 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe multi-agent motion planning under uncertainty for drones using filtered reinforcement learning
Oct 31, 2023We consider the problem of safe multi-agent motion planning for drones in uncertain, cluttered workspaces. For this problem, we present a tractable motion planner that builds upon the strengths of reinforcement learning and constrained-control-based trajectory planning. First, we use single-agent reinforcement learning to learn motion plans from data that reach the target but may not be collision-free. Next, we use a convex optimization, chance constraints, and set-based methods for constrained control to ensure safety, despite the uncertainty in the workspace, agent motion, and sensing. The proposed approach can handle state and control constraints on the agents, and enforce collision avoidance among themselves and with static obstacles in the workspace with high probability. The proposed approach yields a safe, real-time implementable, multi-agent motion planner that is simpler to train than methods based solely on learning. Numerical simulations and experiments show the efficacy of the approach.
Distributionally Robust CVaR-Based Safety Filtering for Motion Planning in Uncertain Environments
Sep 16, 2023Safety is a core challenge of autonomous robot motion planning, especially in the presence of dynamic and uncertain obstacles. Many recent results use learning and deep learning-based motion planners and prediction modules to predict multiple possible obstacle trajectories and generate obstacle-aware ego robot plans. However, planners that ignore the inherent uncertainties in such predictions incur collision risks and lack formal safety guarantees. In this paper, we present a computationally efficient safety filtering solution to reduce the collision risk of ego robot motion plans using multiple samples of obstacle trajectory predictions. The proposed approach reformulates the collision avoidance problem by computing safe halfspaces based on obstacle sample trajectories using distributionally robust optimization (DRO) techniques. The safe halfspaces are used in a model predictive control (MPC)-like safety filter to apply corrections to the reference ego trajectory thereby promoting safer planning. The efficacy and computational efficiency of our approach are demonstrated through numerical simulations.
Risk-Averse RRT* Planning with Nonlinear Steering and Tracking Controllers for Nonlinear Robotic Systems Under Uncertainty
Mar 09, 2021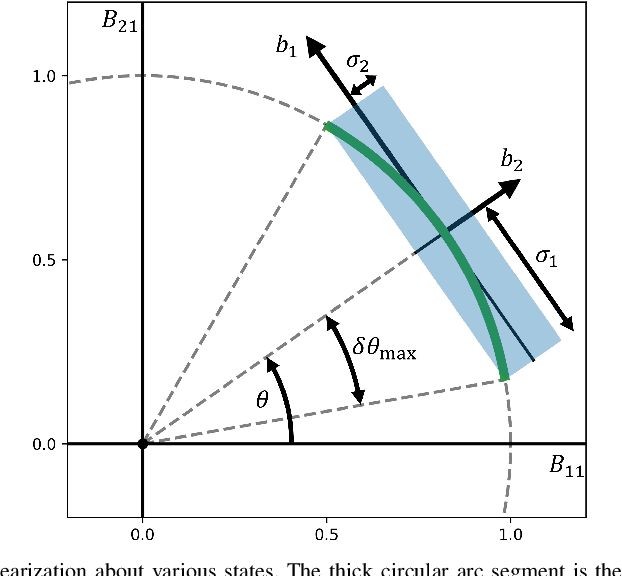
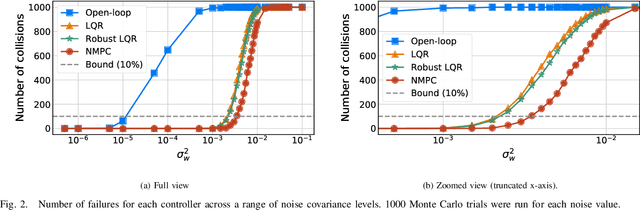

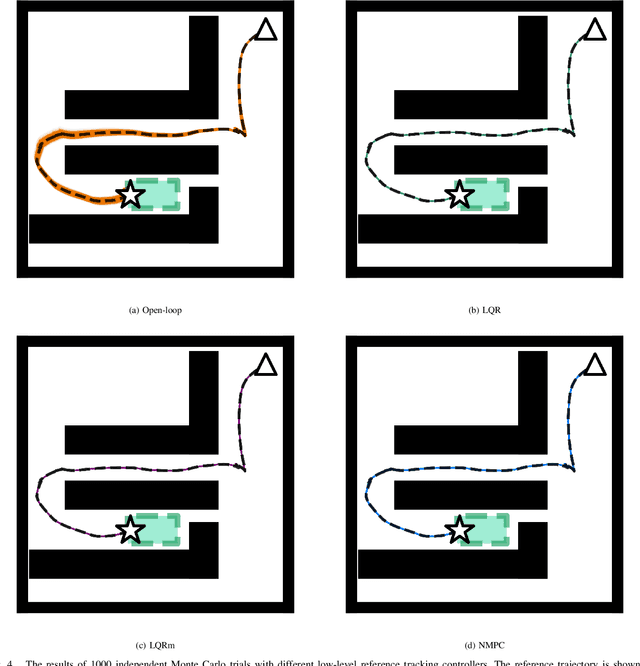
We propose a two-phase risk-averse architecture for controlling stochastic nonlinear robotic systems. We present Risk-Averse Nonlinear Steering RRT* (RANS-RRT*) as an RRT* variant that incorporates nonlinear dynamics by solving a nonlinear program (NLP) and accounts for risk by approximating the state distribution and performing a distributionally robust (DR) collision check to promote safe planning.The generated plan is used as a reference for a low-level tracking controller. We demonstrate three controllers: finite horizon linear quadratic regulator (LQR) with linearized dynamics around the reference trajectory, LQR with robustness-promoting multiplicative noise terms, and a nonlinear model predictive control law (NMPC). We demonstrate the effectiveness of our algorithm using unicycle dynamics under heavy-tailed Laplace process noise in a cluttered environment.
