 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Coach Assist: An Automated Approach for Call Recommendation in Contact Centers for Agent Coaching
May 28, 2023


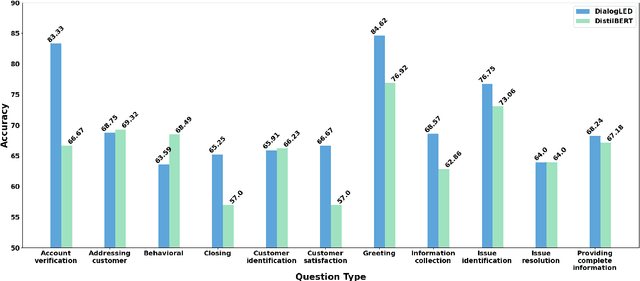
In recent years, the utilization of Artificial Intelligence (AI) in the contact center industry is on the rise. One area where AI can have a significant impact is in the coaching of contact center agents. By analyzing call transcripts using Natural Language Processing (NLP) techniques, it would be possible to quickly determine which calls are most relevant for coaching purposes. In this paper, we present AI Coach Assist, which leverages the pre-trained transformer-based language models to determine whether a given call is coachable or not based on the quality assurance (QA) questions asked by the contact center managers or supervisors. The system was trained and evaluated on a large dataset collected from real-world contact centers and provides an effective way to recommend calls to the contact center managers that are more likely to contain coachable moments. Our experimental findings demonstrate the potential of AI Coach Assist to improve the coaching process, resulting in enhancing the performance of contact center agents.
An Effective, Performant Named Entity Recognition System for Noisy Business Telephone Conversation Transcripts
Sep 27, 2022
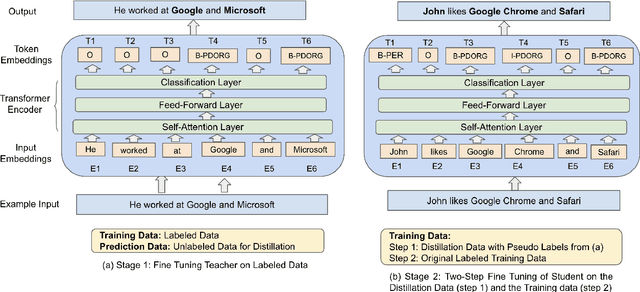
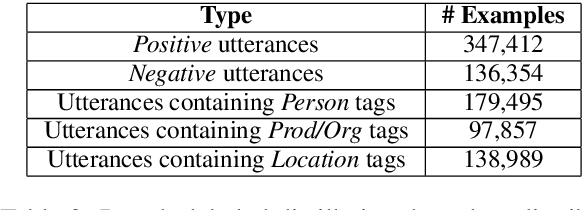
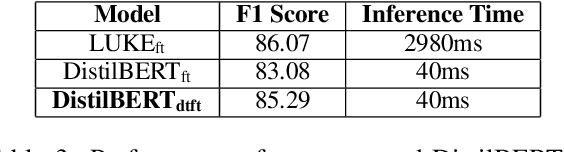
We present a simple yet effective method to train a named entity recognition (NER) model that operates on business telephone conversation transcripts that contain noise due to the nature of spoken conversation and artifacts of automatic speech recognition. We first fine-tune LUKE, a state-of-the-art Named Entity Recognition (NER) model, on a limited amount of transcripts, then use it as the teacher model to teach a smaller DistilBERT-based student model using a large amount of weakly labeled data and a small amount of human-annotated data. The model achieves high accuracy while also satisfying the practical constraints for inclusion in a commercial telephony product: realtime performance when deployed on cost-effective CPUs rather than GPUs.
