 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-OPT: Optimizing Inference of Large Language Models via Multi-Query Instructions in Meeting Summarization
Feb 29, 2024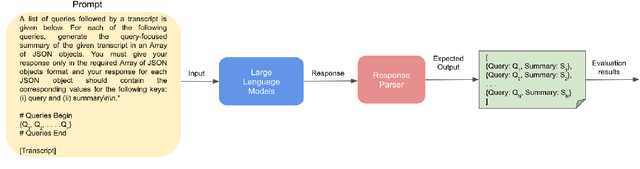

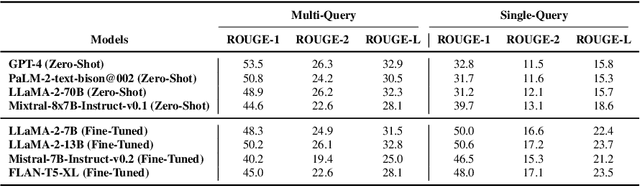
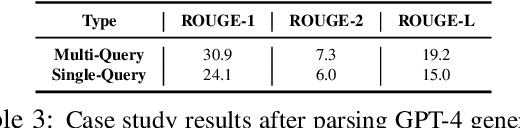
This work focuses on the task of query-based meeting summarization in which the summary of a context (meeting transcript) is generated in response to a specific query. When using Large Language Models (LLMs) for this task, a new call to the LLM inference endpoint/API is required for each new query even if the context stays the same. However, repeated calls to the LLM inference endpoints would significantly increase the costs of using them in production, making LLMs impractical for many real-world use cases. To address this problem, in this paper, we investigate whether combining the queries for the same input context in a single prompt to minimize repeated calls can be successfully used in meeting summarization. In this regard, we conduct extensive experiments by comparing the performance of various popular LLMs: GPT-4, PaLM-2, LLaMA-2, Mistral, and FLAN-T5 in single-query and multi-query settings. We observe that while most LLMs tend to respond to the multi-query instructions, almost all of them (except GPT-4), even after fine-tuning, could not properly generate the response in the required output format. We conclude that while multi-query prompting could be useful to optimize the inference costs by reducing calls to the inference endpoints/APIs for the task of meeting summarization, this capability to reliably generate the response in the expected format is only limited to certain LLMs.
Tiny Titans: Can Smaller Large Language Models Punch Above Their Weight in the Real World for Meeting Summarization?
Feb 01, 2024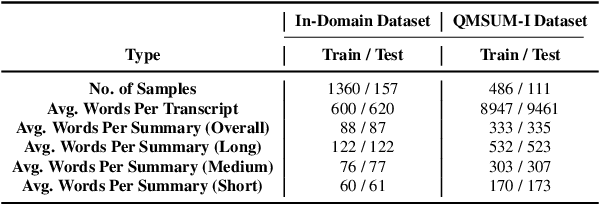
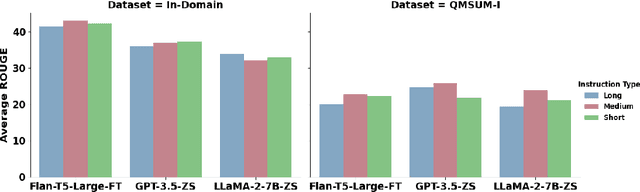
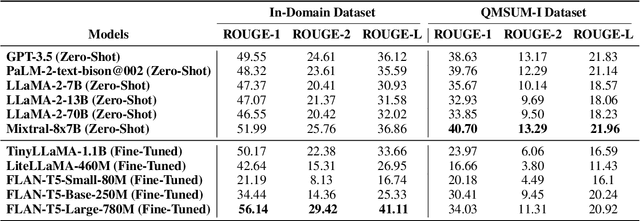

Large Language Models (LLMs) have demonstrated impressive capabilities to solve a wide range of tasks without being explicitly fine-tuned on task-specific datasets. However, deploying LLMs in the real world is not trivial, as it requires substantial computing resources. In this paper, we investigate whether smaller, compact LLMs are a good alternative to the comparatively Larger LLMs2 to address significant costs associated with utilizing LLMs in the real world. In this regard, we study the meeting summarization task in a real-world industrial environment and conduct extensive experiments by comparing the performance of fine-tuned compact LLMs (e.g., FLAN-T5, TinyLLaMA, LiteLLaMA) with zero-shot larger LLMs (e.g., LLaMA-2, GPT-3.5, PaLM-2). We observe that most smaller LLMs, even after fine-tuning, fail to outperform larger zero-shot LLMs in meeting summarization datasets. However, a notable exception is FLAN-T5 (780M parameters), which performs on par or even better than many zero-shot Larger LLMs (from 7B to above 70B parameters), while being significantly smaller. This makes compact LLMs like FLAN-T5 a suitable cost-efficient solution for real-world industrial deployment.
