 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining spiking neural networks using reinforcement learning
Paper and Code
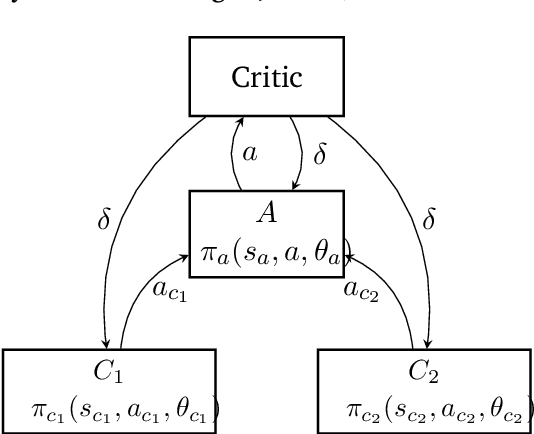
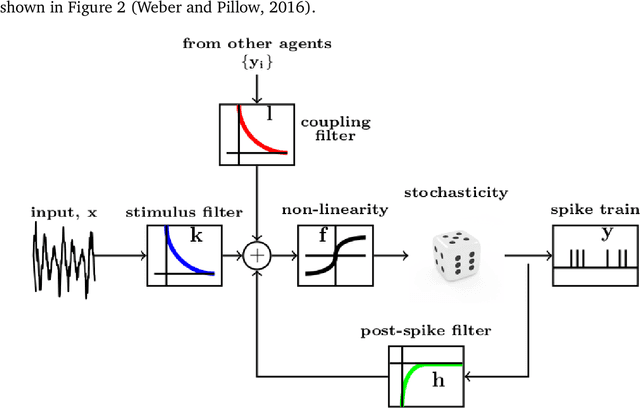
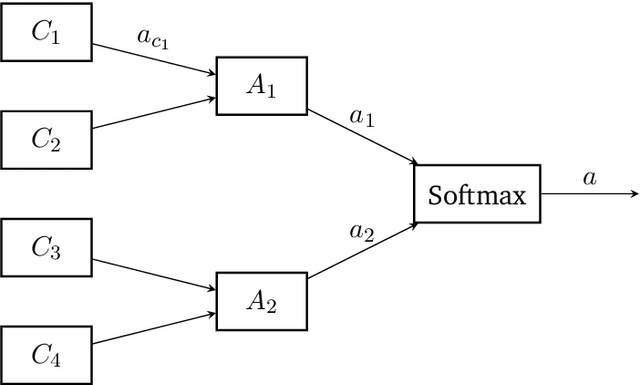

Neurons in the brain communicate with each other through discrete action spikes as opposed to continuous signal transmission in artificial neural networks. Therefore, the traditional techniques for optimization of parameters in neural networks which rely on the assumption of differentiability of activation functions are no longer applicable to modeling the learning processes in the brain. In this project, we propose biologically-plausible alternatives to backpropagation to facilitate the training of spiking neural networks. We primarily focus on investigating the candidacy of reinforcement learning (RL) rules in solving the spatial and temporal credit assignment problems to enable decision-making in complex tasks. In one approach, we consider each neuron in a multi-layer neural network as an independent RL agent forming a different representation of the feature space while the network as a whole forms the representation of the complex policy to solve the task at hand. In other approach, we apply the reparameterization trick to enable differentiation through stochastic transformations in spiking neural networks. We compare and contrast the two approaches by applying them to traditional RL domains such as gridworld, cartpole and mountain car. Further we also suggest variations and enhancements to enable future research in this area.