Extracting Similar Questions From Naturally-occurring Business Conversations
Jun 03, 2022
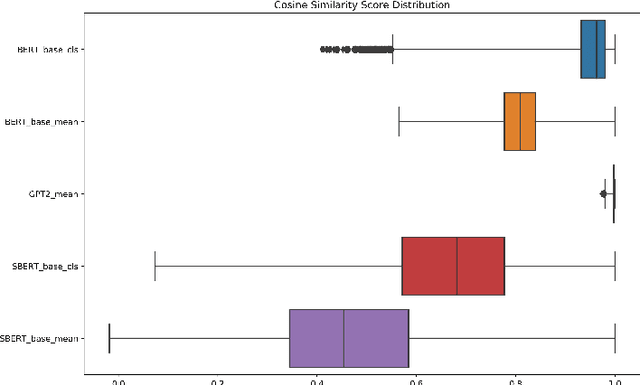
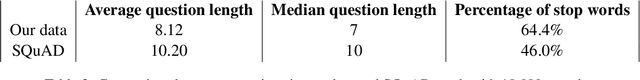
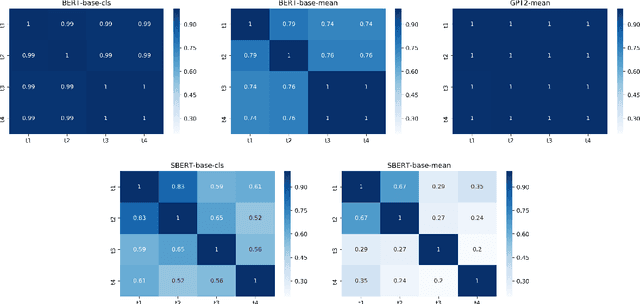
Pre-trained contextualized embedding models such as BERT are a standard building block in many natural language processing systems. We demonstrate that the sentence-level representations produced by some off-the-shelf contextualized embedding models have a narrow distribution in the embedding space, and thus perform poorly for the task of identifying semantically similar questions in real-world English business conversations. We describe a method that uses appropriately tuned representations and a small set of exemplars to group questions of interest to business users in a visualization that can be used for data exploration or employee coaching.
Punctuation Restoration in Spanish Customer Support Transcripts using Transfer Learning
May 27, 2022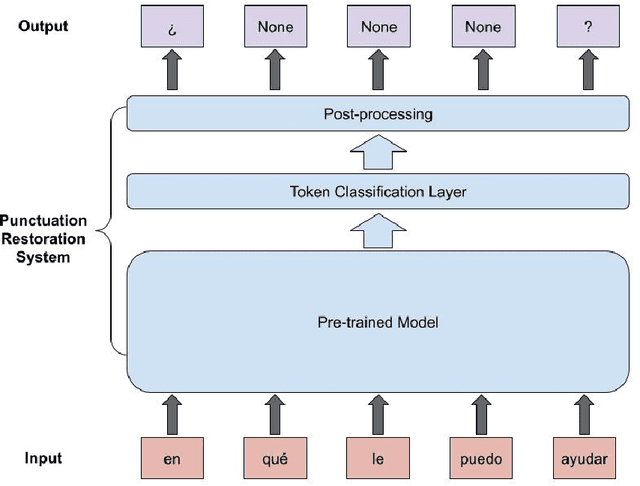
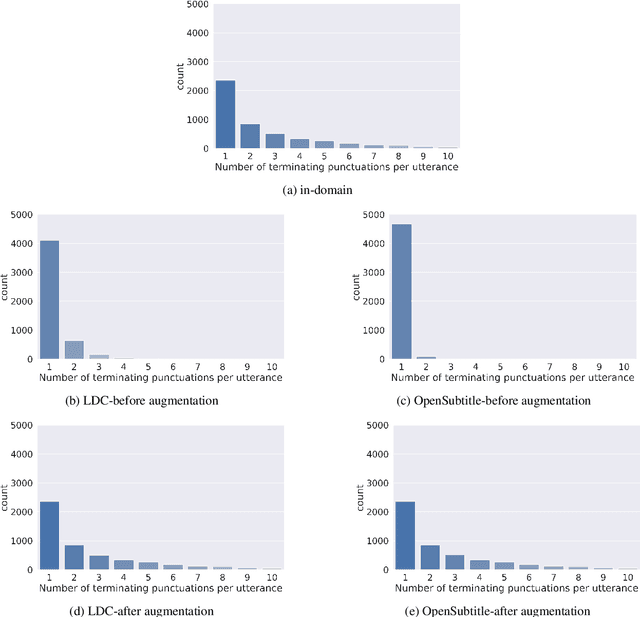

Automatic Speech Recognition (ASR) systems typically produce unpunctuated transcripts that have poor readability. In addition, building a punctuation restoration system is challenging for low-resource languages, especially for domain-specific applications. In this paper, we propose a Spanish punctuation restoration system designed for a real-time customer support transcription service. To address the data sparsity of Spanish transcripts in the customer support domain, we introduce two transfer-learning-based strategies: 1) domain adaptation using out-of-domain Spanish text data; 2) cross-lingual transfer learning leveraging in-domain English transcript data. Our experiment results show that these strategies improve the accuracy of the Spanish punctuation restoration system.