Building Real-World Meeting Summarization Systems using Large Language Models: A Practical Perspective
Nov 08, 2023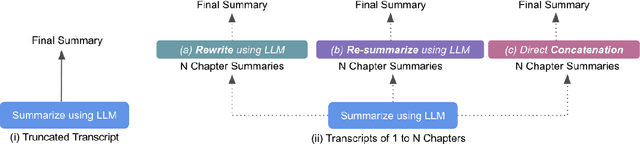
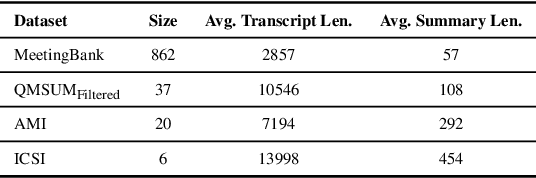
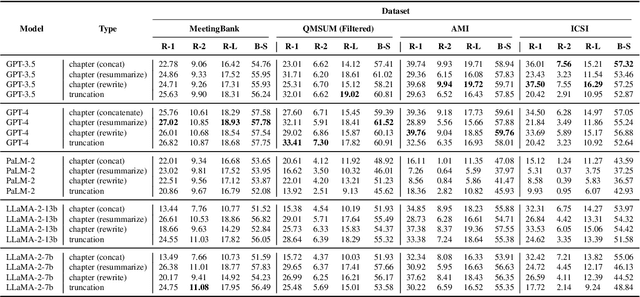
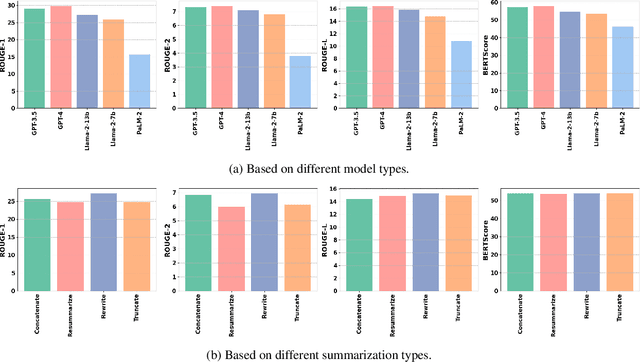
This paper studies how to effectively build meeting summarization systems for real-world usage using large language models (LLMs). For this purpose, we conduct an extensive evaluation and comparison of various closed-source and open-source LLMs, namely, GPT-4, GPT- 3.5, PaLM-2, and LLaMA-2. Our findings reveal that most closed-source LLMs are generally better in terms of performance. However, much smaller open-source models like LLaMA- 2 (7B and 13B) could still achieve performance comparable to the large closed-source models even in zero-shot scenarios. Considering the privacy concerns of closed-source models for only being accessible via API, alongside the high cost associated with using fine-tuned versions of the closed-source models, the opensource models that can achieve competitive performance are more advantageous for industrial use. Balancing performance with associated costs and privacy concerns, the LLaMA-2-7B model looks more promising for industrial usage. In sum, this paper offers practical insights on using LLMs for real-world business meeting summarization, shedding light on the trade-offs between performance and cost.
