 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRUM: Robust 3D Vehicle Reconstruction from 360 Sparse Images
Jul 16, 2025Accurate 3D reconstruction of vehicles is vital for applications such as vehicle inspection, predictive maintenance, and urban planning. Existing methods like Neural Radiance Fields and Gaussian Splatting have shown impressive results but remain limited by their reliance on dense input views, which hinders real-world applicability. This paper addresses the challenge of reconstructing vehicles from sparse-view inputs, leveraging depth maps and a robust pose estimation architecture to synthesize novel views and augment training data. Specifically, we enhance Gaussian Splatting by integrating a selective photometric loss, applied only to high-confidence pixels, and replacing standard Structure-from-Motion pipelines with the DUSt3R architecture to improve camera pose estimation. Furthermore, we present a novel dataset featuring both synthetic and real-world public transportation vehicles, enabling extensive evaluation of our approach. Experimental results demonstrate state-of-the-art performance across multiple benchmarks, showcasing the method's ability to achieve high-quality reconstructions even under constrained input conditions.
KRONC: Keypoint-based Robust Camera Optimization for 3D Car Reconstruction
Sep 09, 2024



The three-dimensional representation of objects or scenes starting from a set of images has been a widely discussed topic for years and has gained additional attention after the diffusion of NeRF-based approaches. However, an underestimated prerequisite is the knowledge of camera poses or, more specifically, the estimation of the extrinsic calibration parameters. Although excellent general-purpose Structure-from-Motion methods are available as a pre-processing step, their computational load is high and they require a lot of frames to guarantee sufficient overlapping among the views. This paper introduces KRONC, a novel approach aimed at inferring view poses by leveraging prior knowledge about the object to reconstruct and its representation through semantic keypoints. With a focus on vehicle scenes, KRONC is able to estimate the position of the views as a solution to a light optimization problem targeting the convergence of keypoints' back-projections to a singular point. To validate the method, a specific dataset of real-world car scenes has been collected. Experiments confirm KRONC's ability to generate excellent estimates of camera poses starting from very coarse initialization. Results are comparable with Structure-from-Motion methods with huge savings in computation. Code and data will be made publicly available.
CarPatch: A Synthetic Benchmark for Radiance Field Evaluation on Vehicle Components
Jul 24, 2023



Neural Radiance Fields (NeRFs) have gained widespread recognition as a highly effective technique for representing 3D reconstructions of objects and scenes derived from sets of images. Despite their efficiency, NeRF models can pose challenges in certain scenarios such as vehicle inspection, where the lack of sufficient data or the presence of challenging elements (e.g. reflections) strongly impact the accuracy of the reconstruction. To this aim, we introduce CarPatch, a novel synthetic benchmark of vehicles. In addition to a set of images annotated with their intrinsic and extrinsic camera parameters, the corresponding depth maps and semantic segmentation masks have been generated for each view. Global and part-based metrics have been defined and used to evaluate, compare, and better characterize some state-of-the-art techniques. The dataset is publicly released at https://aimagelab.ing.unimore.it/go/carpatch and can be used as an evaluation guide and as a baseline for future work on this challenging topic.