Developing a Production System for Purpose of Call Detection in Business Phone Conversations
May 13, 2022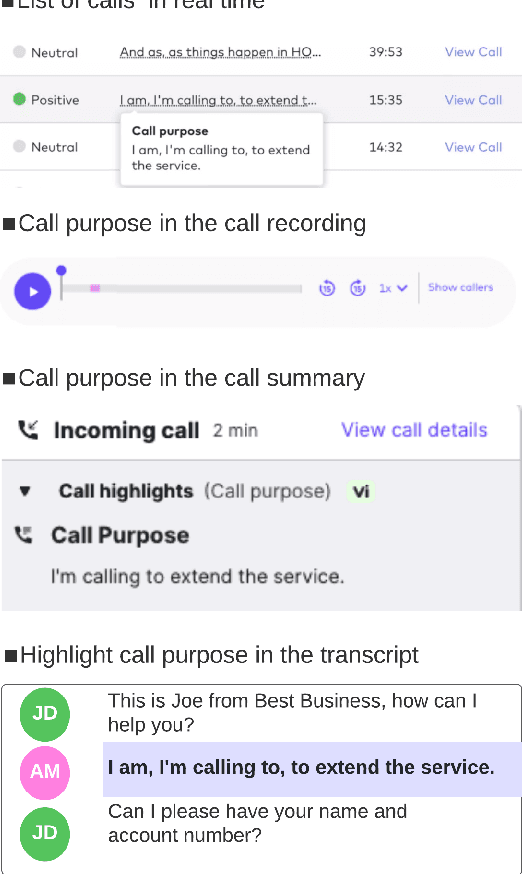
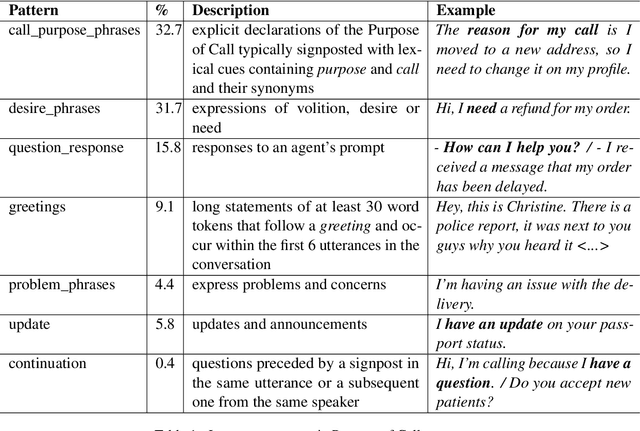
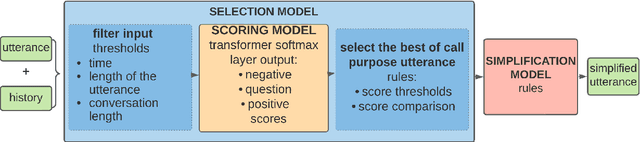
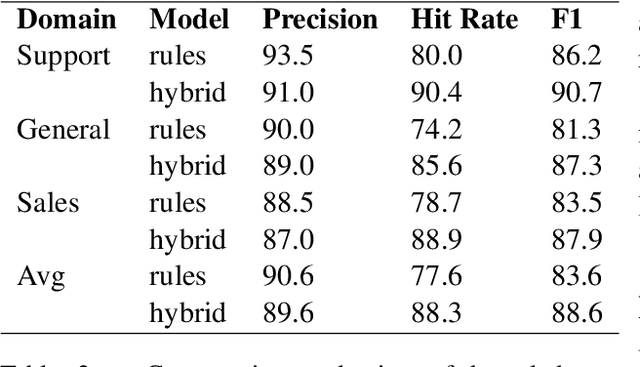
For agents at a contact centre receiving calls, the most important piece of information is the reason for a given call. An agent cannot provide support on a call if they do not know why a customer is calling. In this paper we describe our implementation of a commercial system to detect Purpose of Call statements in English business call transcripts in real time. We present a detailed analysis of types of Purpose of Call statements and language patterns related to them, discuss an approach to collect rich training data by bootstrapping from a set of rules to a neural model, and describe a hybrid model which consists of a transformer-based classifier and a set of rules by leveraging insights from the analysis of call transcripts. The model achieved 88.6 F1 on average in various types of business calls when tested on real life data and has low inference time. We reflect on the challenges and design decisions when developing and deploying the system.