Are Large Language Models Reliable Judges? A Study on the Factuality Evaluation Capabilities of LLMs
Nov 01, 2023
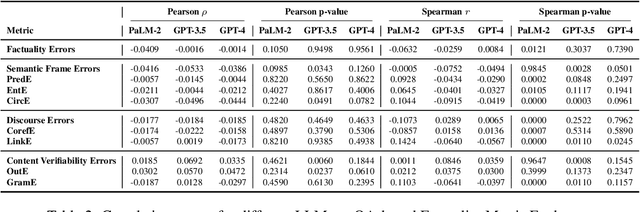
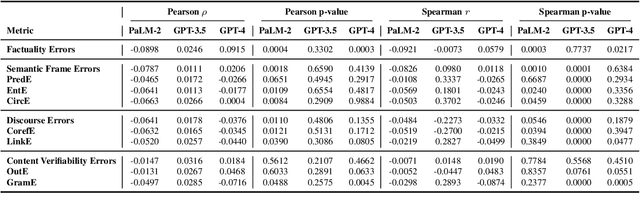
In recent years, Large Language Models (LLMs) have gained immense attention due to their notable emergent capabilities, surpassing those seen in earlier language models. A particularly intriguing application of LLMs is their role as evaluators for texts produced by various generative models. In this study, we delve into the potential of LLMs as reliable assessors of factual consistency in summaries generated by text-generation models. Initially, we introduce an innovative approach for factuality assessment using LLMs. This entails employing a singular LLM for the entirety of the question-answering-based factuality scoring process. Following this, we examine the efficacy of various LLMs in direct factuality scoring, benchmarking them against traditional measures and human annotations. Contrary to initial expectations, our results indicate a lack of significant correlations between factuality metrics and human evaluations, specifically for GPT-4 and PaLM-2. Notable correlations were only observed with GPT-3.5 across two factuality subcategories. These consistent findings across various factual error categories suggest a fundamental limitation in the current LLMs' capability to accurately gauge factuality. This version presents the information more concisely while maintaining the main points and findings of the original text.
AI Coach Assist: An Automated Approach for Call Recommendation in Contact Centers for Agent Coaching
May 28, 2023


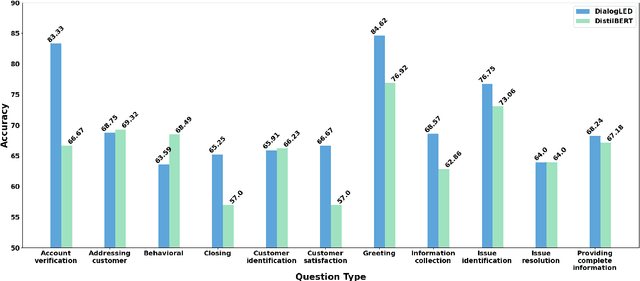
In recent years, the utilization of Artificial Intelligence (AI) in the contact center industry is on the rise. One area where AI can have a significant impact is in the coaching of contact center agents. By analyzing call transcripts using Natural Language Processing (NLP) techniques, it would be possible to quickly determine which calls are most relevant for coaching purposes. In this paper, we present AI Coach Assist, which leverages the pre-trained transformer-based language models to determine whether a given call is coachable or not based on the quality assurance (QA) questions asked by the contact center managers or supervisors. The system was trained and evaluated on a large dataset collected from real-world contact centers and provides an effective way to recommend calls to the contact center managers that are more likely to contain coachable moments. Our experimental findings demonstrate the potential of AI Coach Assist to improve the coaching process, resulting in enhancing the performance of contact center agents.
Improving Named Entity Recognition in Telephone Conversations via Effective Active Learning with Human in the Loop
Nov 02, 2022
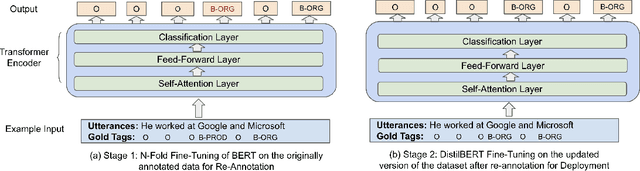
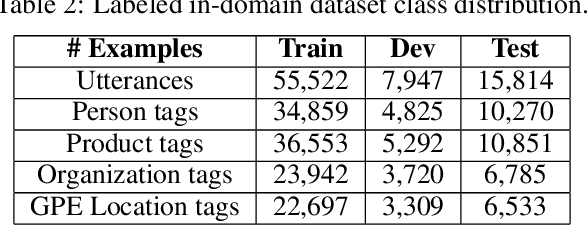
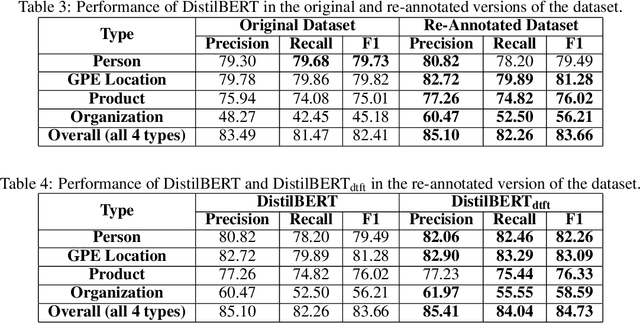
Telephone transcription data can be very noisy due to speech recognition errors, disfluencies, etc. Not only that annotating such data is very challenging for the annotators, but also such data may have lots of annotation errors even after the annotation job is completed, resulting in a very poor model performance. In this paper, we present an active learning framework that leverages human in the loop learning to identify data samples from the annotated dataset for re-annotation that are more likely to contain annotation errors. In this way, we largely reduce the need for data re-annotation for the whole dataset. We conduct extensive experiments with our proposed approach for Named Entity Recognition and observe that by re-annotating only about 6% training instances out of the whole dataset, the F1 score for a certain entity type can be significantly improved by about 25%.
