 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Model Arena for Cross-lingual Sentiment Analysis: A Comparative Study in the Era of Large Language Models
Jun 27, 2024



Sentiment analysis serves as a pivotal component in Natural Language Processing (NLP). Advancements in multilingual pre-trained models such as XLM-R and mT5 have contributed to the increasing interest in cross-lingual sentiment analysis. The recent emergence in Large Language Models (LLM) has significantly advanced general NLP tasks, however, the capability of such LLMs in cross-lingual sentiment analysis has not been fully studied. This work undertakes an empirical analysis to compare the cross-lingual transfer capability of public Small Multilingual Language Models (SMLM) like XLM-R, against English-centric LLMs such as Llama-3, in the context of sentiment analysis across English, Spanish, French and Chinese. Our findings reveal that among public models, SMLMs exhibit superior zero-shot cross-lingual performance relative to LLMs. However, in few-shot cross-lingual settings, public LLMs demonstrate an enhanced adaptive potential. In addition, we observe that proprietary GPT-3.5 and GPT-4 lead in zero-shot cross-lingual capability, but are outpaced by public models in few-shot scenarios.
Resolving Transcription Ambiguity in Spanish: A Hybrid Acoustic-Lexical System for Punctuation Restoration
Feb 05, 2024

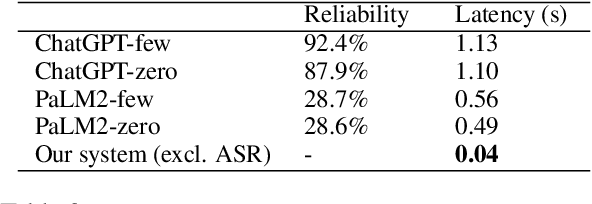

Punctuation restoration is a crucial step after Automatic Speech Recognition (ASR) systems to enhance transcript readability and facilitate subsequent NLP tasks. Nevertheless, conventional lexical-based approaches are inadequate for solving the punctuation restoration task in Spanish, where ambiguity can be often found between unpunctuated declaratives and questions. In this study, we propose a novel hybrid acoustic-lexical punctuation restoration system for Spanish transcription, which consolidates acoustic and lexical signals through a modular process. Our experiment results show that the proposed system can effectively improve F1 score of question marks and overall punctuation restoration on both public and internal Spanish conversational datasets. Additionally, benchmark comparison against LLMs (Large Language Model) indicates the superiority of our approach in accuracy, reliability and latency. Furthermore, we demonstrate that the Word Error Rate (WER) of the ASR module also benefits from our proposed system.
Entity-level Sentiment Analysis in Contact Center Telephone Conversations
Oct 26, 2022



