 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Text to Voice: A Reproducible and Verifiable Framework for Evaluating Tool Calling LLM Agents
May 14, 2026Voice agents increasingly require reliable tool use from speech, whereas prominent tool-calling benchmarks remain text-based. We study whether verified text benchmarks can be converted into controlled audio-based tool calling evaluations without re-annotating the tool schema and gold labels. Our dataset-agnostic framework uses text-to-speech, speaker variation, and environmental noise to create paired text-audio instances while preserving the original dataset annotations. Based on extensive evaluation of 7 omni-modal models on audio-converted versions of Confetti and When2Call, our framework demonstrates that the performance is strongly model- and task-dependent: Gemini-3.1-Flash-Live obtains the highest Confetti score (70.4), whereas GPT-Realtime-1.5 performs best on When2Call (71.9). On Confetti, the text-to-voice gap ranges from 1.8 points for Qwen3-Omni to 4.8 points for GPT-Realtime-1.5. A targeted analysis of failure cases demonstrates that degradations most often reflect misunderstandings of argument values in the speech. Considering real-world deployment scenarios, we further report text-only results, an ambiguity-based reformulation stress test, and a reference-free LLM-as-judge protocol validated against human preferences. Notably, we find that open-source Qwen3 judges with at least 8B parameters exceed 80% agreement with proprietary judges, supporting privacy-preserving evaluation. Overall, our framework provides a verifiable and reproducible first-stage diagnostic that complements purpose-built audio corpora.
Resolving Transcription Ambiguity in Spanish: A Hybrid Acoustic-Lexical System for Punctuation Restoration
Feb 05, 2024

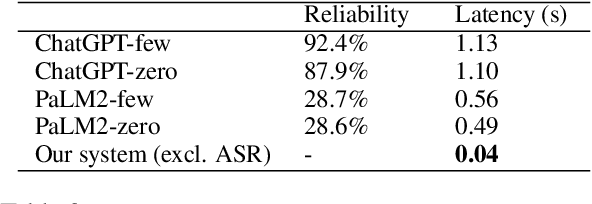

Punctuation restoration is a crucial step after Automatic Speech Recognition (ASR) systems to enhance transcript readability and facilitate subsequent NLP tasks. Nevertheless, conventional lexical-based approaches are inadequate for solving the punctuation restoration task in Spanish, where ambiguity can be often found between unpunctuated declaratives and questions. In this study, we propose a novel hybrid acoustic-lexical punctuation restoration system for Spanish transcription, which consolidates acoustic and lexical signals through a modular process. Our experiment results show that the proposed system can effectively improve F1 score of question marks and overall punctuation restoration on both public and internal Spanish conversational datasets. Additionally, benchmark comparison against LLMs (Large Language Model) indicates the superiority of our approach in accuracy, reliability and latency. Furthermore, we demonstrate that the Word Error Rate (WER) of the ASR module also benefits from our proposed system.
N-gram Boosting: Improving Contextual Biasing with Normalized N-gram Targets
Aug 04, 2023



Accurate transcription of proper names and technical terms is particularly important in speech-to-text applications for business conversations. These words, which are essential to understanding the conversation, are often rare and therefore likely to be under-represented in text and audio training data, creating a significant challenge in this domain. We present a two-step keyword boosting mechanism that successfully works on normalized unigrams and n-grams rather than just single tokens, which eliminates missing hits issues with boosting raw targets. In addition, we show how adjusting the boosting weight logic avoids over-boosting multi-token keywords. This improves our keyword recognition rate by 26% relative on our proprietary in-domain dataset and 2% on LibriSpeech. This method is particularly useful on targets that involve non-alphabetic characters or have non-standard pronunciations.
Comparison of SVD and factorized TDNN approaches for speech to text
Oct 13, 2021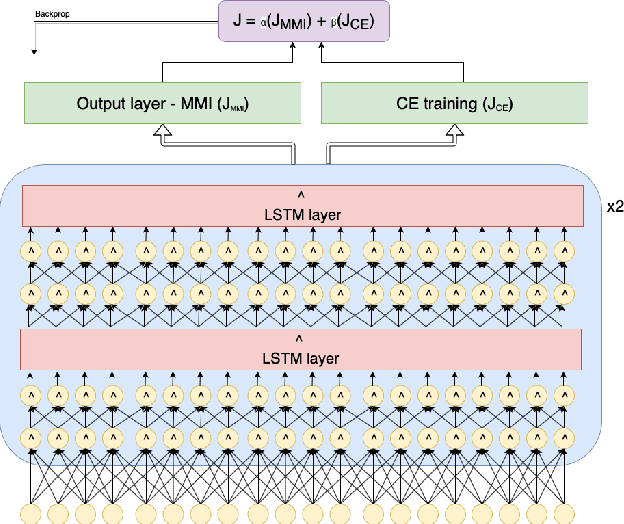

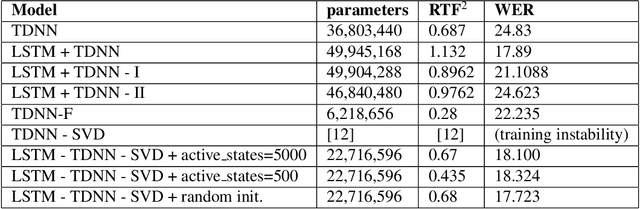

This work concentrates on reducing the RTF and word error rate of a hybrid HMM-DNN. Our baseline system uses an architecture with TDNN and LSTM layers. We find this architecture particularly useful for lightly reverberated environments. However, these models tend to demand more computation than is desirable. In this work, we explore alternate architectures employing singular value decomposition (SVD) is applied to the TDNN layers to reduce the RTF, as well as to the affine transforms of every LSTM cell. We compare this approach with specifying bottleneck layers similar to those introduced by SVD before training. Additionally, we reduced the search space of the decoding graph to make it a better fit to operate in real-time applications. We report -61.57% relative reduction in RTF and almost 1% relative decrease in WER for our architecture trained on Fisher data along with reverberated versions of this dataset in order to match one of our target test distributions.