 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter than Average: Spatially-Aware Aggregation of Segmentation Uncertainty Improves Downstream Performance
Mar 31, 2026Uncertainty Quantification (UQ) is crucial for ensuring the reliability of automated image segmentations in safety-critical domains like biomedical image analysis or autonomous driving. In segmentation, UQ generates pixel-wise uncertainty scores that must be aggregated into image-level scores for downstream tasks like Out-of-Distribution (OoD) or failure detection. Despite routine use of aggregation strategies, their properties and impact on downstream task performance have not yet been comprehensively studied. Global Average is the default choice, yet it does not account for spatial and structural features of segmentation uncertainty. Alternatives like patch-, class- and threshold-based strategies exist, but lack systematic comparison, leading to inconsistent reporting and unclear best practices. We address this gap by (1) formally analyzing properties, limitations, and pitfalls of common strategies; (2) proposing novel strategies that incorporate spatial uncertainty structure and (3) benchmarking their performance on OoD and failure detection across ten datasets that vary in image geometry and structure. We find that aggregators leveraging spatial structure yield stronger performance in both downstream tasks studied. However, the performance of individual aggregators depends heavily on dataset characteristics, so we (4) propose a meta-aggregator that integrates multiple aggregators and performs robustly across datasets.
Deep Nonparametric Conditional Independence Tests for Images
Nov 09, 2024Conditional independence tests (CITs) test for conditional dependence between random variables. As existing CITs are limited in their applicability to complex, high-dimensional variables such as images, we introduce deep nonparametric CITs (DNCITs). The DNCITs combine embedding maps, which extract feature representations of high-dimensional variables, with nonparametric CITs applicable to these feature representations. For the embedding maps, we derive general properties on their parameter estimators to obtain valid DNCITs and show that these properties include embedding maps learned through (conditional) unsupervised or transfer learning. For the nonparametric CITs, appropriate tests are selected and adapted to be applicable to feature representations. Through simulations, we investigate the performance of the DNCITs for different embedding maps and nonparametric CITs under varying confounder dimensions and confounder relationships. We apply the DNCITs to brain MRI scans and behavioral traits, given confounders, of healthy individuals from the UK Biobank (UKB), confirming null results from a number of ambiguous personality neuroscience studies with a larger data set and with our more powerful tests. In addition, in a confounder control study, we apply the DNCITs to brain MRI scans and a confounder set to test for sufficient confounder control, leading to a potential reduction in the confounder dimension under improved confounder control compared to existing state-of-the-art confounder control studies for the UKB. Finally, we provide an R package implementing the DNCITs.
Classification ensembles for multivariate functional data with application to mouse movements in web surveys
May 26, 2022


We propose new ensemble models for multivariate functional data classification as combinations of semi-metric-based weak learners. Our models extend current semi-metric-type methods from the univariate to the multivariate case, propose new semi-metrics to compute distances between functions, and consider more flexible options for combining weak learners using stacked generalisation methods. We apply these ensemble models to identify respondents' difficulty with survey questions, with the aim to improve survey data quality. As predictors of difficulty, we use mouse movement trajectories from the respondents' interaction with a web survey, in which several questions were manipulated to create two scenarios with different levels of difficulty.
