 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Instance Segmentation and Visual Servoing to Play Jenga with a Cost-Effective Robotic System
Nov 15, 2022



The game of Jenga represents an inspiring benchmark for developing innovative manipulation solutions for complex tasks. Indeed, it encouraged the study of novel robotics methods to extract blocks from the tower successfully. A Jenga game round undoubtedly embeds many traits of complex industrial or surgical manipulation tasks, requiring a multi-step strategy, the combination of visual and tactile data, and the highly precise motion of the robotic arm to perform a single block extraction. In this work, we propose a novel cost-effective architecture for playing Jenga with e.Do, a 6-DOF anthropomorphic manipulator manufactured by Comau, a standard depth camera, and an inexpensive monodirectional force sensor. Our solution focuses on a visual-based control strategy to accurately align the end-effector with the desired block, enabling block extraction by pushing. To this aim, we train an instance segmentation deep learning model on a synthetic custom dataset to segment each piece of the Jenga tower, allowing visual tracking of the desired block's pose during the motion of the manipulator. We integrate the visual-based strategy with a 1D force sensor to detect whether the block can be safely removed by identifying a force threshold value. Our experimentation shows that our low-cost solution allows e.DO to precisely reach removable blocks and perform up to 14 consecutive extractions in a row.
Generative Adversarial Super-Resolution at the Edge with Knowledge Distillation
Sep 07, 2022



Single-Image Super-Resolution can support robotic tasks in environments where a reliable visual stream is required to monitor the mission, handle teleoperation or study relevant visual details. In this work, we propose an efficient Generative Adversarial Network model for real-time Super-Resolution. We adopt a tailored architecture of the original SRGAN and model quantization to boost the execution on CPU and Edge TPU devices, achieving up to 200 fps inference. We further optimize our model by distilling its knowledge to a smaller version of the network and obtain remarkable improvements compared to the standard training approach. Our experiments show that our fast and lightweight model preserves considerably satisfying image quality compared to heavier state-of-the-art models. Finally, we conduct experiments on image transmission with bandwidth degradation to highlight the advantages of the proposed system for mobile robotic applications.
Ultra-low-power Range Error Mitigation for Ultra-wideband Precise Localization
Sep 07, 2022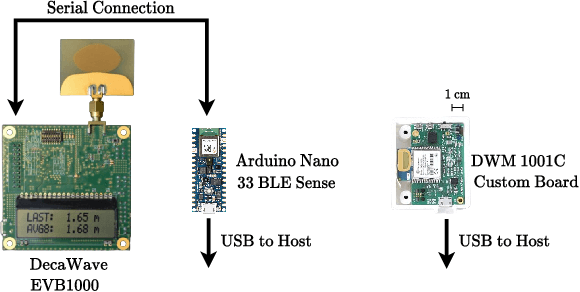
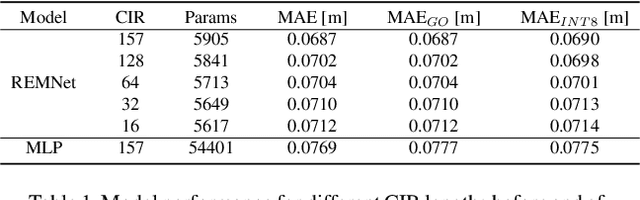
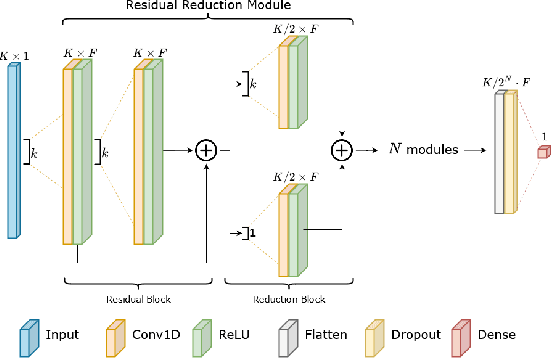

Precise and accurate localization in outdoor and indoor environments is a challenging problem that currently constitutes a significant limitation for several practical applications. Ultra-wideband (UWB) localization technology represents a valuable low-cost solution to the problem. However, non-line-of-sight (NLOS) conditions and complexity of the specific radio environment can easily introduce a positive bias in the ranging measurement, resulting in highly inaccurate and unsatisfactory position estimation. In the light of this, we leverage the latest advancement in deep neural network optimization techniques and their implementation on ultra-low-power microcontrollers to introduce an effective range error mitigation solution that provides corrections in either NLOS or LOS conditions with a few mW of power. Our extensive experimentation endorses the advantages and improvements of our low-cost and power-efficient methodology.