RMS-Net: Regression and Masking for Soccer Event Spotting
Feb 15, 2021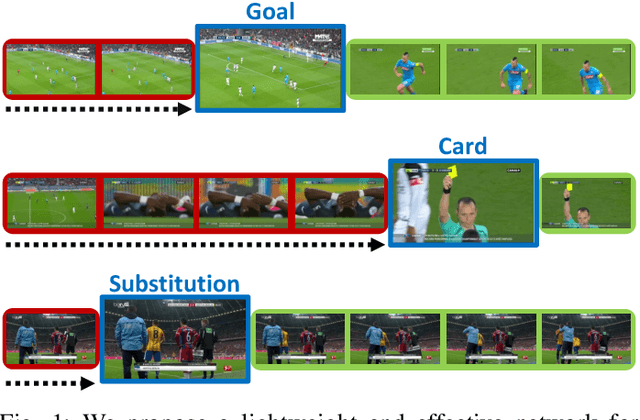
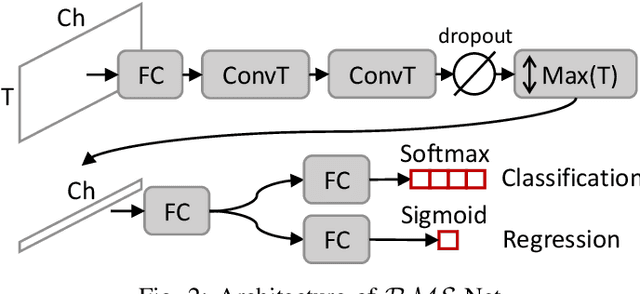
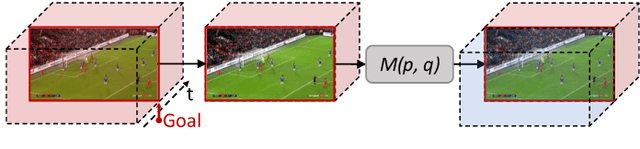
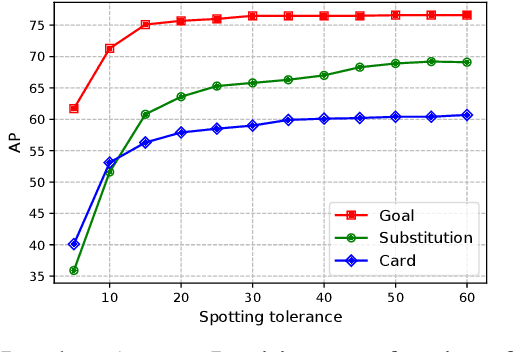
The recently proposed action spotting task consists in finding the exact timestamp in which an event occurs. This task fits particularly well for soccer videos, where events correspond to salient actions strictly defined by soccer rules (a goal occurs when the ball crosses the goal line). In this paper, we devise a lightweight and modular network for action spotting, which can simultaneously predict the event label and its temporal offset using the same underlying features. We enrich our model with two training strategies: the first one for data balancing and uniform sampling, the second for masking ambiguous frames and keeping the most discriminative visual cues. When tested on the SoccerNet dataset and using standard features, our full proposal exceeds the current state of the art by 3 Average-mAP points. Additionally, it reaches a gain of more than 10 Average-mAP points on the test set when fine-tuned in combination with a strong 2D backbone.
STAGE: Spatio-Temporal Attention on Graph Entities for Video Action Detection
Dec 09, 2019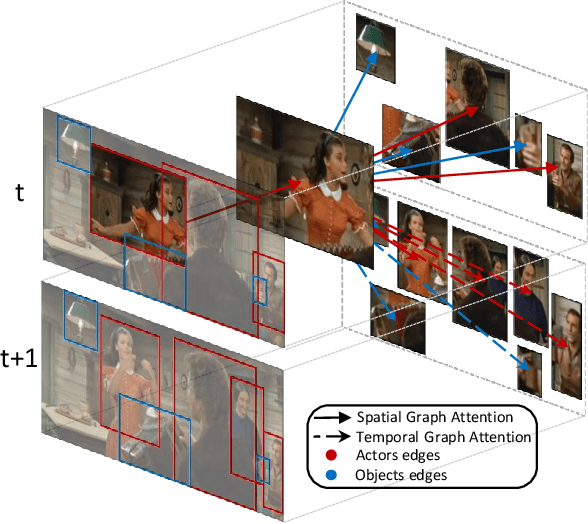

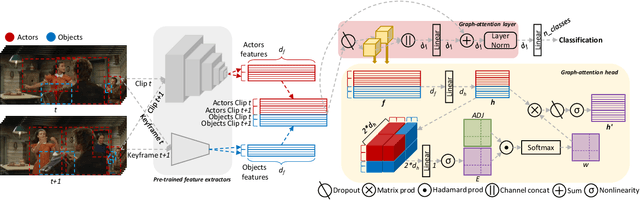
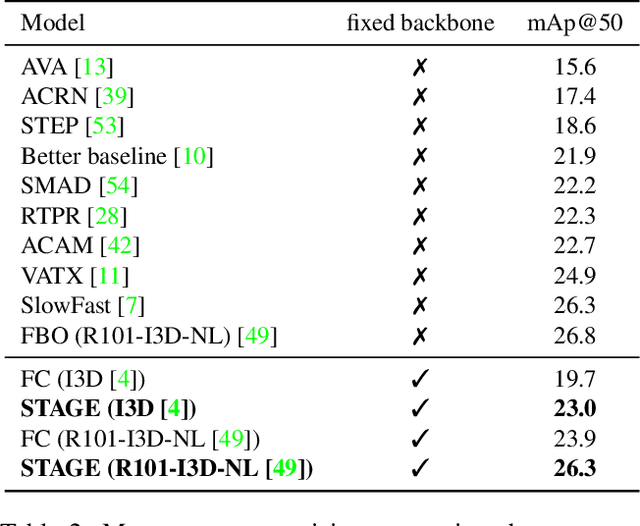
Spatio-temporal action localization is a challenging yet fascinating task that aims to detect and classify human actions in video clips. In this paper, we develop a high-level video understanding module which can encode interactions between actors and objects both in space and time. In our formulation, spatio-temporal relationships are learned by performing self-attention operations on a graph structure connecting entities from