Functional additive regression on shape and form manifolds of planar curves
Sep 21, 2021

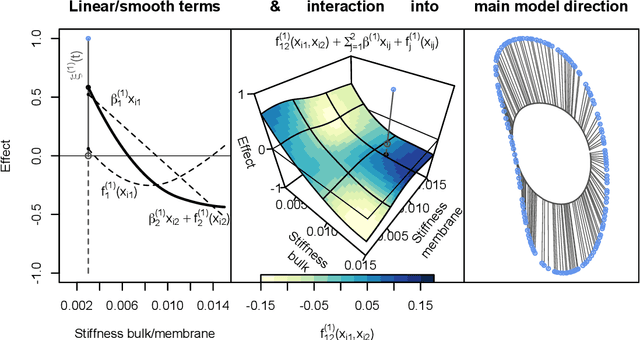

Defining shape and form as equivalence classes under translation, rotation and -- for shapes -- also scale, we extend generalized additive regression to models for the shape/form of planar curves or landmark configurations. The model respects the resulting quotient geometry of the response, employing the squared geodesic distance as loss function and a geodesic response function mapping the additive predictor to the shape/form space. For fitting the model, we propose a Riemannian $L_2$-Boosting algorithm well-suited for a potentially large number of possibly parameter-intensive model terms, which also yiels automated model selection. We provide novel intuitively interpretable visualizations for (even non-linear) covariate effects in the shape/form space via suitable tensor based factorizations. The usefulness of the proposed framework is illustrated in an analysis of 1) astragalus shapes of wild and domesticated sheep and 2) cell forms generated in a biophysical model, as well as 3) in a realistic simulation study with response shapes and forms motivated from a dataset on bottle outlines.
Predicting respondent difficulty in web surveys: A machine-learning approach based on mouse movement features
Nov 05, 2020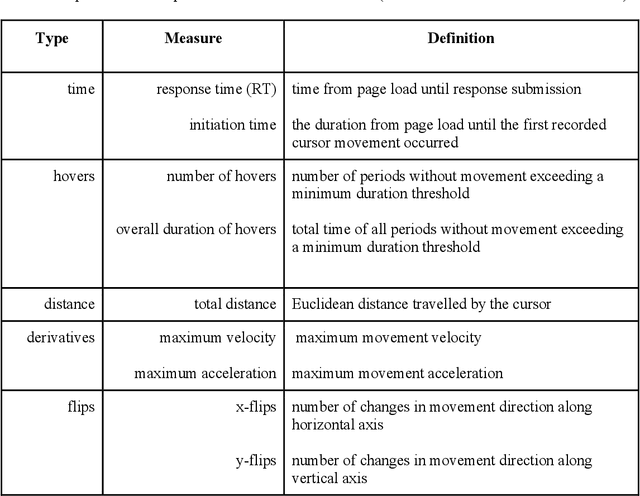
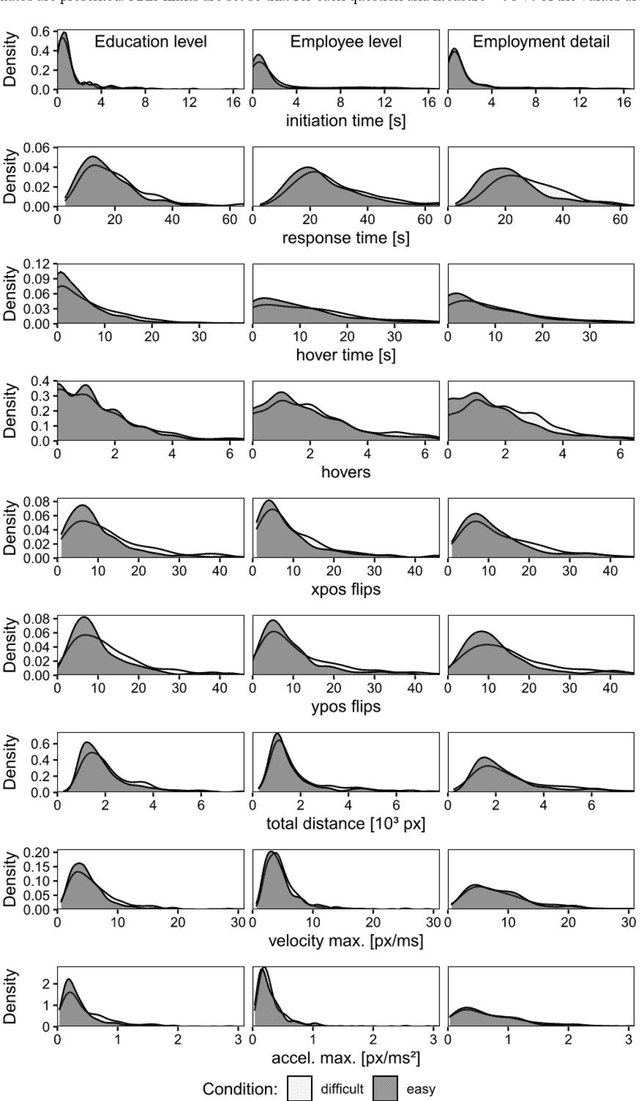
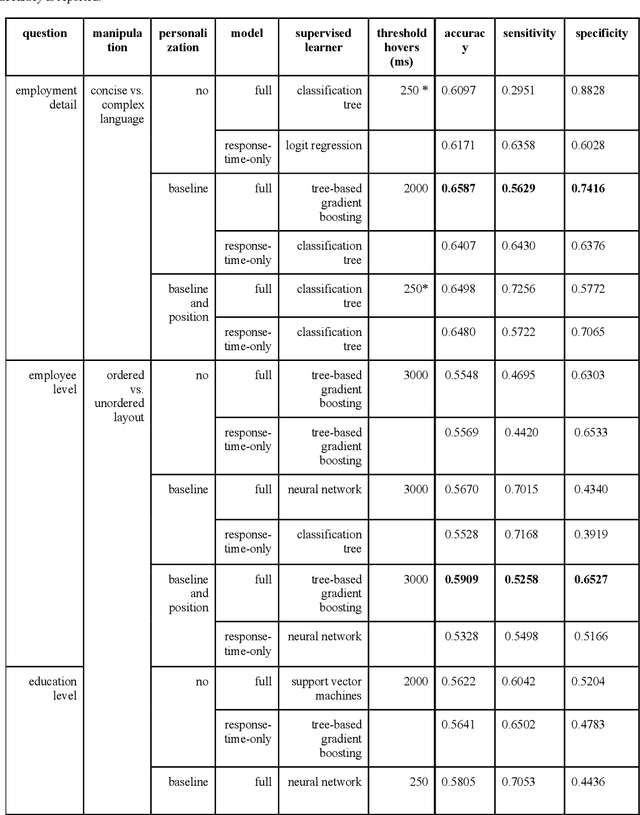
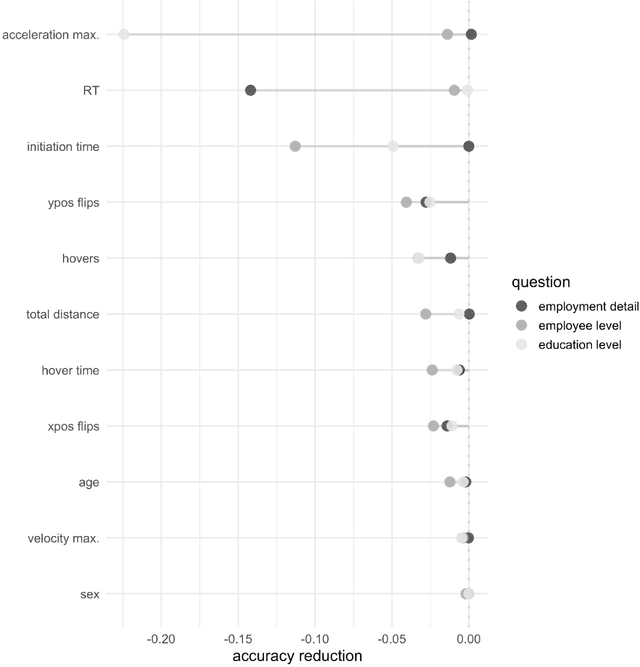
A central goal of survey research is to collect robust and reliable data from respondents. However, despite researchers' best efforts in designing questionnaires, respondents may experience difficulty understanding questions' intent and therefore may struggle to respond appropriately. If it were possible to detect such difficulty, this knowledge could be used to inform real-time interventions through responsive questionnaire design, or to indicate and correct measurement error after the fact. Previous research in the context of web surveys has used paradata, specifically response times, to detect difficulties and to help improve user experience and data quality. However, richer data sources are now available, in the form of the movements respondents make with the mouse, as an additional and far more detailed indicator for the respondent-survey interaction. This paper uses machine learning techniques to explore the predictive value of mouse-tracking data with regard to respondents' difficulty. We use data from a survey on respondents' employment history and demographic information, in which we experimentally manipulate the difficulty of several questions. Using features derived from the cursor movements, we predict whether respondents answered the easy or difficult version of a question, using and comparing several state-of-the-art supervised learning methods. In addition, we develop a personalization method that adjusts for respondents' baseline mouse behavior and evaluate its performance. For all three manipulated survey questions, we find that including the full set of mouse movement features improved prediction performance over response-time-only models in nested cross-validation. Accounting for individual differences in mouse movements led to further improvements.
