 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPS-free Autonomous Navigation in Cluttered Tree Rows with Deep Semantic Segmentation
Apr 08, 2024



Segmentation-based autonomous navigation has recently been presented as an appealing approach to guiding robotic platforms through crop rows without requiring perfect GPS localization. Nevertheless, current techniques are restricted to situations where the distinct separation between the plants and the sky allows for the identification of the row's center. However, tall, dense vegetation, such as high tree rows and orchards, is the primary cause of GPS signal blockage. In this study, we increase the overall robustness and adaptability of the control algorithm by extending the segmentation-based robotic guiding to those cases where canopies and branches occlude the sky and prevent the utilization of GPS and earlier approaches. An efficient Deep Neural Network architecture has been used to address semantic segmentation, performing the training with synthetic data only. Numerous vineyards and tree fields have undergone extensive testing in both simulation and real-world to show the solution's competitive benefits.
Lavender Autonomous Navigation with Semantic Segmentation at the Edge
Sep 13, 2023Achieving success in agricultural activities heavily relies on precise navigation in row crop fields. Recently, segmentation-based navigation has emerged as a reliable technique when GPS-based localization is unavailable or higher accuracy is needed due to vegetation or unfavorable weather conditions. It also comes in handy when plants are growing rapidly and require an online adaptation of the navigation algorithm. This work applies a segmentation-based visual agnostic navigation algorithm to lavender fields, considering both simulation and real-world scenarios. The effectiveness of this approach is validated through a wide set of experimental tests, which show the capability of the proposed solution to generalize over different scenarios and provide highly-reliable results.
Autonomous Navigation in Rows of Trees and High Crops with Deep Semantic Segmentation
Apr 18, 2023
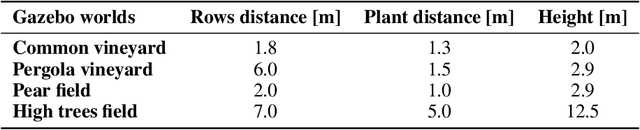
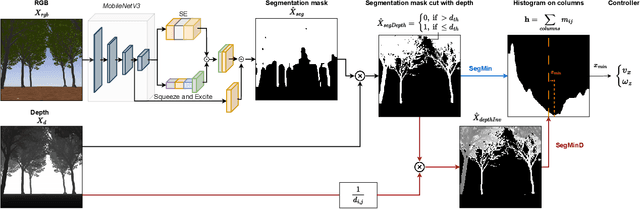
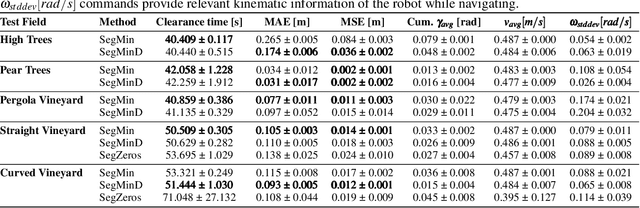
Segmentation-based autonomous navigation has recently been proposed as a promising methodology to guide robotic platforms through crop rows without requiring precise GPS localization. However, existing methods are limited to scenarios where the centre of the row can be identified thanks to the sharp distinction between the plants and the sky. However, GPS signal obstruction mainly occurs in the case of tall, dense vegetation, such as high tree rows and orchards. In this work, we extend the segmentation-based robotic guidance to those scenarios where canopies and branches occlude the sky and hinder the usage of GPS and previous methods, increasing the overall robustness and adaptability of the control algorithm. Extensive experimentation on several realistic simulated tree fields and vineyards demonstrates the competitive advantages of the proposed solution.
Domain Generalization for Crop Segmentation with Knowledge Distillation
Apr 03, 2023



In recent years, precision agriculture has gradually oriented farming closer to automation processes to support all the activities related to field management. Service robotics plays a predominant role in this evolution by deploying autonomous agents that can navigate fields while performing tasks without human intervention, such as monitoring, spraying, and harvesting. To execute these precise actions, mobile robots need a real-time perception system that understands their surroundings and identifies their targets in the wild. Generalizing to new crops and environmental conditions is critical for practical applications, as labeled samples are rarely available. In this paper, we investigate the problem of crop segmentation and propose a novel approach to enhance domain generalization using knowledge distillation. In the proposed framework, we transfer knowledge from an ensemble of models individually trained on source domains to a student model that can adapt to unseen target domains. To evaluate the proposed method, we present a synthetic multi-domain dataset for crop segmentation containing plants of variegate shapes and covering different terrain styles, weather conditions, and light scenarios for more than 50,000 samples. We demonstrate significant improvements in performance over state-of-the-art methods. Our approach provides a promising solution for domain generalization in crop segmentation and has the potential to enhance precision agriculture applications.
Online Learning of Wheel Odometry Correction for Mobile Robots with Attention-based Neural Network
Mar 21, 2023



