 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Named Entity Recognition
Feb 16, 2023



Named Entity Recognition (NER) is a challenging and widely studied task that involves detecting and typing entities in text. So far,NER still approaches entity typing as a task of classification into universal classes (e.g. date, person, or location). Recent advances innatural language processing focus on architectures of increasing complexity that may lead to overfitting and memorization, and thus, underuse of context. Our work targets situations where the type of entities depends on the context and cannot be solved solely by memorization. We hence introduce a new task: Dynamic Named Entity Recognition (DNER), providing a framework to better evaluate the ability of algorithms to extract entities by exploiting the context. The DNER benchmark is based on two datasets, DNER-RotoWire and DNER-IMDb. We evaluate baseline models and present experiments reflecting issues and research axes related to this novel task.
Evidential positive opinion influence measures for viral marketing
Jul 11, 2019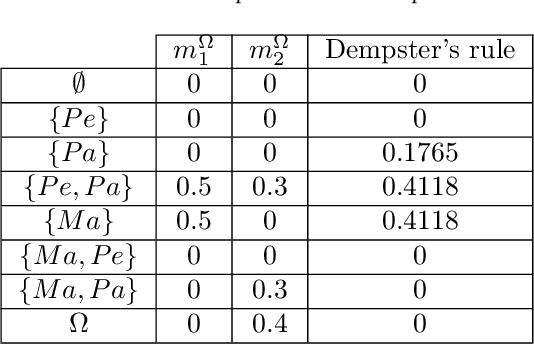
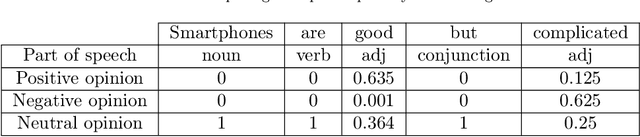

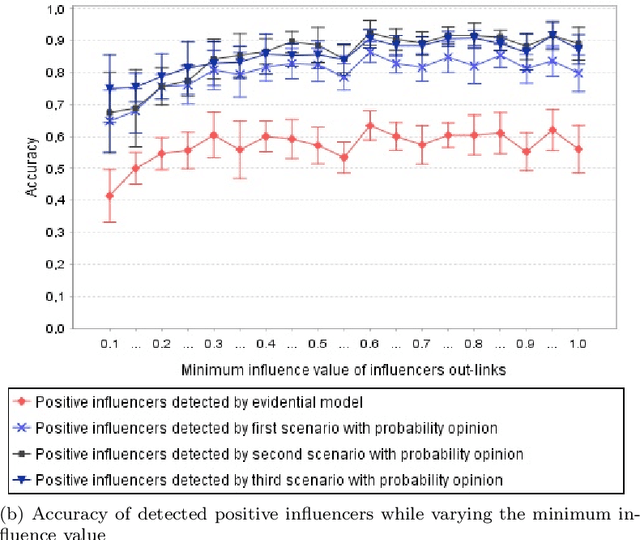
The Viral Marketing is a relatively new form of marketing that exploits social networks to promote a brand, a product, etc. The idea behind it is to find a set of influencers on the network that can trigger a large cascade of propagation and adoptions. In this paper, we will introduce an evidential opinion-based influence maximization model for viral marketing. Besides, our approach tackles three opinions based scenarios for viral marketing in the real world. The first scenario concerns influencers who have a positive opinion about the product. The second scenario deals with influencers who have a positive opinion about the product and produce effects on users who also have a positive opinion. The third scenario involves influence users who have a positive opinion about the product and produce effects on the negative opinion of other users concerning the product in question. Next, we proposed six influence measures, two for each scenario. We also use an influence maximization model that the set of detected influencers for each scenario. Finally, we show the performance of the proposed model with each influence measure through some experiments conducted on a generated dataset and a real world dataset collected from Twitter.
A reliability-based approach for influence maximization using the evidence theory
Jun 30, 2017
The influence maximization is the problem of finding a set of social network users, called influencers, that can trigger a large cascade of propagation. Influencers are very beneficial to make a marketing campaign goes viral through social networks for example. In this paper, we propose an influence measure that combines many influence indicators. Besides, we consider the reliability of each influence indicator and we present a distance-based process that allows to estimate the reliability of each indicator. The proposed measure is defined under the framework of the theory of belief functions. Furthermore, the reliability-based influence measure is used with an influence maximization model to select a set of users that are able to maximize the influence in the network. Finally, we present a set of experiments on a dataset collected from Twitter. These experiments show the performance of the proposed solution in detecting social influencers with good quality.
Dynamic time warping distance for message propagation classification in Twitter
Jan 26, 2017