Selective Inference for $L_2$-Boosting
Oct 29, 2018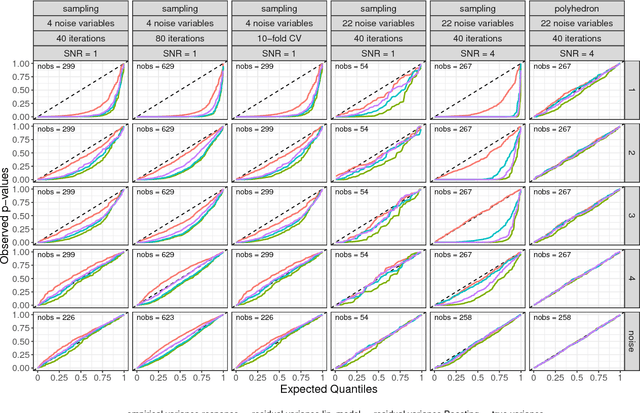

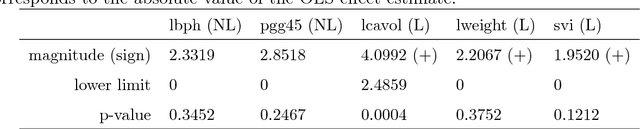
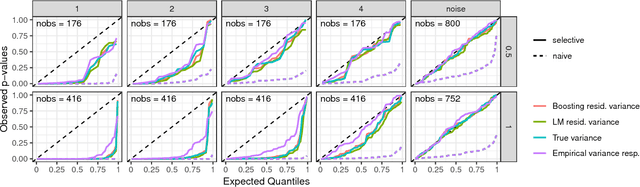
We adapt and extend several recent proposals for post-selection inference to transfer them to the component-wise functional gradient descent algorithm (CFGD) under normality assumption for model errors, also known as $L_2$-Boosting. The CFGD is one of the most versatile toolboxes to analyze data as it scales well to high-dimensional data sets, allows for a very flexible definition of additive regression models and incorporates inbuilt variable selection. Due to the iterative nature, which can repeatedly select the same component to update, a statistical inference framework for component-wise boosting algorithms requires adaptations of existing approaches; we propose tests and confidence intervals for linear, grouped and penalized additive model components selected by $L_2$-Boosting. Our concepts also transfer to slow-learning algorithms and to other selection techniques which restrict the response space to more complex sets than polyhedra. We apply our framework to an additive model for the prostate cancer data set to compare with previous results, and investigate the properties of our concepts in simulation studies.
Boosting Factor-Specific Functional Historical Models for the Detection of Synchronisation in Bioelectrical Signals
May 13, 2017



The link between different psychophysiological measures during emotion episodes is not well understood. To analyse the functional relationship between electroencephalography (EEG) and facial electromyography (EMG), we apply historical function-on-function regression models to EEG and EMG data that were simultaneously recorded from 24 participants while they were playing a computerised gambling task. Given the complexity of the data structure for this application, we extend simple functional historical models to models including random historical effects, factor-specific historical effects, and factor-specific random historical effects. Estimation is conducted by a component-wise gradient boosting algorithm, which scales well to large data sets and complex models.