consecutive clips. Noticeably, the use of graph learning is unprecedented for this task. From a computational point of view, the proposed module is backbone independent by design and does not need end-to-end training. When tested on the AVA dataset, it demonstrates a 10-16% relative mAP improvement over the baseline. Further, it can outperform or bring performances comparable to state-of-the-art models which require heavy end-to-end and synchronized training on multiple GPUs. Code is publicly available at: https://github.com/aimagelab/STAGE_action_detection.
Art2Real: Unfolding the Reality of Artworks via Semantically-Aware Image-to-Image Translation
Nov 26, 2018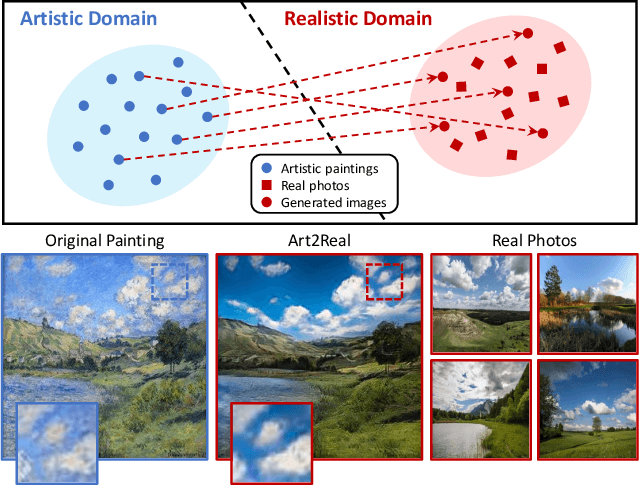
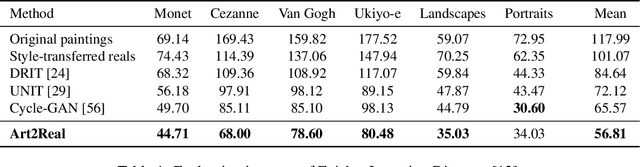
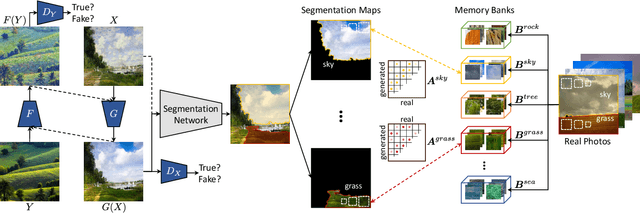

The applicability of computer vision to real paintings and artworks has been rarely investigated, even though a vast heritage would greatly benefit from techniques which can understand and process data from the artistic domain. This is partially due to the small amount of annotated artistic data, which is not even comparable to that of natural images captured by cameras. In this paper, we propose a semantic-aware architecture which can translate artworks to photo-realistic visualizations, thus reducing the gap between visual features of artistic and realistic data. Our architecture can generate natural images by retrieving and learning details from real photos through a similarity matching strategy which leverages a weakly-supervised semantic understanding of the scene. Experimental results show that the proposed technique leads to increased realism and to a reduction in domain shift, which improves the performance of pre-trained architectures for classification, detection, and segmentation. Code will be made publicly available.