BLINK with Elasticsearch for Efficient Entity Linking in Business Conversations
May 09, 2022
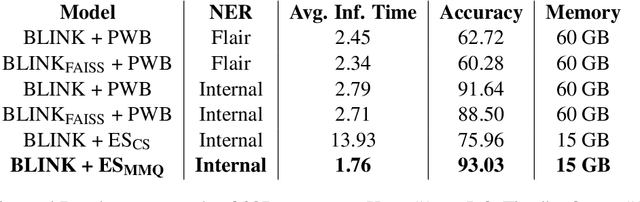
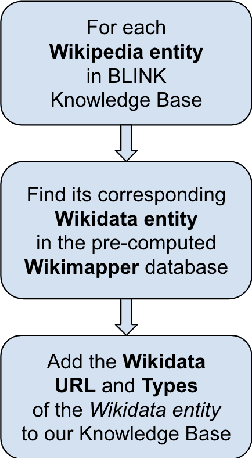
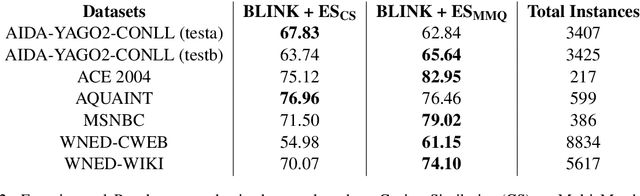
An Entity Linking system aligns the textual mentions of entities in a text to their corresponding entries in a knowledge base. However, deploying a neural entity linking system for efficient real-time inference in production environments is a challenging task. In this work, we present a neural entity linking system that connects the product and organization type entities in business conversations to their corresponding Wikipedia and Wikidata entries. The proposed system leverages Elasticsearch to ensure inference efficiency when deployed in a resource limited cloud machine, and obtains significant improvements in terms of inference speed and memory consumption while retaining high accuracy.
Improving Punctuation Restoration for Speech Transcripts via External Data
Oct 01, 2021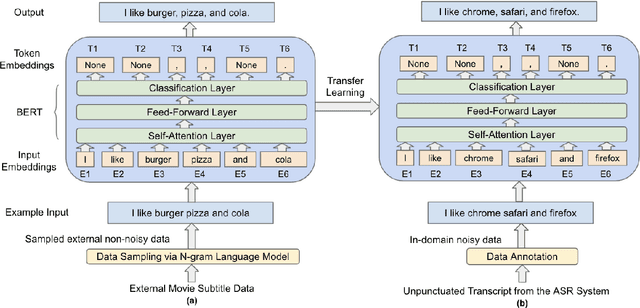

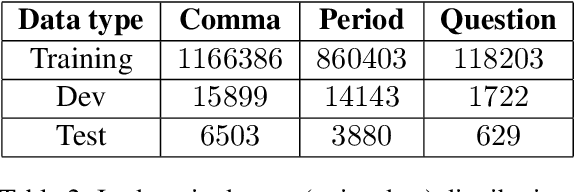

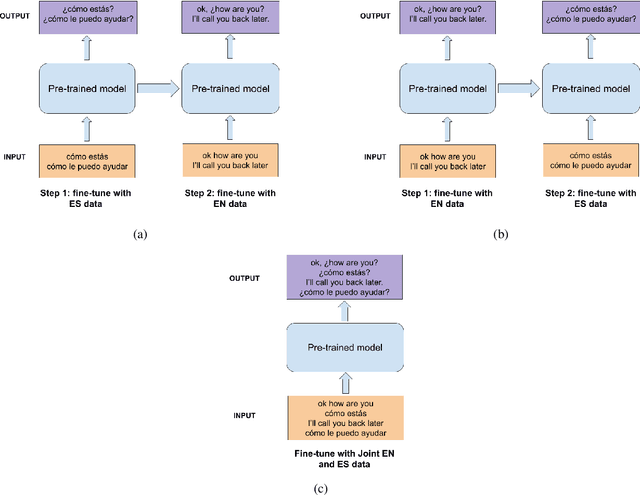
Automatic Speech Recognition (ASR) systems generally do not produce punctuated transcripts. To make transcripts more readable and follow the expected input format for downstream language models, it is necessary to add punctuation marks. In this paper, we tackle the punctuation restoration problem specifically for the noisy text (e.g., phone conversation scenarios). To leverage the available written text datasets, we introduce a data sampling technique based on an n-gram language model to sample more training data that are similar to our in-domain data. Moreover, we propose a two-stage fine-tuning approach that utilizes the sampled external data as well as our in-domain dataset for models based on BERT. Extensive experiments show that the proposed approach outperforms the baseline with an improvement of 1:12% F1 score.