 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Causal VAE: Robust Financial Time Series Generator
Nov 05, 2024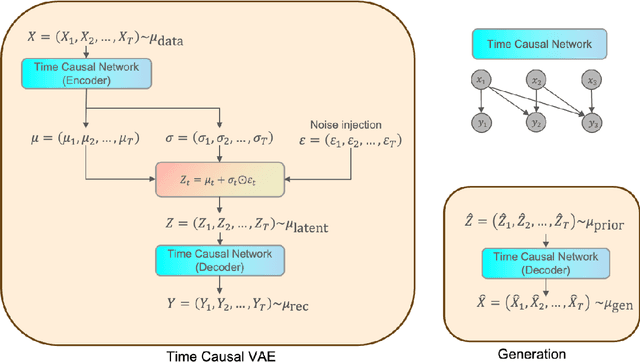

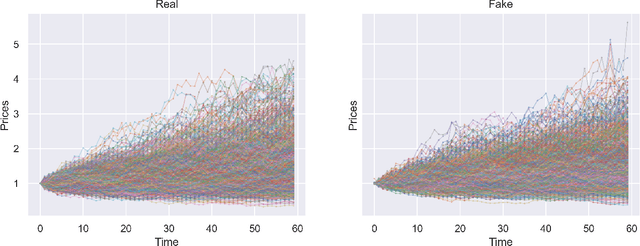

We build a time-causal variational autoencoder (TC-VAE) for robust generation of financial time series data. Our approach imposes a causality constraint on the encoder and decoder networks, ensuring a causal transport from the real market time series to the fake generated time series. Specifically, we prove that the TC-VAE loss provides an upper bound on the causal Wasserstein distance between market distributions and generated distributions. Consequently, the TC-VAE loss controls the discrepancy between optimal values of various dynamic stochastic optimization problems under real and generated distributions. To further enhance the model's ability to approximate the latent representation of the real market distribution, we integrate a RealNVP prior into the TC-VAE framework. Finally, extensive numerical experiments show that TC-VAE achieves promising results on both synthetic and real market data. This is done by comparing real and generated distributions according to various statistical distances, demonstrating the effectiveness of the generated data for downstream financial optimization tasks, as well as showcasing that the generated data reproduces stylized facts of real financial market data.
Instance-Dependent Generalization Bounds via Optimal Transport
Nov 07, 2022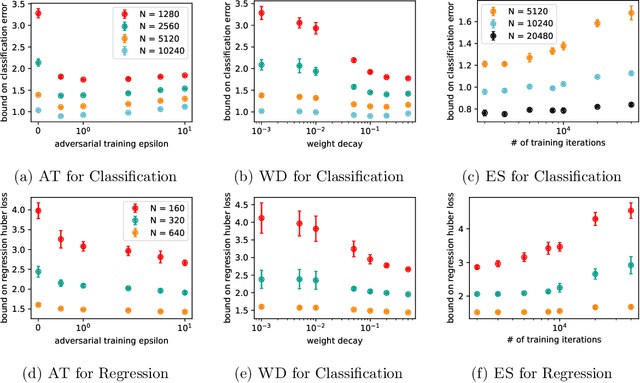
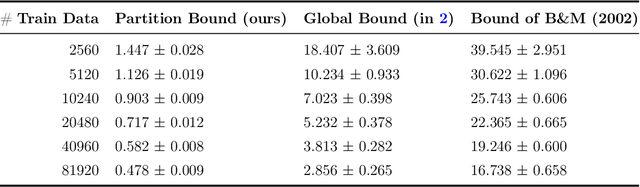
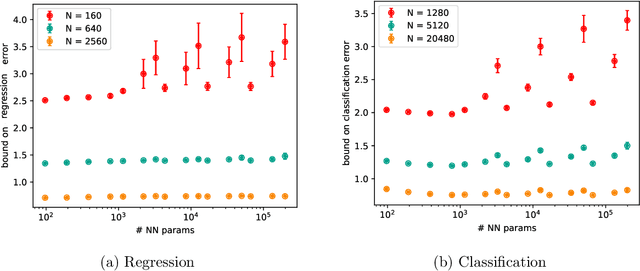

Existing generalization bounds fail to explain crucial factors that drive generalization of modern neural networks. Since such bounds often hold uniformly over all parameters, they suffer from over-parametrization, and fail to account for the strong inductive bias of initialization and stochastic gradient descent. As an alternative, we propose a novel optimal transport interpretation of the generalization problem. This allows us to derive instance-dependent generalization bounds that depend on the local Lipschitz regularity of the earned prediction function in the data space. Therefore, our bounds are agnostic to the parametrization of the model and work well when the number of training samples is much smaller than the number of parameters. With small modifications, our approach yields accelerated rates for data on low-dimensional manifolds, and guarantees under distribution shifts. We empirically analyze our generalization bounds for neural networks, showing that the bound values are meaningful and capture the effect of popular regularization methods during training.