 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot 3D Segmentation of Abdominal Organs in CT Scans Using Segment Anything Model 2: Adapting Video Tracking Capabilities for 3D Medical Imaging
Aug 12, 2024

Purpose: This study aimed to evaluate the zero-shot performance of Segment Anything Model 2 (SAM 2) in 3D segmentation of abdominal organs in CT scans, leveraging its video tracking capabilities for volumetric medical imaging. Materials and Methods: Using a subset of the TotalSegmentator CT dataset (n=123) from 8 different institutions, we assessed SAM 2's ability to segment 8 abdominal organs. Segmentation was initiated from three different Z-coordinate levels (caudal, mid, and cranial levels) of each organ. Performance was measured using the Dice similarity coefficient (DSC). We also analyzed organ volumes to contextualize the results. Results: As a zero-shot approach, larger organs with clear boundaries demonstrated high segmentation performance, with mean(median) DSCs as follows: liver 0.821(0.898), left kidney 0.870(0.921), right kidney 0.862(0.935), and spleen 0.891(0.932). Smaller or less defined structures showed lower performance: gallbladder 0.531(0.590), pancreas 0.361(0.359), and adrenal glands 0.203-0.308(0.109-0.231). Significant differences in DSC were observed depending on the starting initial slice of segmentation for different organs. A moderate positive correlation was observed between volume size and DSCs (Spearman's rs = 0.731, P <.001 at caudal-level). DSCs exhibited high variability within organs, ranging from near 0 to almost 1.0, indicating substantial inconsistency in segmentation performance between scans. Conclusion: SAM 2 demonstrated promising zero-shot performance in segmenting certain abdominal organs in CT scans, particularly larger organs with clear boundaries. The model's ability to segment previously unseen targets without additional training highlights its potential for cross-domain generalization in medical imaging. However, improvements are needed for smaller and less defined structures.
Playing the Werewolf game with artificial intelligence for language understanding
Feb 21, 2023
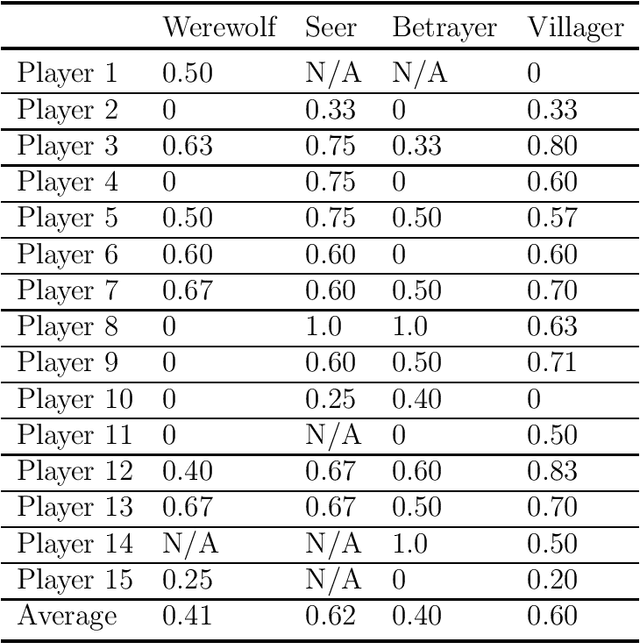
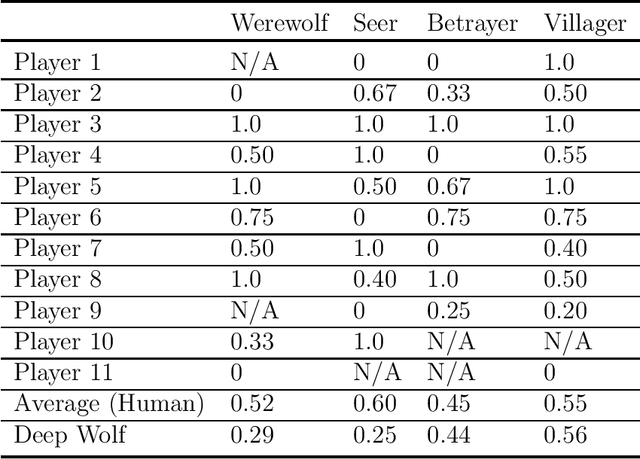
The Werewolf game is a social deduction game based on free natural language communication, in which players try to deceive others in order to survive. An important feature of this game is that a large portion of the conversations are false information, and the behavior of artificial intelligence (AI) in such a situation has not been widely investigated. The purpose of this study is to develop an AI agent that can play Werewolf through natural language conversations. First, we collected game logs from 15 human players. Next, we fine-tuned a Transformer-based pretrained language model to construct a value network that can predict a posterior probability of winning a game at any given phase of the game and given a candidate for the next action. We then developed an AI agent that can interact with humans and choose the best voting target on the basis of its probability from the value network. Lastly, we evaluated the performance of the agent by having it actually play the game with human players. We found that our AI agent, Deep Wolf, could play Werewolf as competitively as average human players in a villager or a betrayer role, whereas Deep Wolf was inferior to human players in a werewolf or a seer role. These results suggest that current language models have the capability to suspect what others are saying, tell a lie, or detect lies in conversations.