 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient-CapsNet: Capsule Network with Self-Attention Routing
Paper and Code

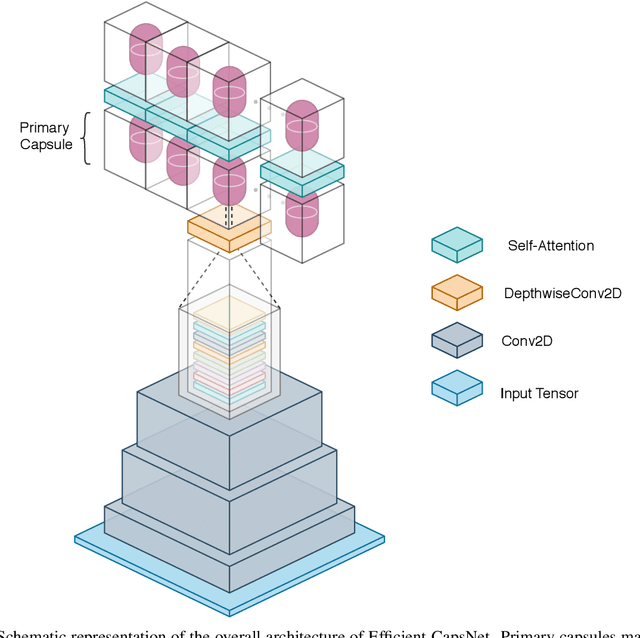
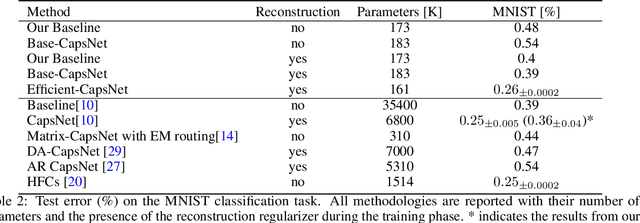
Deep convolutional neural networks, assisted by architectural design strategies, make extensive use of data augmentation techniques and layers with a high number of feature maps to embed object transformations. That is highly inefficient and for large datasets implies a massive redundancy of features detectors. Even though capsules networks are still in their infancy, they constitute a promising solution to extend current convolutional networks and endow artificial visual perception with a process to encode more efficiently all feature affine transformations. Indeed, a properly working capsule network should theoretically achieve higher results with a considerably lower number of parameters count due to intrinsic capability to generalize to novel viewpoints. Nevertheless, little attention has been given to this relevant aspect. In this paper, we investigate the efficiency of capsule networks and, pushing their capacity to the limits with an extreme architecture with barely 160K parameters, we prove that the proposed architecture is still able to achieve state-of-the-art results on three different datasets with only 2% of the original CapsNet parameters. Moreover, we replace dynamic routing with a novel non-iterative, highly parallelizable routing algorithm that can easily cope with a reduced number of capsules. Extensive experimentation with other capsule implementations has proved the effectiveness of our methodology and the capability of capsule networks to efficiently embed visual representations more prone to generalization.