Back-to-Bones: Rediscovering the Role of Backbones in Domain Generalization
Sep 02, 2022
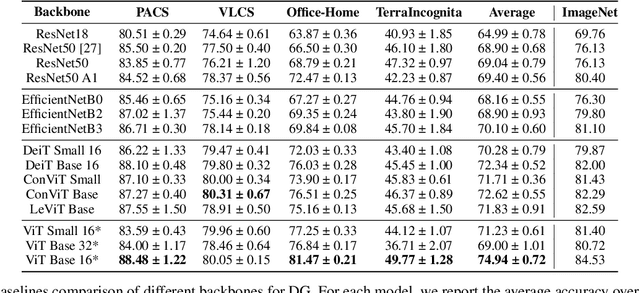


Domain Generalization (DG) studies the capability of a deep learning model to generalize to out-of-training distributions. In the last decade, literature has been massively filled with a collection of training methodologies that claim to obtain more abstract and robust data representations to tackle domain shifts. Recent research has provided a reproducible benchmark for DG, pointing out the effectiveness of naive empirical risk minimization (ERM) over existing algorithms. Nevertheless, researchers persist in using the same outdated feature extractors, and no attention has been given to the effects of different backbones yet. In this paper, we start back to backbones proposing a comprehensive analysis of their intrinsic generalization capabilities, so far ignored by the research community. We evaluate a wide variety of feature extractors, from standard residual solutions to transformer-based architectures, finding an evident linear correlation between large-scale single-domain classification accuracy and DG capability. Our extensive experimentation shows that by adopting competitive backbones in conjunction with effective data augmentation, plain ERM outperforms recent DG solutions and achieves state-of-the-art accuracy. Moreover, our additional qualitative studies reveal that novel backbones give more similar representations to same-class samples, separating different domains in the feature space. This boost in generalization capabilities leaves marginal room for DG algorithms and suggests a new paradigm for investigating the problem, placing backbones in the spotlight and encouraging the development of consistent algorithms on top of them.
Position-Agnostic Autonomous Navigation in Vineyards with Deep Reinforcement Learning
Jun 28, 2022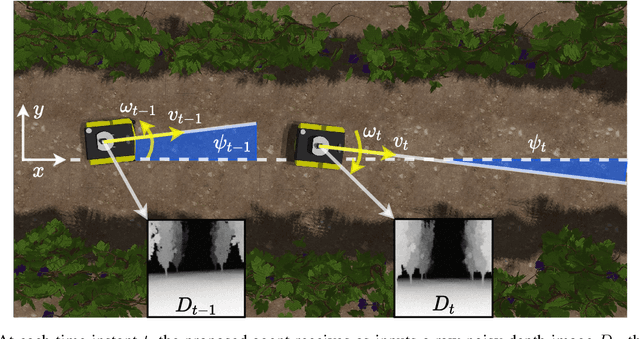

Precision agriculture is rapidly attracting research to efficiently introduce automation and robotics solutions to support agricultural activities. Robotic navigation in vineyards and orchards offers competitive advantages in autonomously monitoring and easily accessing crops for harvesting, spraying and performing time-consuming necessary tasks. Nowadays, autonomous navigation algorithms exploit expensive sensors which also require heavy computational cost for data processing. Nonetheless, vineyard rows represent a challenging outdoor scenario where GPS and Visual Odometry techniques often struggle to provide reliable positioning information. In this work, we combine Edge AI with Deep Reinforcement Learning to propose a cutting-edge lightweight solution to tackle the problem of autonomous vineyard navigation without exploiting precise localization data and overcoming task-tailored algorithms with a flexible learning-based approach. We train an end-to-end sensorimotor agent which directly maps noisy depth images and position-agnostic robot state information to velocity commands and guides the robot to the end of a row, continuously adjusting its heading for a collision-free central trajectory. Our extensive experimentation in realistic simulated vineyards demonstrates the effectiveness of our solution and the generalization capabilities of our agent.