Entity-level sentiment analysis predicts the sentiment about entities mentioned in a given text. It is very useful in a business context to understand user emotions towards certain entities, such as products or companies. In this paper, we demonstrate how we developed an entity-level sentiment analysis system that analyzes English telephone conversation transcripts in contact centers to provide business insight. We present two approaches, one entirely based on the transformer-based DistilBERT model, and another that uses a convolutional neural network supplemented with some heuristic rules.
Extracting Similar Questions From Naturally-occurring Business Conversations
Jun 03, 2022
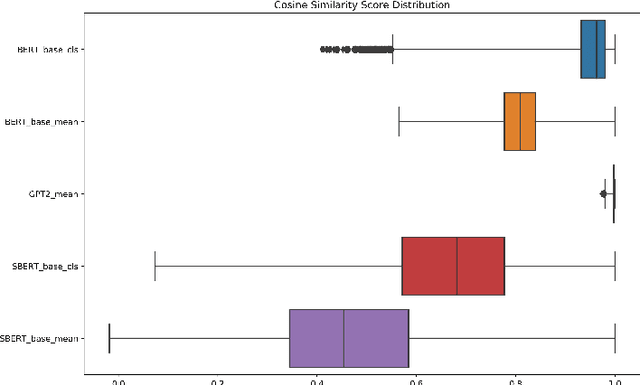
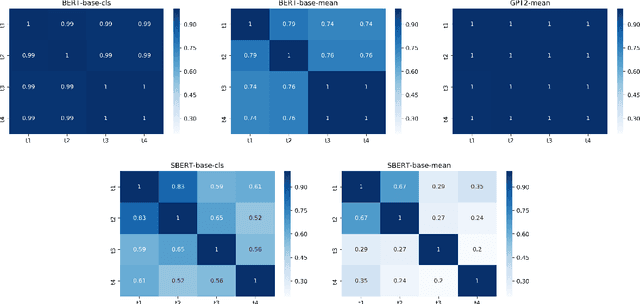
Pre-trained contextualized embedding models such as BERT are a standard building block in many natural language processing systems. We demonstrate that the sentence-level representations produced by some off-the-shelf contextualized embedding models have a narrow distribution in the embedding space, and thus perform poorly for the task of identifying semantically similar questions in real-world English business conversations. We describe a method that uses appropriately tuned representations and a small set of exemplars to group questions of interest to business users in a visualization that can be used for data exploration or employee coaching.
Punctuation Restoration in Spanish Customer Support Transcripts using Transfer Learning
May 27, 2022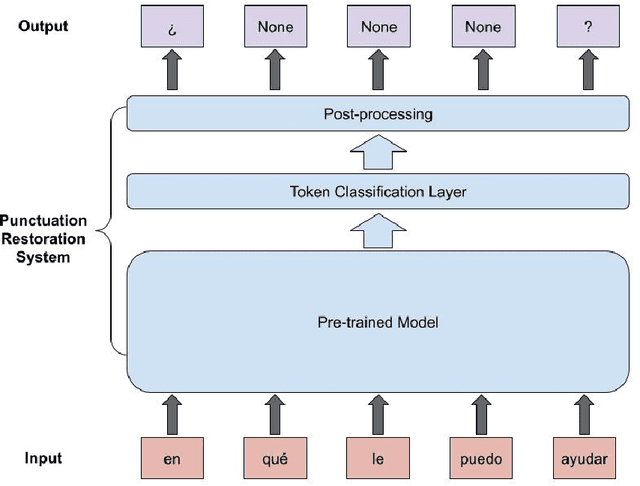
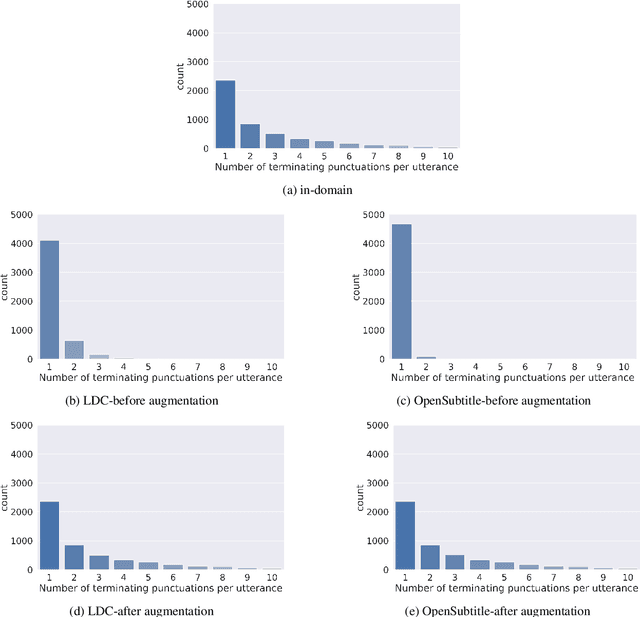

