 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAGE: Spatio-Temporal Attention on Graph Entities for Video Action Detection
Paper and Code
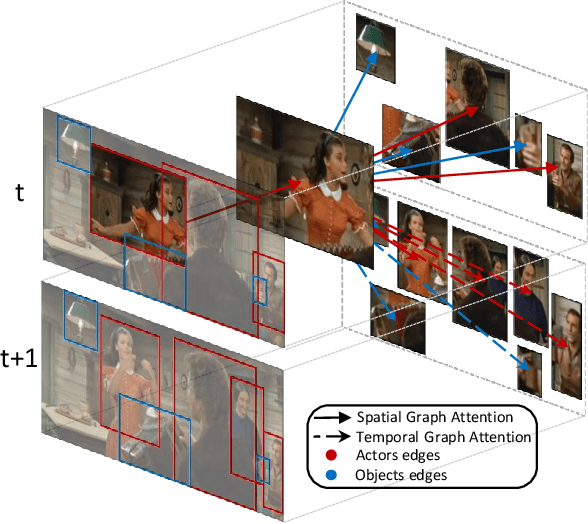

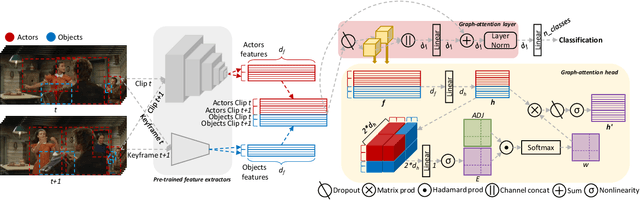
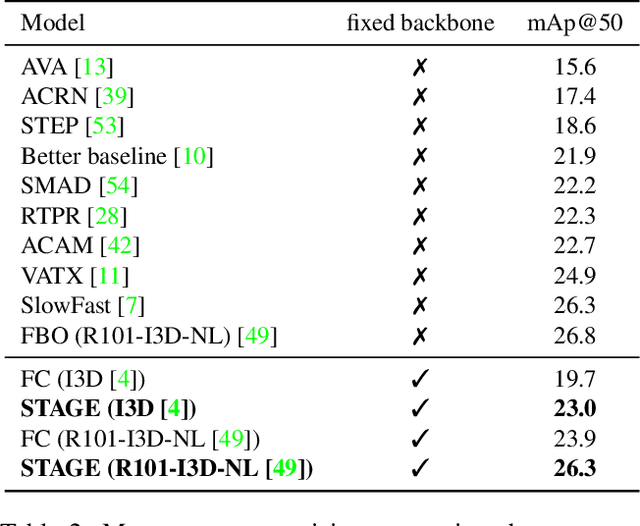
Spatio-temporal action localization is a challenging yet fascinating task that aims to detect and classify human actions in video clips. In this paper, we develop a high-level video understanding module which can encode interactions between actors and objects both in space and time. In our formulation, spatio-temporal relationships are learned by performing self-attention operations on a graph structure connecting entities from consecutive clips. Noticeably, the use of graph learning is unprecedented for this task. From a computational point of view, the proposed module is backbone independent by design and does not need end-to-end training. When tested on the AVA dataset, it demonstrates a 10-16% relative mAP improvement over the baseline. Further, it can outperform or bring performances comparable to state-of-the-art models which require heavy end-to-end and synchronized training on multiple GPUs. Code is publicly available at: https://github.com/aimagelab/STAGE_action_detection.