Waypoint Generation in Row-based Crops with Deep Learning and Contrastive Clustering
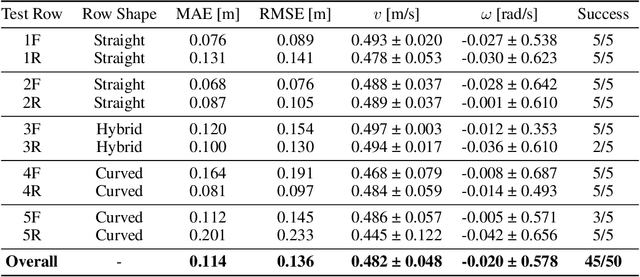
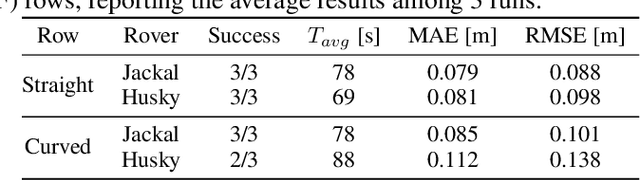
Jun 23, 2022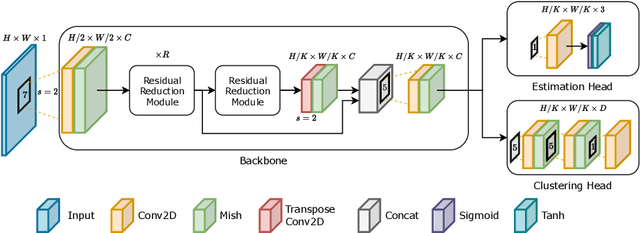

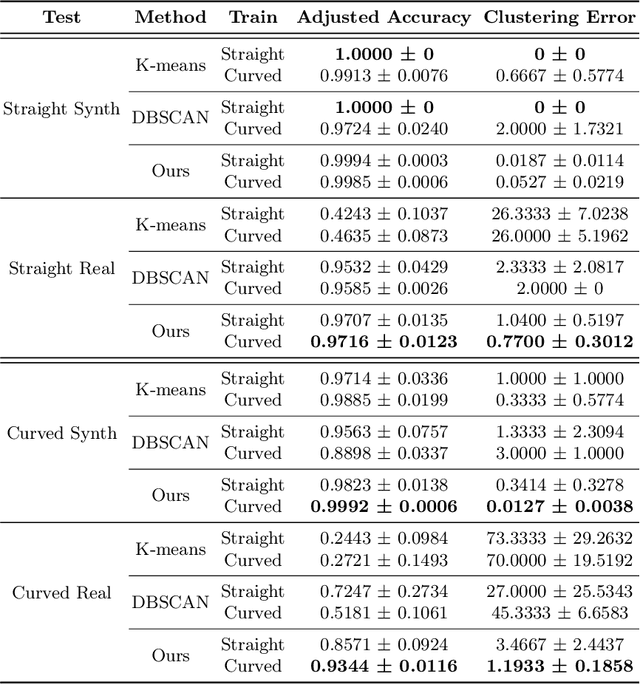
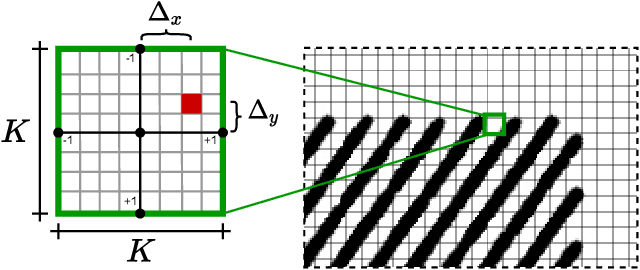
The development of precision agriculture has gradually introduced automation in the agricultural process to support and rationalize all the activities related to field management. In particular, service robotics plays a predominant role in this evolution by deploying autonomous agents able to navigate in fields while executing different tasks without the need for human intervention, such as monitoring, spraying and harvesting. In this context, global path planning is the first necessary step for every robotic mission and ensures that the navigation is performed efficiently and with complete field coverage. In this paper, we propose a learning-based approach to tackle waypoint generation for planning a navigation path for row-based crops, starting from a top-view map of the region-of-interest. We present a novel methodology for waypoint clustering based on a contrastive loss, able to project the points to a separable latent space. The proposed deep neural network can simultaneously predict the waypoint position and cluster assignment with two specialized heads in a single forward pass. The extensive experimentation on simulated and real-world images demonstrates that the proposed approach effectively solves the waypoint generation problem for both straight and curved row-based crops, overcoming the limitations of previous state-of-the-art methodologies.