Modern robotic platforms need a reliable localization system to operate daily beside humans. Simple pose estimation algorithms based on filtered wheel and inertial odometry often fail in the presence of abrupt kinematic changes and wheel slips. Moreover, despite the recent success of visual odometry, service and assistive robotic tasks often present challenging environmental conditions where visual-based solutions fail due to poor lighting or repetitive feature patterns. In this work, we propose an innovative online learning approach for wheel odometry correction, paving the way for a robust multi-source localization system. An efficient attention-based neural network architecture has been studied to combine precise performances with real-time inference. The proposed solution shows remarkable results compared to a standard neural network and filter-based odometry correction algorithms. Nonetheless, the online learning paradigm avoids the time-consuming data collection procedure and can be adopted on a generic robotic platform on-the-fly.
Deep Instance Segmentation and Visual Servoing to Play Jenga with a Cost-Effective Robotic System
Nov 15, 2022



The game of Jenga represents an inspiring benchmark for developing innovative manipulation solutions for complex tasks. Indeed, it encouraged the study of novel robotics methods to extract blocks from the tower successfully. A Jenga game round undoubtedly embeds many traits of complex industrial or surgical manipulation tasks, requiring a multi-step strategy, the combination of visual and tactile data, and the highly precise motion of the robotic arm to perform a single block extraction. In this work, we propose a novel cost-effective architecture for playing Jenga with e.Do, a 6-DOF anthropomorphic manipulator manufactured by Comau, a standard depth camera, and an inexpensive monodirectional force sensor. Our solution focuses on a visual-based control strategy to accurately align the end-effector with the desired block, enabling block extraction by pushing. To this aim, we train an instance segmentation deep learning model on a synthetic custom dataset to segment each piece of the Jenga tower, allowing visual tracking of the desired block's pose during the motion of the manipulator. We integrate the visual-based strategy with a 1D force sensor to detect whether the block can be safely removed by identifying a force threshold value. Our experimentation shows that our low-cost solution allows e.DO to precisely reach removable blocks and perform up to 14 consecutive extractions in a row.
Generative Adversarial Super-Resolution at the Edge with Knowledge Distillation
Sep 07, 2022



Single-Image Super-Resolution can support robotic tasks in environments where a reliable visual stream is required to monitor the mission, handle teleoperation or study relevant visual details. In this work, we propose an efficient Generative Adversarial Network model for real-time Super-Resolution. We adopt a tailored architecture of the original SRGAN and model quantization to boost the execution on CPU and Edge TPU devices, achieving up to 200 fps inference. We further optimize our model by distilling its knowledge to a smaller version of the network and obtain remarkable improvements compared to the standard training approach. Our experiments show that our fast and lightweight model preserves considerably satisfying image quality compared to heavier state-of-the-art models. Finally, we conduct experiments on image transmission with bandwidth degradation to highlight the advantages of the proposed system for mobile robotic applications.
Ultra-low-power Range Error Mitigation for Ultra-wideband Precise Localization
Sep 07, 2022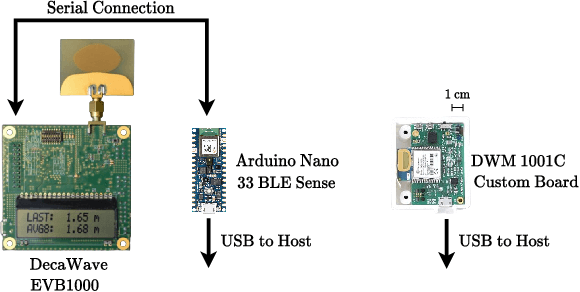
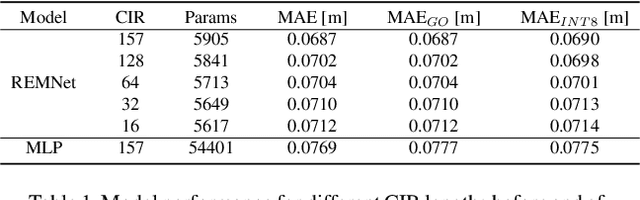
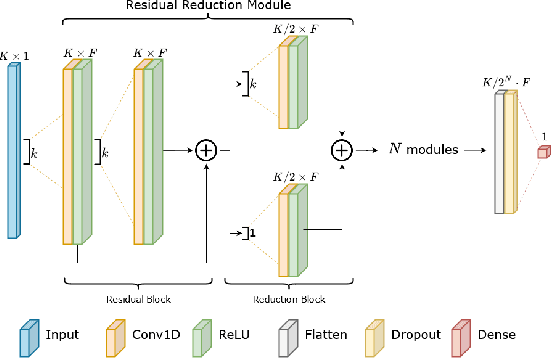