Entity-level Sentiment Analysis in Contact Center Telephone Conversations
Oct 26, 2022



Entity-level sentiment analysis predicts the sentiment about entities mentioned in a given text. It is very useful in a business context to understand user emotions towards certain entities, such as products or companies. In this paper, we demonstrate how we developed an entity-level sentiment analysis system that analyzes English telephone conversation transcripts in contact centers to provide business insight. We present two approaches, one entirely based on the transformer-based DistilBERT model, and another that uses a convolutional neural network supplemented with some heuristic rules.
An Effective, Performant Named Entity Recognition System for Noisy Business Telephone Conversation Transcripts
Sep 27, 2022
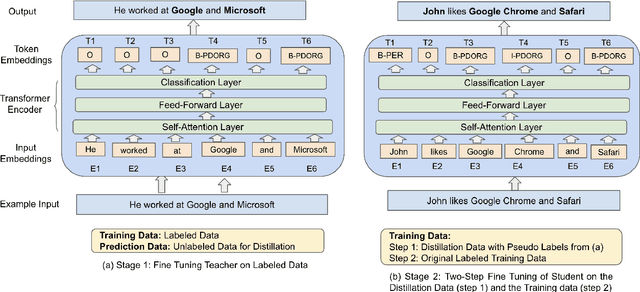
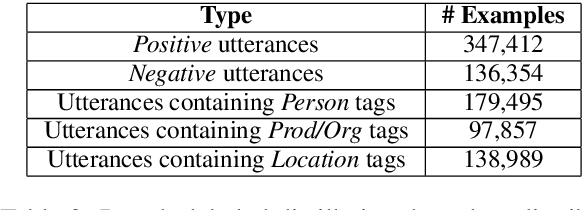
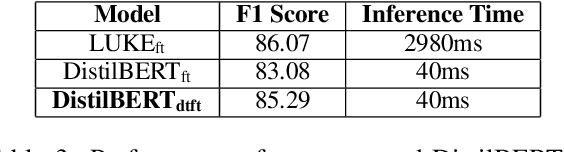
We present a simple yet effective method to train a named entity recognition (NER) model that operates on business telephone conversation transcripts that contain noise due to the nature of spoken conversation and artifacts of automatic speech recognition. We first fine-tune LUKE, a state-of-the-art Named Entity Recognition (NER) model, on a limited amount of transcripts, then use it as the teacher model to teach a smaller DistilBERT-based student model using a large amount of weakly labeled data and a small amount of human-annotated data. The model achieves high accuracy while also satisfying the practical constraints for inclusion in a commercial telephony product: realtime performance when deployed on cost-effective CPUs rather than GPUs.