A Deep Learning Driven Algorithmic Pipeline for Autonomous Navigation in Row-Based Crops
Dec 07, 2021
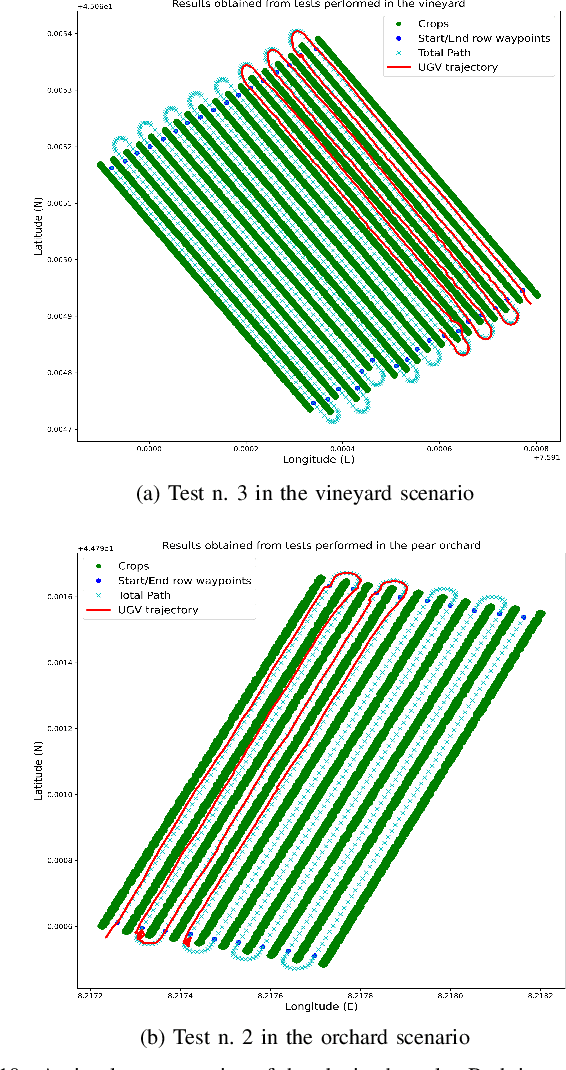
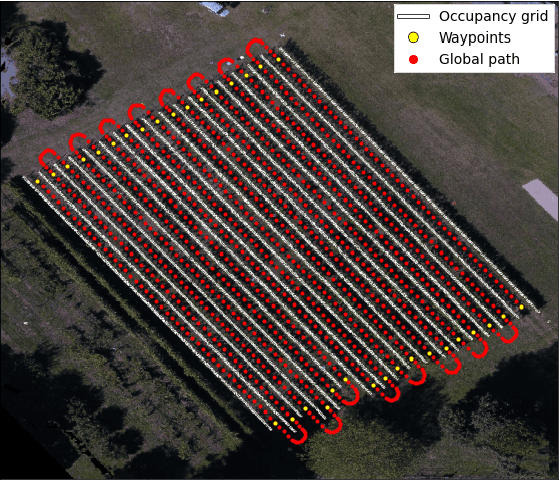
Expensive sensors and inefficient algorithmic pipelines significantly affect the overall cost of autonomous machines. However, affordable robotic solutions are essential to practical usage, and their financial impact constitutes a fundamental requirement to employ service robotics in most fields of application. Among all, researchers in the precision agriculture domain strive to devise robust and cost-effective autonomous platforms in order to provide genuinely large-scale competitive solutions. In this article, we present a complete algorithmic pipeline for row-based crops autonomous navigation, specifically designed to cope with low-range sensors and seasonal variations. Firstly, we build on a robust data-driven methodology to generate a viable path for the autonomous machine, covering the full extension of the crop with only the occupancy grid map information of the field. Moreover, our solution leverages on latest advancement of deep learning optimization techniques and synthetic generation of data to provide an affordable solution that efficiently tackles the well-known Global Navigation Satellite System unreliability and degradation due to vegetation growing inside rows. Extensive experimentation and simulations against computer-generated environments and real-world crops demonstrated the robustness and intrinsic generalizability of our methodology that opens the possibility of highly affordable and fully autonomous machines.