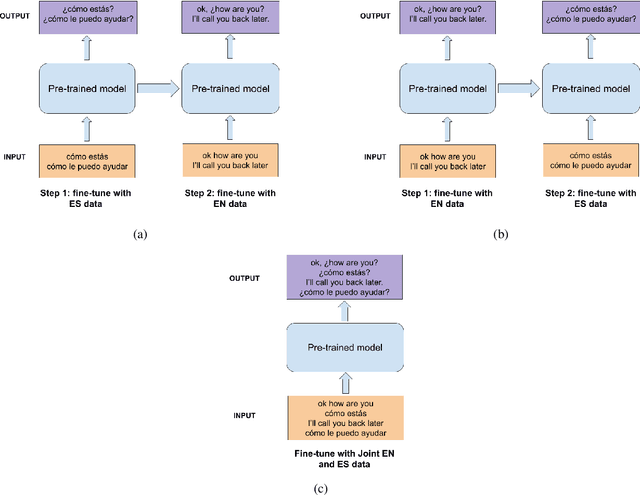
Automatic Speech Recognition (ASR) systems typically produce unpunctuated transcripts that have poor readability. In addition, building a punctuation restoration system is challenging for low-resource languages, especially for domain-specific applications. In this paper, we propose a Spanish punctuation restoration system designed for a real-time customer support transcription service. To address the data sparsity of Spanish transcripts in the customer support domain, we introduce two transfer-learning-based strategies: 1) domain adaptation using out-of-domain Spanish text data; 2) cross-lingual transfer learning leveraging in-domain English transcript data. Our experiment results show that these strategies improve the accuracy of the Spanish punctuation restoration system.
Developing a Production System for Purpose of Call Detection in Business Phone Conversations
May 13, 2022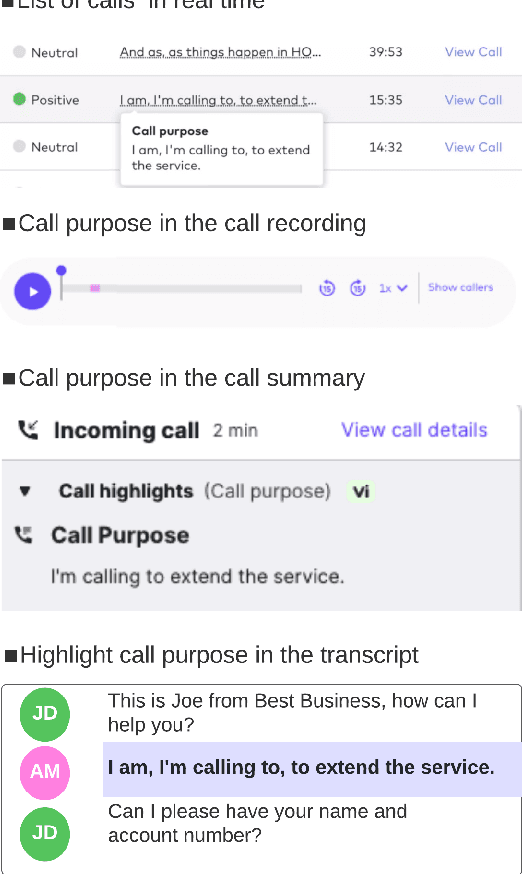
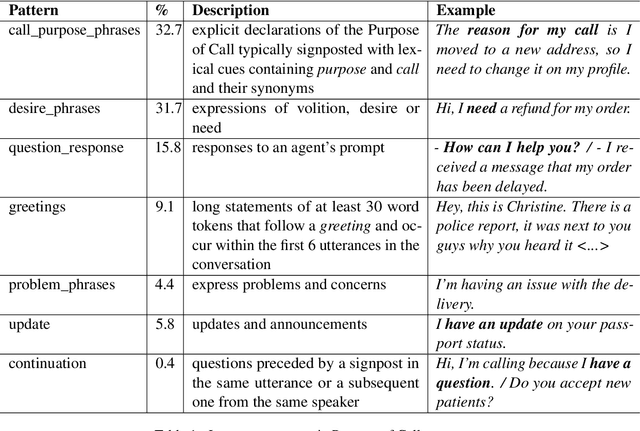
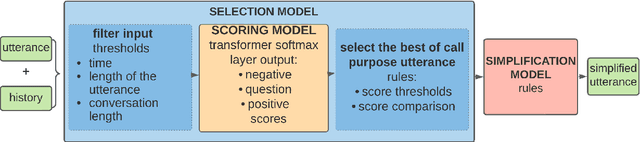
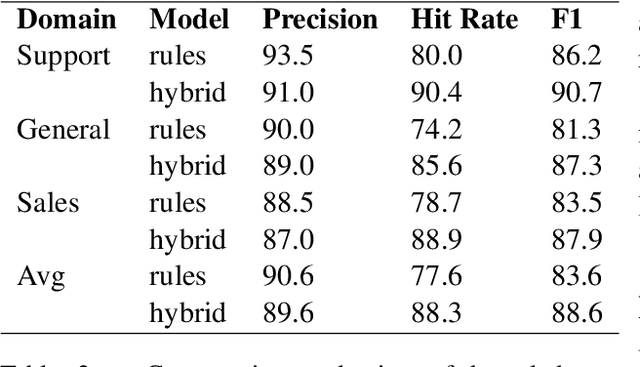
For agents at a contact centre receiving calls, the most important piece of information is the reason for a given call. An agent cannot provide support on a call if they do not know why a customer is calling. In this paper we describe our implementation of a commercial system to detect Purpose of Call statements in English business call transcripts in real time. We present a detailed analysis of types of Purpose of Call statements and language patterns related to them, discuss an approach to collect rich training data by bootstrapping from a set of rules to a neural model, and describe a hybrid model which consists of a transformer-based classifier and a set of rules by leveraging insights from the analysis of call transcripts. The model achieved 88.6 F1 on average in various types of business calls when tested on real life data and has low inference time. We reflect on the challenges and design decisions when developing and deploying the system.