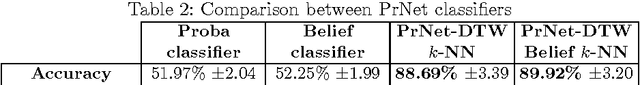
Social messages classification is a research domain that has attracted the attention of many researchers in these last years. Indeed, the social message is different from ordinary text because it has some special characteristics like its shortness. Then the development of new approaches for the processing of the social message is now essential to make its classification more efficient. In this paper, we are mainly interested in the classification of social messages based on their spreading on online social networks (OSN). We proposed a new distance metric based on the Dynamic Time Warping distance and we use it with the probabilistic and the evidential k Nearest Neighbors (k-NN) classifiers to classify propagation networks (PrNets) of messages. The propagation network is a directed acyclic graph (DAG) that is used to record propagation traces of the message, the traversed links and their types. We tested the proposed metric with the chosen k-NN classifiers on real world propagation traces that were collected from Twitter social network and we got good classification accuracies.
Maximizing positive opinion influence using an evidential approach
Oct 20, 2016
In this paper, we propose a new data based model for influence maximization in online social networks. We use the theory of belief functions to overcome the data imperfection problem. Besides, the proposed model searches to detect influencer users that adopt a positive opinion about the product, the idea, etc, to be propagated. Moreover, we present some experiments to show the performance of our model.
Second-Order Belief Hidden Markov Models
Jan 22, 2015
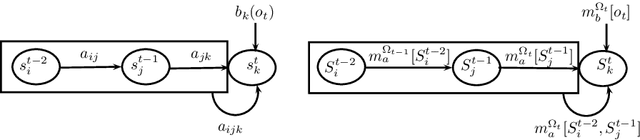
Hidden Markov Models (HMMs) are learning methods for pattern recognition. The probabilistic HMMs have been one of the most used techniques based on the Bayesian model. First-order probabilistic HMMs were adapted to the theory of belief functions such that Bayesian probabilities were replaced with mass functions. In this paper, we present a second-order Hidden Markov Model using belief functions. Previous works in belief HMMs have been focused on the first-order HMMs. We extend them to the second-order model.
Belief Hidden Markov Model for speech recognition
Jan 22, 2015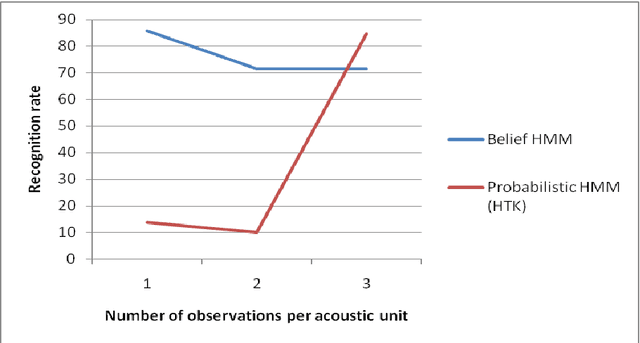
Speech Recognition searches to predict the spoken words automatically. These systems are known to be very expensive because of using several pre-recorded hours of speech. Hence, building a model that minimizes the cost of the recognizer will be very interesting. In this paper, we present a new approach for recognizing speech based on belief HMMs instead of proba-bilistic HMMs. Experiments shows that our belief recognizer is insensitive to the lack of the data and it can be trained using only one exemplary of each acoustic unit and it gives a good recognition rates. Consequently, using the belief HMM recognizer can greatly minimize the cost of these systems.
Classification of Message Spreading in a Heterogeneous Social Network
Jan 22, 2015
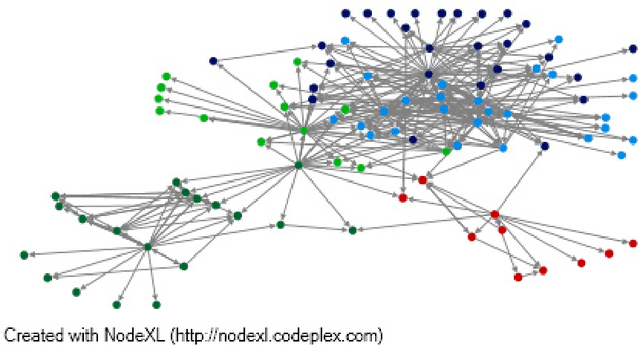
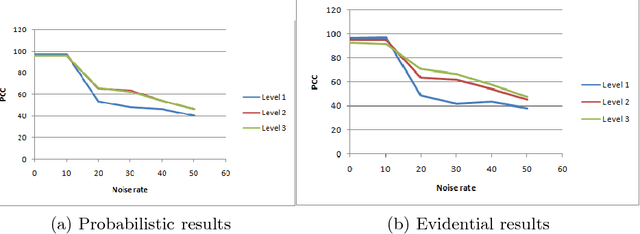

Nowadays, social networks such as Twitter, Facebook and LinkedIn become increasingly popular. In fact, they introduced new habits, new ways of communication and they collect every day several information that have different sources. Most existing research works fo-cus on the analysis of homogeneous social networks, i.e. we have a single type of node and link in the network. However, in the real world, social networks offer several types of nodes and links. Hence, with a view to preserve as much information as possible, it is important to consider so-cial networks as heterogeneous and uncertain. The goal of our paper is to classify the social message based on its spreading in the network and the theory of belief functions. The proposed classifier interprets the spread of messages on the network, crossed paths and types of links. We tested our classifier on a real word network that we collected from Twitter, and our experiments show the performance of our belief classifier.