Action Transformer: A Self-Attention Model for Short-Time Human Action Recognition
Jul 06, 2021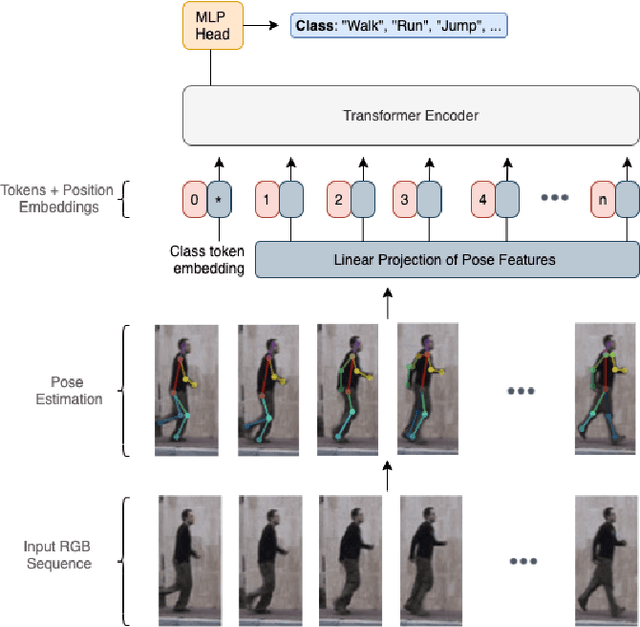
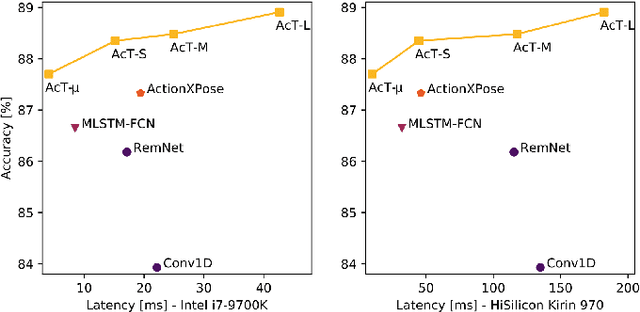
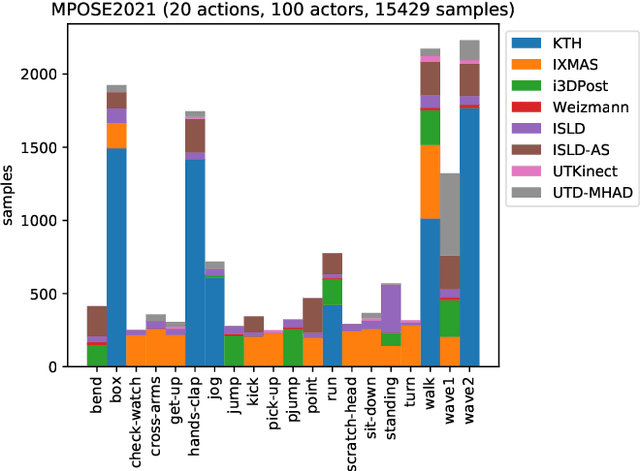

Deep neural networks based purely on attention have been successful across several domains, relying on minimal architectural priors from the designer. In Human Action Recognition (HAR), attention mechanisms have been primarily adopted on top of standard convolutional or recurrent layers, improving the overall generalization capability. In this work, we introduce Action Transformer (AcT), a simple, fully self-attentional architecture that consistently outperforms more elaborated networks that mix convolutional, recurrent, and attentive layers. In order to limit computational and energy requests, building on previous human action recognition research, the proposed approach exploits 2D pose representations over small temporal windows, providing a low latency solution for accurate and effective real-time performance. Moreover, we open-source MPOSE2021, a new large-scale dataset, as an attempt to build a formal training and evaluation benchmark for real-time short-time human action recognition. Extensive experimentation on MPOSE2021 with our proposed methodology and several previous architectural solutions proves the effectiveness of the AcT model and poses the base for future work on HAR.
