 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModule-wise Training of Neural Networks via the Minimizing Movement Scheme
Oct 05, 2023



Greedy layer-wise or module-wise training of neural networks is compelling in constrained and on-device settings where memory is limited, as it circumvents a number of problems of end-to-end back-propagation. However, it suffers from a stagnation problem, whereby early layers overfit and deeper layers stop increasing the test accuracy after a certain depth. We propose to solve this issue by introducing a module-wise regularization inspired by the minimizing movement scheme for gradient flows in distribution space. We call the method TRGL for Transport Regularized Greedy Learning and study it theoretically, proving that it leads to greedy modules that are regular and that progressively solve the task. Experimentally, we show improved accuracy of module-wise training of various architectures such as ResNets, Transformers and VGG, when our regularization is added, superior to that of other module-wise training methods and often to end-to-end training, with as much as 60% less memory usage.
Adversarial Sample Detection Through Neural Network Transport Dynamics
Jun 08, 2023


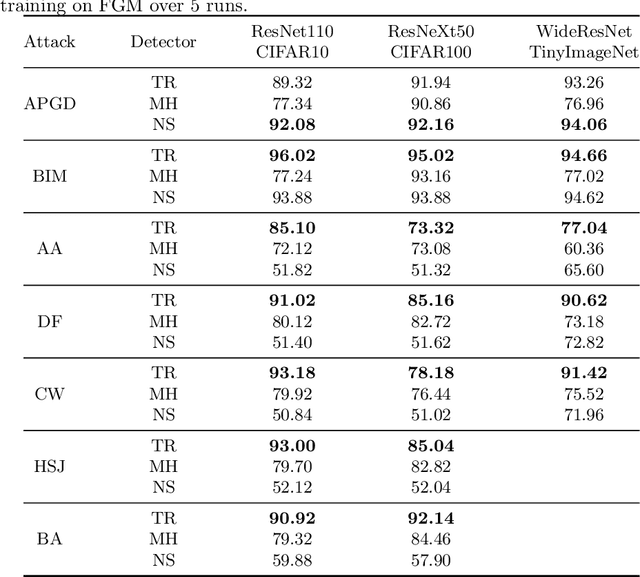
We propose a detector of adversarial samples that is based on the view of neural networks as discrete dynamic systems. The detector tells clean inputs from abnormal ones by comparing the discrete vector fields they follow through the layers. We also show that regularizing this vector field during training makes the network more regular on the data distribution's support, thus making the activations of clean inputs more distinguishable from those of abnormal ones. Experimentally, we compare our detector favorably to other detectors on seen and unseen attacks, and show that the regularization of the network's dynamics improves the performance of adversarial detectors that use the internal embeddings as inputs, while also improving test accuracy.
Module-wise Training of Residual Networks via the Minimizing Movement Scheme
Oct 03, 2022
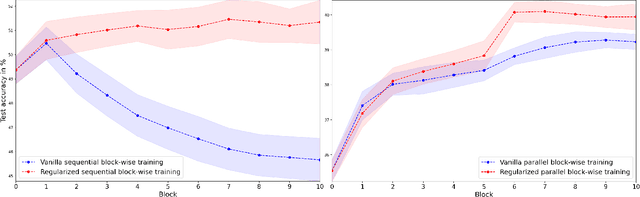

