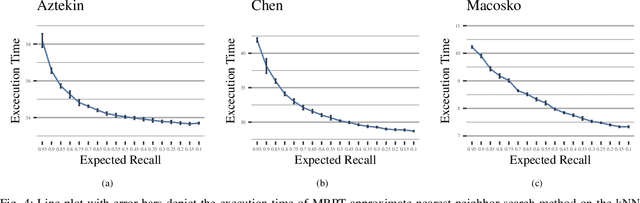
We are in the era where the Big Data analytics has changed the way of interpreting the various biomedical phenomena, and as the generated data increase, the need for new machine learning methods to handle this evolution grows. An indicative example is the single-cell RNA-seq (scRNA-seq), an emerging DNA sequencing technology with promising capabilities but significant computational challenges due to the large-scaled generated data. Regarding the classification process for scRNA-seq data, an appropriate method is the k Nearest Neighbor (kNN) classifier since it is usually utilized for large-scale prediction tasks due to its simplicity, minimal parameterization, and model-free nature. However, the ultra-high dimensionality that characterizes scRNA-seq impose a computational bottleneck, while prediction power can be affected by the "Curse of Dimensionality". In this work, we proposed the utilization of approximate nearest neighbor search algorithms for the task of kNN classification in scRNA-seq data focusing on a particular methodology tailored for high dimensional data. We argue that even relaxed approximate solutions will not affect the prediction performance significantly. The experimental results confirm the original assumption by offering the potential for broader applicability.
Real Time Sentiment Change Detection of Twitter Data Streams
Apr 02, 2018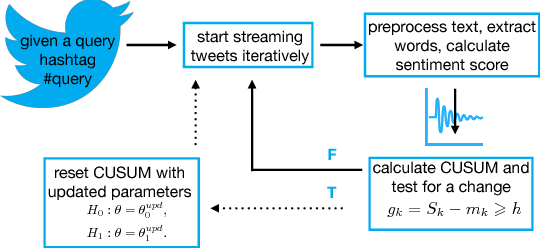

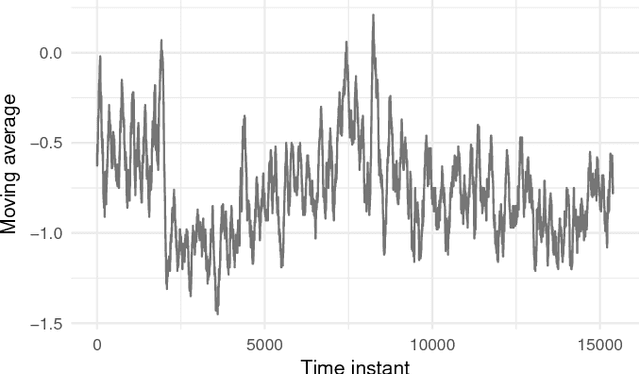
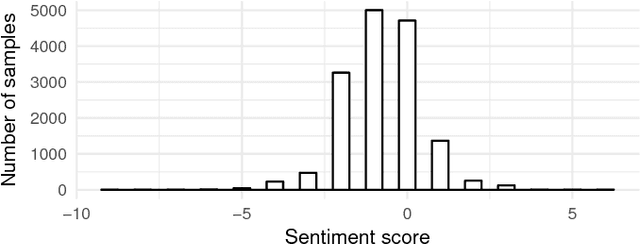
In the past few years, there has been a huge growth in Twitter sentiment analysis having already provided a fair amount of research on sentiment detection of public opinion among Twitter users. Given the fact that Twitter messages are generated constantly with dizzying rates, a huge volume of streaming data is created, thus there is an imperative need for accurate methods for knowledge discovery and mining of this information. Although there exists a plethora of twitter sentiment analysis methods in the recent literature, the researchers have shifted to real-time sentiment identification on twitter streaming data, as expected. A major challenge is to deal with the Big Data challenges arising in Twitter streaming applications concerning both Volume and Velocity. Under this perspective, in this paper, a methodological approach based on open source tools is provided for real-time detection of changes in sentiment that is ultra efficient with respect to both memory consumption and computational cost. This is achieved by iteratively collecting tweets in real time and discarding them immediately after their process. For this purpose, we employ the Lexicon approach for sentiment characterizations, while change detection is achieved through appropriate control charts that do not require historical information. We believe that the proposed methodology provides the trigger for a potential large-scale monitoring of threads in an attempt to discover fake news spread or propaganda efforts in their early stages. Our experimental real-time analysis based on a recent hashtag provides evidence that the proposed approach can detect meaningful sentiment changes across a hashtags lifetime.
Convolutional Neural Networks for Toxic Comment Classification
Feb 27, 2018



Flood of information is produced in a daily basis through the global Internet usage arising from the on-line interactive communications among users. While this situation contributes significantly to the quality of human life, unfortunately it involves enormous dangers, since on-line texts with high toxicity can cause personal attacks, on-line harassment and bullying behaviors. This has triggered both industrial and research community in the last few years while there are several tries to identify an efficient model for on-line toxic comment prediction. However, these steps are still in their infancy and new approaches and frameworks are required. On parallel, the data explosion that appears constantly, makes the construction of new machine learning computational tools for managing this information, an imperative need. Thankfully advances in hardware, cloud computing and big data management allow the development of Deep Learning approaches appearing very promising performance so far. For text classification in particular the use of Convolutional Neural Networks (CNN) have recently been proposed approaching text analytics in a modern manner emphasizing in the structure of words in a document. In this work, we employ this approach to discover toxic comments in a large pool of documents provided by a current Kaggle's competition regarding Wikipedia's talk page edits. To justify this decision we choose to compare CNNs against the traditional bag-of-words approach for text analysis combined with a selection of algorithms proven to be very effective in text classification. The reported results provide enough evidence that CNN enhance toxic comment classification reinforcing research interest towards this direction.
Minimum Density Hyperplanes
Sep 28, 2016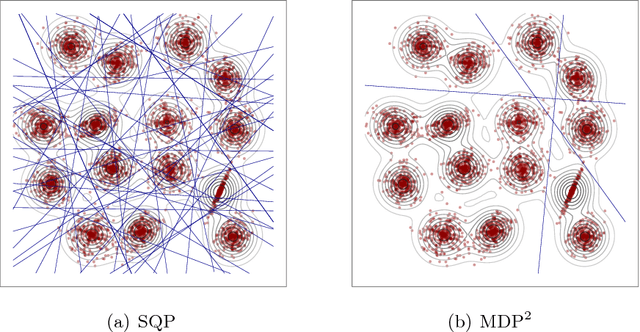



Associating distinct groups of objects (clusters) with contiguous regions of high probability density (high-density clusters), is central to many statistical and machine learning approaches to the classification of unlabelled data. We propose a novel hyperplane classifier for clustering and semi-supervised classification which is motivated by this objective. The proposed minimum density hyperplane minimises the integral of the empirical probability density function along it, thereby avoiding intersection with high density clusters. We show that the minimum density and the maximum margin hyperplanes are asymptotically equivalent, thus linking this approach to maximum margin clustering and semi-supervised support vector classifiers. We propose a projection pursuit formulation of the associated optimisation problem which allows us to find minimum density hyperplanes efficiently in practice, and evaluate its performance on a range of benchmark datasets. The proposed approach is found to be very competitive with state of the art methods for clustering and semi-supervised classification.