Efficient-CapsNet: Capsule Network with Self-Attention Routing
Jan 29, 2021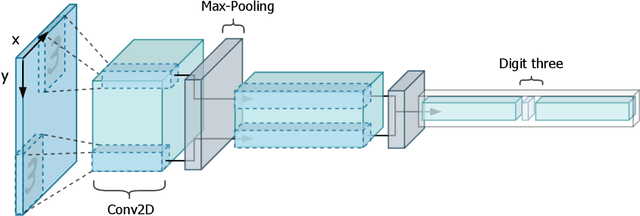

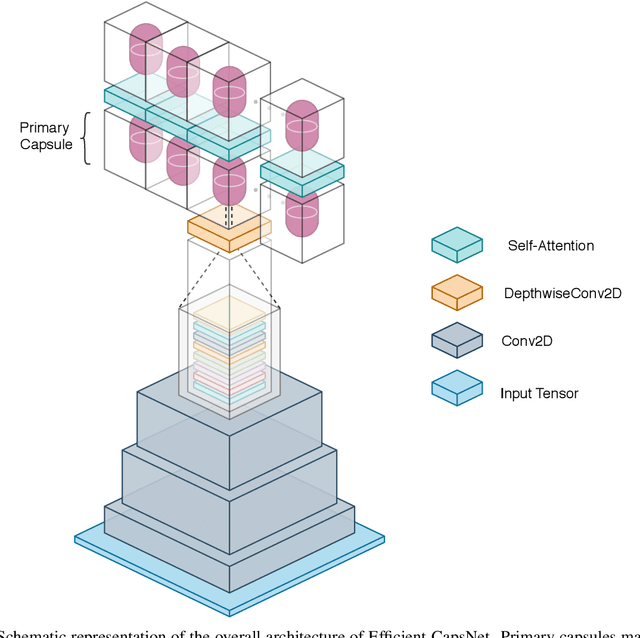
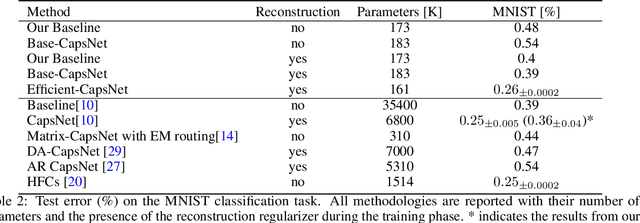
Deep convolutional neural networks, assisted by architectural design strategies, make extensive use of data augmentation techniques and layers with a high number of feature maps to embed object transformations. That is highly inefficient and for large datasets implies a massive redundancy of features detectors. Even though capsules networks are still in their infancy, they constitute a promising solution to extend current convolutional networks and endow artificial visual perception with a process to encode more efficiently all feature affine transformations. Indeed, a properly working capsule network should theoretically achieve higher results with a considerably lower number of parameters count due to intrinsic capability to generalize to novel viewpoints. Nevertheless, little attention has been given to this relevant aspect. In this paper, we investigate the efficiency of capsule networks and, pushing their capacity to the limits with an extreme architecture with barely 160K parameters, we prove that the proposed architecture is still able to achieve state-of-the-art results on three different datasets with only 2% of the original CapsNet parameters. Moreover, we replace dynamic routing with a novel non-iterative, highly parallelizable routing algorithm that can easily cope with a reduced number of capsules. Extensive experimentation with other capsule implementations has proved the effectiveness of our methodology and the capability of capsule networks to efficiently embed visual representations more prone to generalization.