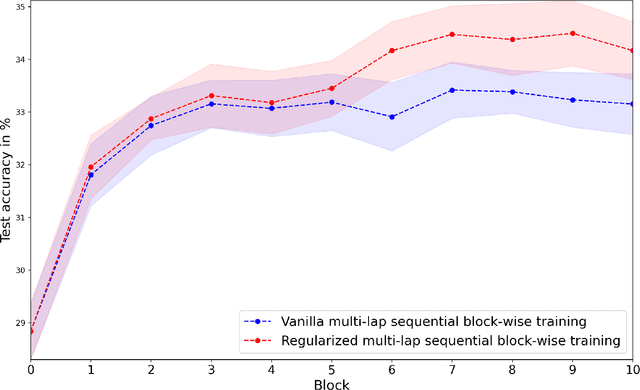
Greedy layer-wise or module-wise training of neural networks is compelling in constrained and on-device settings, as it circumvents a number of problems of end-to-end back-propagation. However, it suffers from a stagnation problem, whereby early layers overfit and deeper layers stop increasing the test accuracy after a certain depth. We propose to solve this issue by introducing a simple module-wise regularization inspired by the minimizing movement scheme for gradient flows in distribution space. The method, which we call TRGL for Transport Regularized Greedy Learning, is particularly well-adapted to residual networks. We study it theoretically, proving that it leads to greedy modules that are regular and that successively solve the task. Experimentally, we show improved accuracy of module-wise trained networks when our regularization is added.
A Principle of Least Action for the Training of Neural Networks
Sep 17, 2020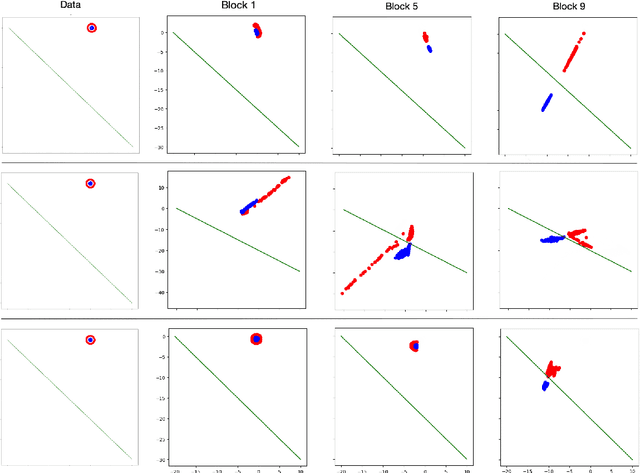
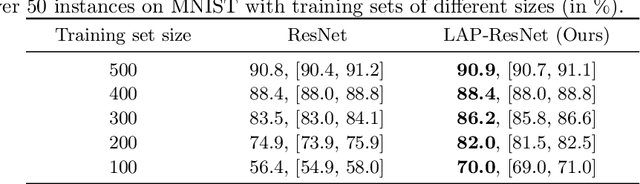
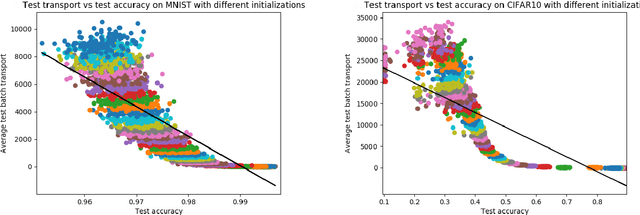
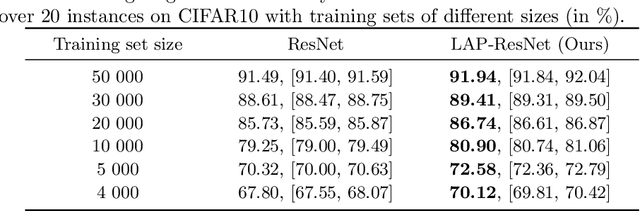
Neural networks have been achieving high generalization performance on many tasks despite being highly over-parameterized. Since classical statistical learning theory struggles to explain this behavior, much effort has recently been focused on uncovering the mechanisms behind it, in the hope of developing a more adequate theoretical framework and having a better control over the trained models. In this work, we adopt an alternate perspective, viewing the neural network as a dynamical system displacing input particles over time. We conduct a series of experiments and, by analyzing the network's behavior through its displacements, we show the presence of a low kinetic energy displacement bias in the transport map of the network, and link this bias with generalization performance. From this observation, we reformulate the learning problem as follows: finding neural networks which solve the task while transporting the data as efficiently as possible. This offers a novel formulation of the learning problem which allows us to provide regularity results for the solution network, based on Optimal Transport theory. From a practical viewpoint, this allows us to propose a new learning algorithm, which automatically adapts to the complexity of the given task, and leads to networks with a high generalization ability even in low data regimes.