Precise and accurate localization in outdoor and indoor environments is a challenging problem that currently constitutes a significant limitation for several practical applications. Ultra-wideband (UWB) localization technology represents a valuable low-cost solution to the problem. However, non-line-of-sight (NLOS) conditions and complexity of the specific radio environment can easily introduce a positive bias in the ranging measurement, resulting in highly inaccurate and unsatisfactory position estimation. In the light of this, we leverage the latest advancement in deep neural network optimization techniques and their implementation on ultra-low-power microcontrollers to introduce an effective range error mitigation solution that provides corrections in either NLOS or LOS conditions with a few mW of power. Our extensive experimentation endorses the advantages and improvements of our low-cost and power-efficient methodology.
Back-to-Bones: Rediscovering the Role of Backbones in Domain Generalization
Sep 02, 2022
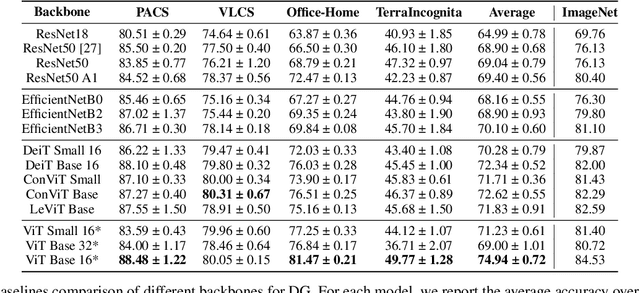


Domain Generalization (DG) studies the capability of a deep learning model to generalize to out-of-training distributions. In the last decade, literature has been massively filled with a collection of training methodologies that claim to obtain more abstract and robust data representations to tackle domain shifts. Recent research has provided a reproducible benchmark for DG, pointing out the effectiveness of naive empirical risk minimization (ERM) over existing algorithms. Nevertheless, researchers persist in using the same outdated feature extractors, and no attention has been given to the effects of different backbones yet. In this paper, we start back to backbones proposing a comprehensive analysis of their intrinsic generalization capabilities, so far ignored by the research community. We evaluate a wide variety of feature extractors, from standard residual solutions to transformer-based architectures, finding an evident linear correlation between large-scale single-domain classification accuracy and DG capability. Our extensive experimentation shows that by adopting competitive backbones in conjunction with effective data augmentation, plain ERM outperforms recent DG solutions and achieves state-of-the-art accuracy. Moreover, our additional qualitative studies reveal that novel backbones give more similar representations to same-class samples, separating different domains in the feature space. This boost in generalization capabilities leaves marginal room for DG algorithms and suggests a new paradigm for investigating the problem, placing backbones in the spotlight and encouraging the development of consistent algorithms on top of them.
Position-Agnostic Autonomous Navigation in Vineyards with Deep Reinforcement Learning
Jun 28, 2022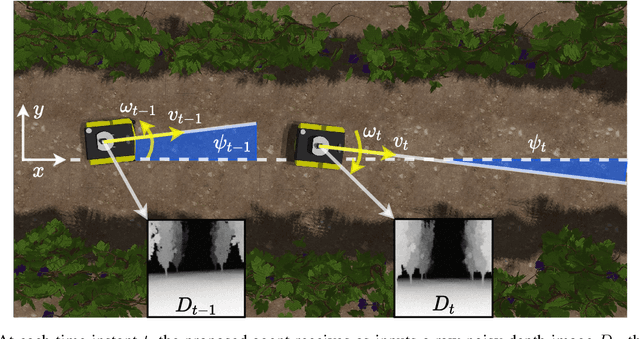
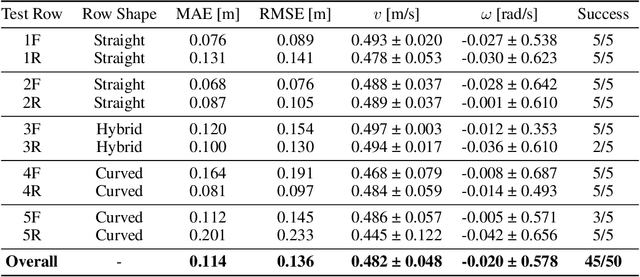

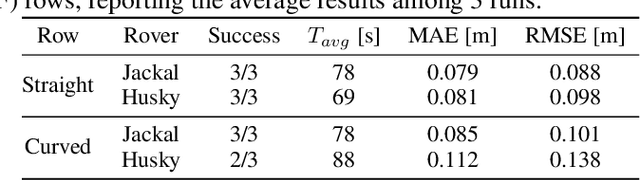
Precision agriculture is rapidly attracting research to efficiently introduce automation and robotics solutions to support agricultural activities. Robotic navigation in vineyards and orchards offers competitive advantages in autonomously monitoring and easily accessing crops for harvesting, spraying and performing time-consuming necessary tasks. Nowadays, autonomous navigation algorithms exploit expensive sensors which also require heavy computational cost for data processing. Nonetheless, vineyard rows represent a challenging outdoor scenario where GPS and Visual Odometry techniques often struggle to provide reliable positioning information. In this work, we combine Edge AI with Deep Reinforcement Learning to propose a cutting-edge lightweight solution to tackle the problem of autonomous vineyard navigation without exploiting precise localization data and overcoming task-tailored algorithms with a flexible learning-based approach. We train an end-to-end sensorimotor agent which directly maps noisy depth images and position-agnostic robot state information to velocity commands and guides the robot to the end of a row, continuously adjusting its heading for a collision-free central trajectory. Our extensive experimentation in realistic simulated vineyards demonstrates the effectiveness of our solution and the generalization capabilities of our agent.