 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbation-based exploration methods in deep reinforcement learning
Nov 10, 2020

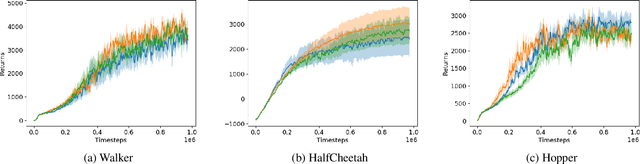

Recent research on structured exploration placed emphasis on identifying novel states in the state space and incentivizing the agent to revisit them through intrinsic reward bonuses. In this study, we question whether the performance boost demonstrated through these methods is indeed due to the discovery of structure in exploratory schedule of the agent or is the benefit largely attributed to the perturbations in the policy and reward space manifested in pursuit of structured exploration. In this study we investigate the effect of perturbations in policy and reward spaces on the exploratory behavior of the agent. We proceed to show that simple acts of perturbing the policy just before the softmax layer and introduction of sporadic reward bonuses into the domain can greatly enhance exploration in several domains of the arcade learning environment. In light of these findings, we recommend benchmarking any enhancements to structured exploration research against the backdrop of noisy exploration.
Training spiking neural networks using reinforcement learning
May 12, 2020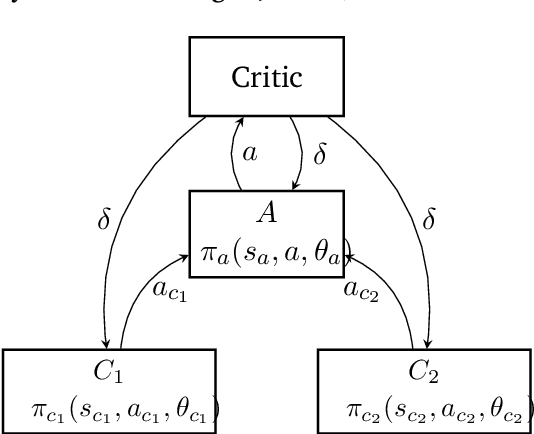
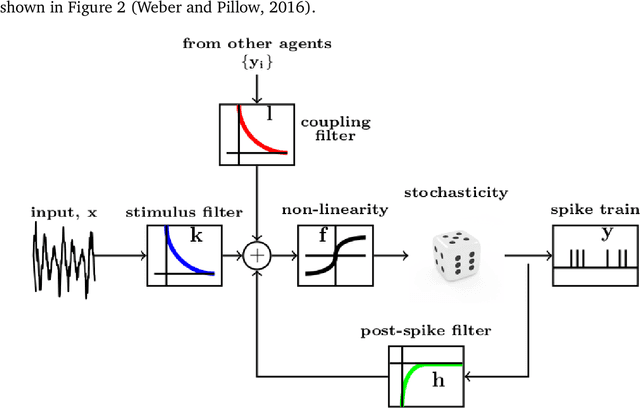

