 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMS-Net: Regression and Masking for Soccer Event Spotting
Feb 15, 2021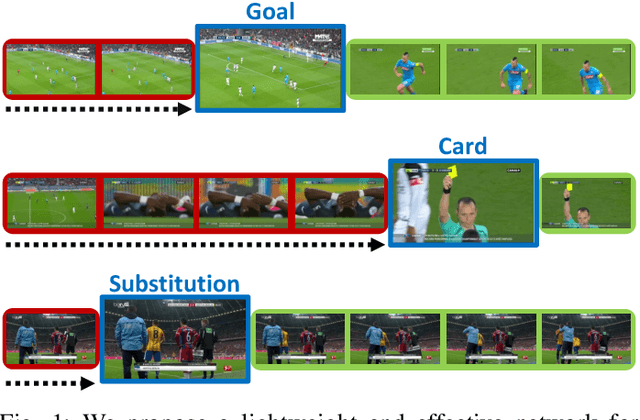
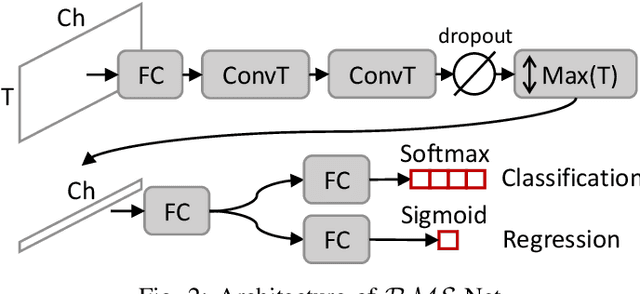
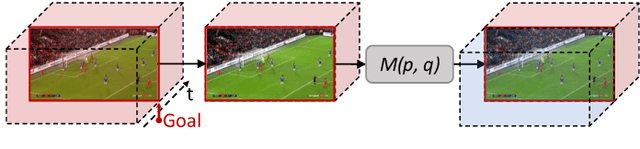
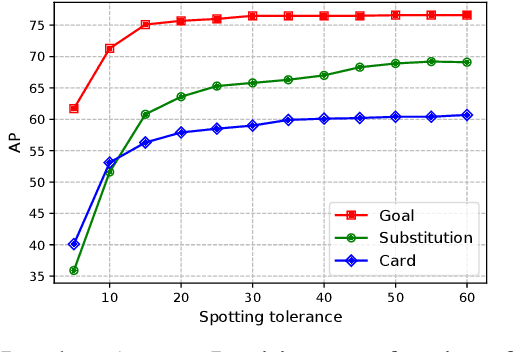
The recently proposed action spotting task consists in finding the exact timestamp in which an event occurs. This task fits particularly well for soccer videos, where events correspond to salient actions strictly defined by soccer rules (a goal occurs when the ball crosses the goal line). In this paper, we devise a lightweight and modular network for action spotting, which can simultaneously predict the event label and its temporal offset using the same underlying features. We enrich our model with two training strategies: the first one for data balancing and uniform sampling, the second for masking ambiguous frames and keeping the most discriminative visual cues. When tested on the SoccerNet dataset and using standard features, our full proposal exceeds the current state of the art by 3 Average-mAP points. Additionally, it reaches a gain of more than 10 Average-mAP points on the test set when fine-tuned in combination with a strong 2D backbone.
STAGE: Spatio-Temporal Attention on Graph Entities for Video Action Detection
Dec 09, 2019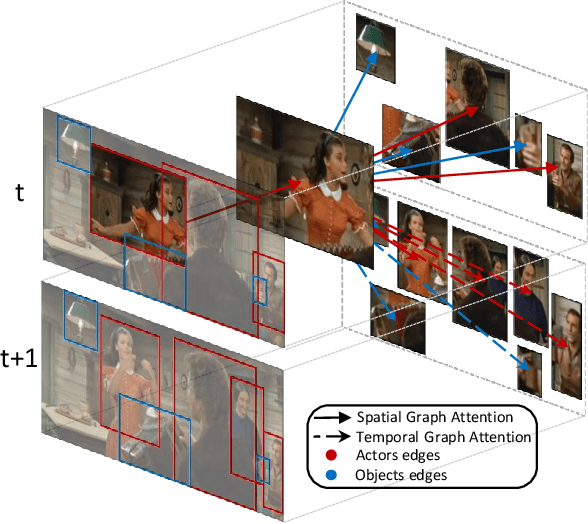

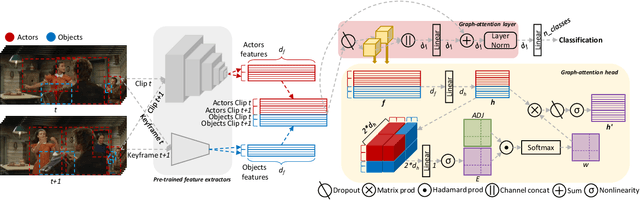
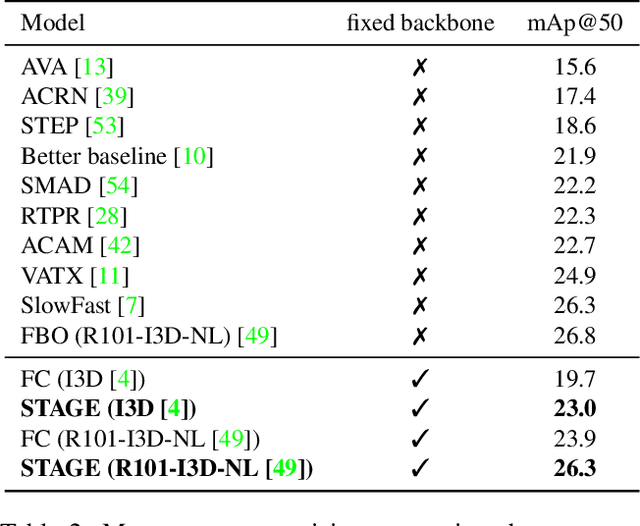
Spatio-temporal action localization is a challenging yet fascinating task that aims to detect and classify human actions in video clips. In this paper, we develop a high-level video understanding module which can encode interactions between actors and objects both in space and time. In our formulation, spatio-temporal relationships are learned by performing self-attention operations on a graph structure connecting entities from consecutive clips. Noticeably, the use of graph learning is unprecedented for this task. From a computational point of view, the proposed module is backbone independent by design and does not need end-to-end training. When tested on the AVA dataset, it demonstrates a 10-16% relative mAP improvement over the baseline. Further, it can outperform or bring performances comparable to state-of-the-art models which require heavy end-to-end and synchronized training on multiple GPUs. Code is publicly available at: https://github.com/aimagelab/STAGE_action_detection.