Robust Ultra-wideband Range Error Mitigation with Deep Learning at the Edge
Nov 30, 2020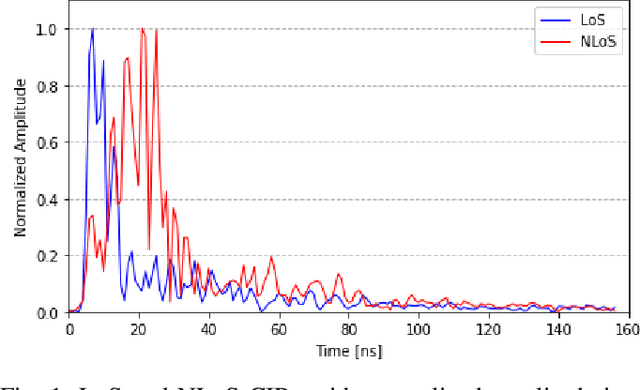
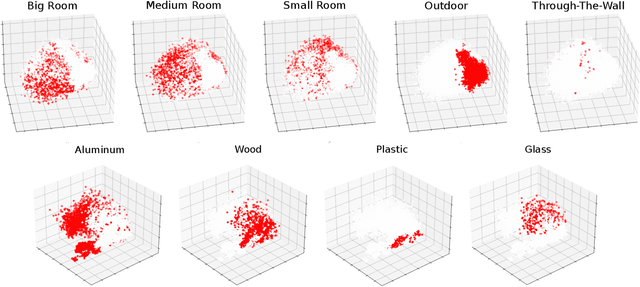
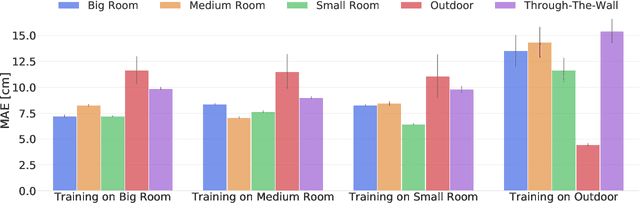
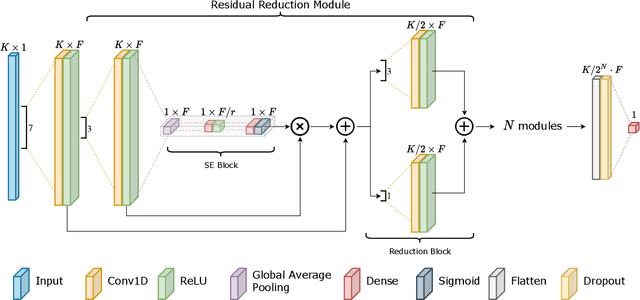
Ultra-wideband (UWB) is the state-of-the-art and most popular technology for wireless localization. Nevertheless, precise ranging and localization in non-line-of-sight (NLoS) conditions is still an open research topic. Indeed, multipath effects, reflections, refractions and complexity of the indoor radio environment can easily introduce a positive bias in the ranging measurement, resulting in highly inaccurate and unsatisfactory position estimation. This article proposes an efficient representation learning methodology that exploits the latest advancement in deep learning and graph optimization techniques to achieve effective ranging error mitigation at the edge. Channel Impulse Response (CIR) signals are directly exploited to extract high semantic features to estimate corrections in either NLoS or LoS conditions. Extensive experimentation with different settings and configurations have proved the effectiveness of our methodology and demonstrated the feasibility of a robust and low computational power UWB range error mitigation.