Neurons in the brain communicate with each other through discrete action spikes as opposed to continuous signal transmission in artificial neural networks. Therefore, the traditional techniques for optimization of parameters in neural networks which rely on the assumption of differentiability of activation functions are no longer applicable to modeling the learning processes in the brain. In this project, we propose biologically-plausible alternatives to backpropagation to facilitate the training of spiking neural networks. We primarily focus on investigating the candidacy of reinforcement learning (RL) rules in solving the spatial and temporal credit assignment problems to enable decision-making in complex tasks. In one approach, we consider each neuron in a multi-layer neural network as an independent RL agent forming a different representation of the feature space while the network as a whole forms the representation of the complex policy to solve the task at hand. In other approach, we apply the reparameterization trick to enable differentiation through stochastic transformations in spiking neural networks. We compare and contrast the two approaches by applying them to traditional RL domains such as gridworld, cartpole and mountain car. Further we also suggest variations and enhancements to enable future research in this area.
Reinforcement learning with a network of spiking agents
Nov 10, 2019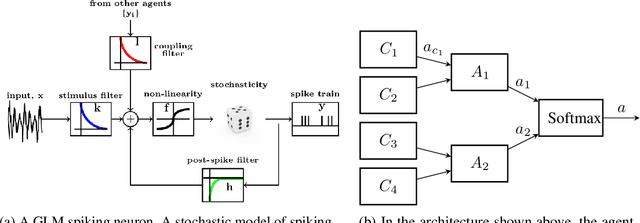
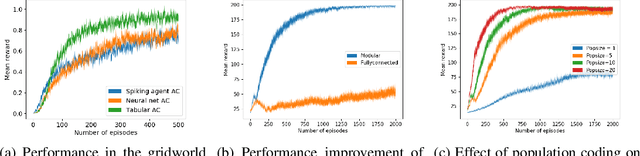
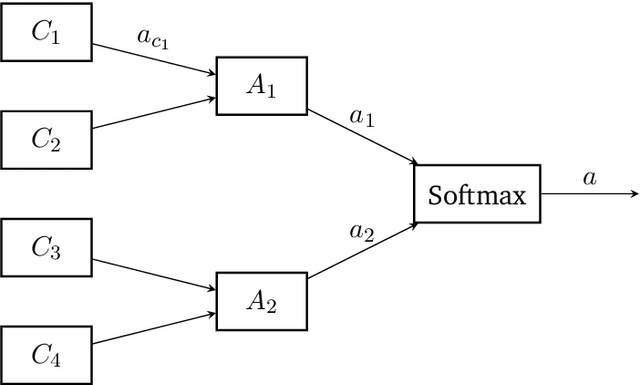
Neuroscientific theory suggests that dopaminergic neurons broadcast global reward prediction errors to large areas of the brain influencing the synaptic plasticity of the neurons in those regions. We build on this theory to propose a multi-agent learning framework with spiking neurons in the generalized linear model (GLM) formulation as agents, to solve reinforcement learning (RL) tasks. We show that a network of GLM spiking agents connected in a hierarchical fashion, where each spiking agent modulates its firing policy based on local information and a global prediction error, can learn complex action representations to solve RL tasks. We further show how leveraging principles of modularity and population coding inspired from the brain can help reduce variance in the learning updates making it a viable optimization technique.
A memory enhanced LSTM for modeling complex temporal dependencies
Oct 25, 2019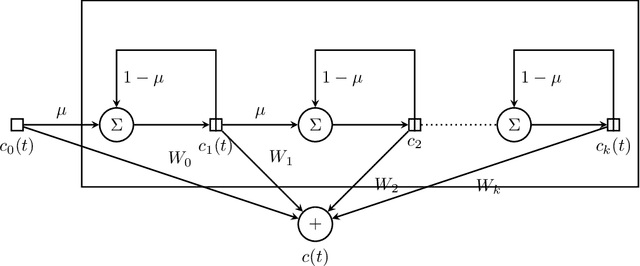
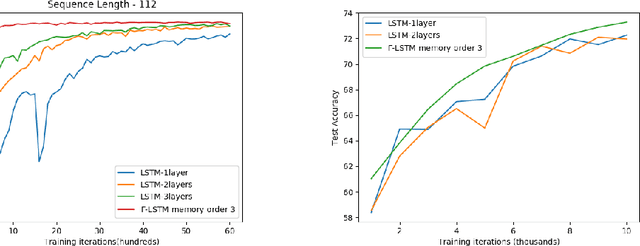
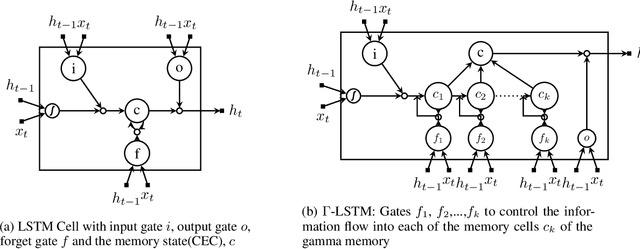

In this paper, we present Gamma-LSTM, an enhanced long short term memory (LSTM) unit, to enable learning of hierarchical representations through multiple stages of temporal abstractions. Gamma memory, a hierarchical memory unit, forms the central memory of Gamma-LSTM with gates to regulate the information flow into various levels of hierarchy, thus providing the unit with a control to pick the appropriate level of hierarchy to process the input at a given instant of time. We demonstrate better performance of Gamma-LSTM model regular and stacked LSTMs in two settings (pixel-by-pixel MNIST digit classification and natural language inference) placing emphasis on the ability to generalize over long sequences.
Lexicase selection in Learning Classifier Systems
Jul 10, 2019
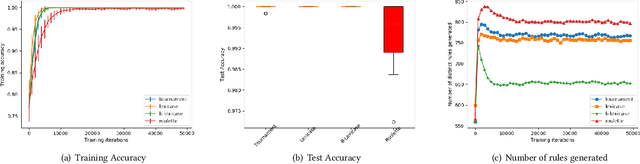
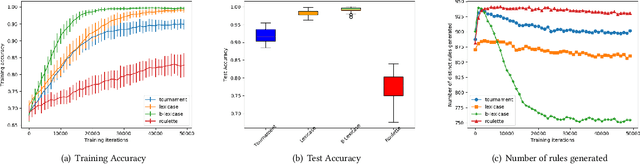
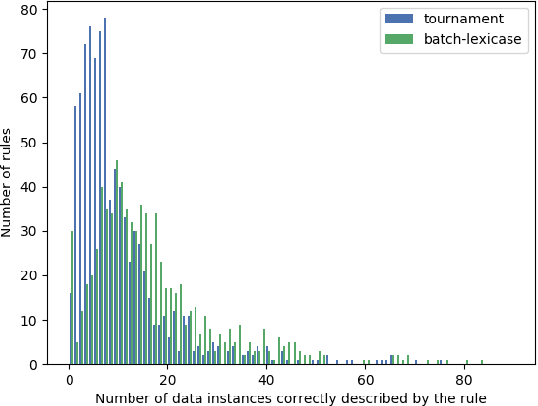
The lexicase parent selection method selects parents by considering performance on individual data points in random order instead of using a fitness function based on an aggregated data accuracy. While the method has demonstrated promise in genetic programming and more recently in genetic algorithms, its applications in other forms of evolutionary machine learning have not been explored. In this paper, we investigate the use of lexicase parent selection in Learning Classifier Systems (LCS) and study its effect on classification problems in a supervised setting. We further introduce a new variant of lexicase selection, called batch-lexicase selection, which allows for the tuning of selection pressure. We compare the two lexicase selection methods with tournament and fitness proportionate selection methods on binary classification problems. We show that batch-lexicase selection results in the creation of more generic rules which is favorable for generalization on future data. We further show that batch-lexicase selection results in better generalization in situations of partial or missing data.