Robust 3D Distributed Formation Control with Application to Quadrotors
Sep 01, 2018
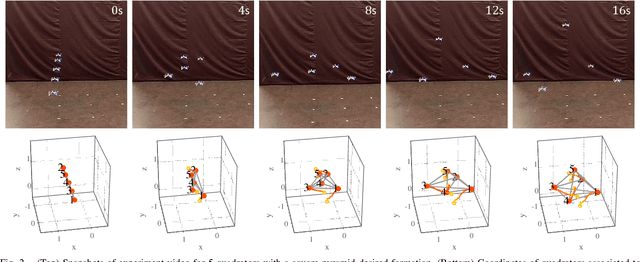
We present a distributed control strategy for a team of quadrotors to autonomously achieve a desired 3D formation. Our approach is based on local relative position measurements and does not require global position information or inter-vehicle communication. We assume that quadrotors have a common sense of direction, which is chosen as the direction of gravitational force measured by their onboard IMU sensors. However, this assumption is not crucial, and our approach is robust to inaccuracies and effects of acceleration on gravitational measurements. In particular, converge to the desired formation is unaffected if each quadrotor has a velocity vector that projects positively onto the desired velocity vector provided by the formation control strategy. We demonstrate the validity of proposed approach in an experimental setup and show that a team of quadrotors achieve a desired 3D formation.
Robust Distributed Planar Formation Control for Higher-Order Holonomic and Nonholonomic Agents
Jul 29, 2018
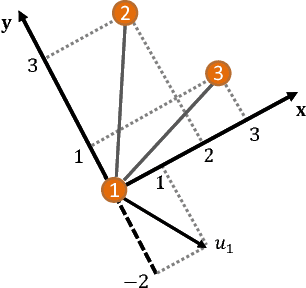
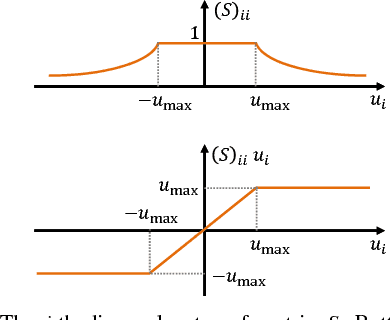
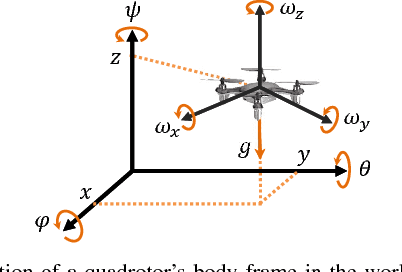
We present a distributed formation control strategy for agents with a variety of dynamics to achieve a desired planar formation. The proposed strategy is fully distributed, does not require inter-agent communication or a common sense of orientation, and can be implemented using relative position measurements acquired by agents in their local coordinate frames. We show how the control designed for agents with the simplest dynamical model, i.e., the single-integrator dynamics, can be extended to holonomic agents with higher-order dynamics such as quadrotors, and nonholonomic agents such as unicycles and cars. We prove that the proposed strategy is robust to saturations in the input, unmodeled dynamics, and switches in the sensing topology. We further show that the control is relaxed in the sense that agents can move along a rotated and scaled control direction without affecting the convergence to the desired formation. This observation is used to design a distributed collision avoidance strategy. We demonstrate the proposed approach in simulations and further present a distributed robotic platform to test the strategy experimentally. Our experimental platform consists of off-the-shelf equipment that can be used to test and validate other multi-agent algorithms. The code and implementation instructions for this platform are available online and free.