Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Similar Questions From Naturally-occurring Business Conversations
Paper and Code
Jun 03, 2022
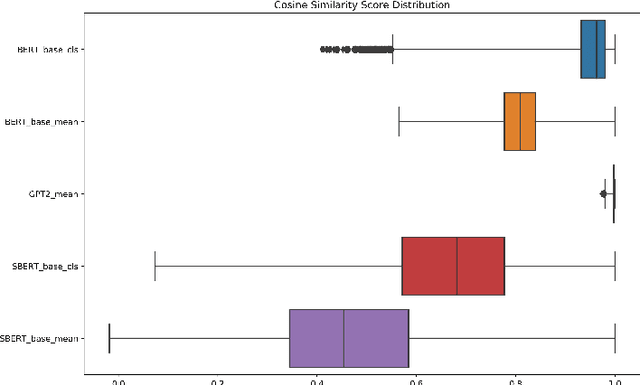
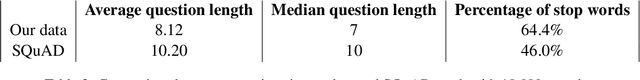
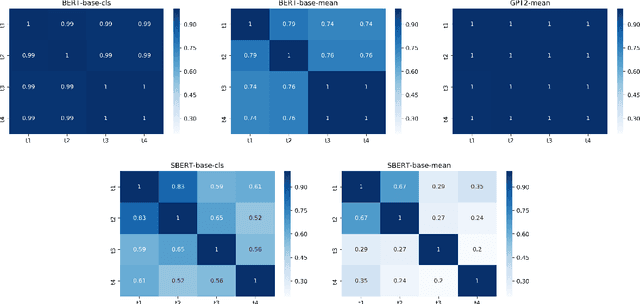
Pre-trained contextualized embedding models such as BERT are a standard building block in many natural language processing systems. We demonstrate that the sentence-level representations produced by some off-the-shelf contextualized embedding models have a narrow distribution in the embedding space, and thus perform poorly for the task of identifying semantically similar questions in real-world English business conversations. We describe a method that uses appropriately tuned representations and a small set of exemplars to group questions of interest to business users in a visualization that can be used for data exploration or employee coaching.
View paper on