 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Writes the Review, Human or AI?
Paper and Code
May 30, 2024


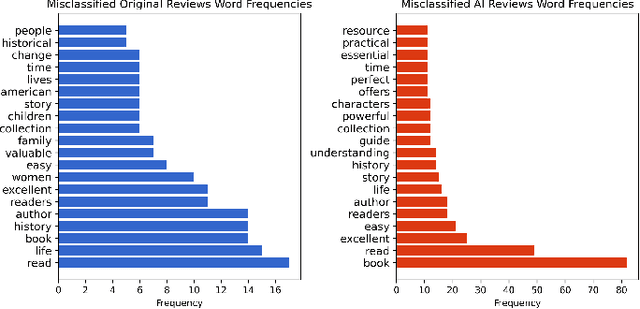
With the increasing use of Artificial Intelligence in Natural Language Processing, concerns have been raised regarding the detection of AI-generated text in various domains. This study aims to investigate this issue by proposing a methodology to accurately distinguish AI-generated and human-written book reviews. Our approach utilizes transfer learning, enabling the model to identify generated text across different topics while improving its ability to detect variations in writing style and vocabulary. To evaluate the effectiveness of the proposed methodology, we developed a dataset consisting of real book reviews and AI-generated reviews using the recently proposed Vicuna open-source language model. The experimental results demonstrate that it is feasible to detect the original source of text, achieving an accuracy rate of 96.86%. Our efforts are oriented toward the exploration of the capabilities and limitations of Large Language Models in the context of text identification. Expanding our knowledge in these aspects will be valuable for effectively navigating similar models in the future and ensuring the integrity and authenticity of human-generated content.