Developing a Production System for Purpose of Call Detection in Business Phone Conversations
May 13, 2022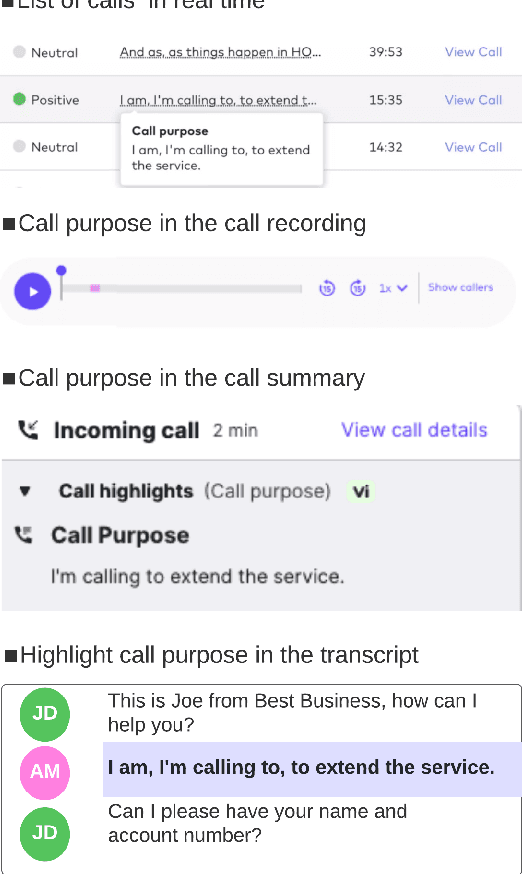
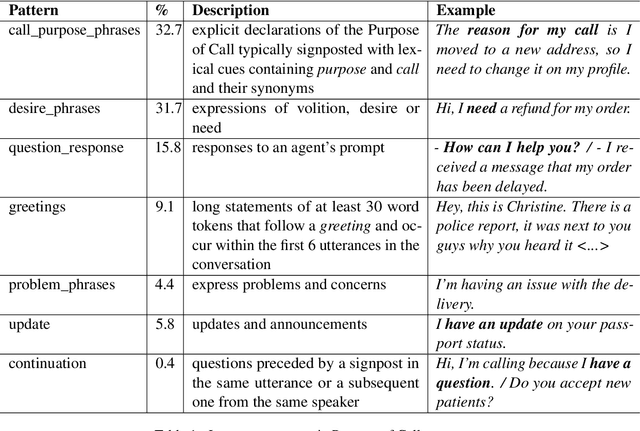
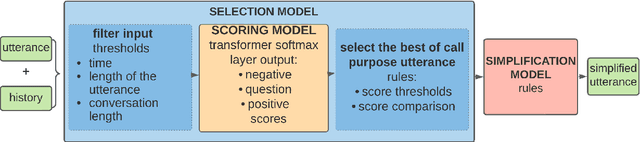
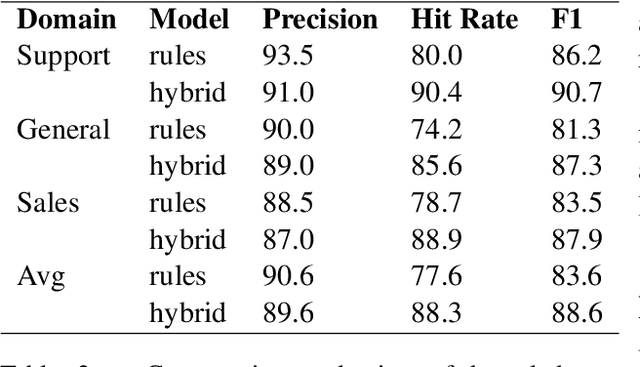
For agents at a contact centre receiving calls, the most important piece of information is the reason for a given call. An agent cannot provide support on a call if they do not know why a customer is calling. In this paper we describe our implementation of a commercial system to detect Purpose of Call statements in English business call transcripts in real time. We present a detailed analysis of types of Purpose of Call statements and language patterns related to them, discuss an approach to collect rich training data by bootstrapping from a set of rules to a neural model, and describe a hybrid model which consists of a transformer-based classifier and a set of rules by leveraging insights from the analysis of call transcripts. The model achieved 88.6 F1 on average in various types of business calls when tested on real life data and has low inference time. We reflect on the challenges and design decisions when developing and deploying the system.
BLINK with Elasticsearch for Efficient Entity Linking in Business Conversations
May 09, 2022
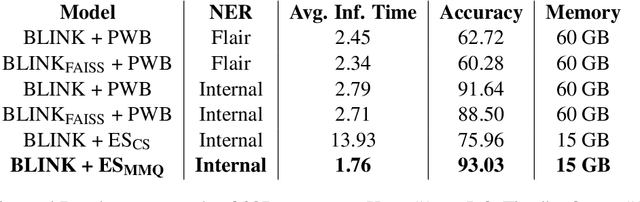
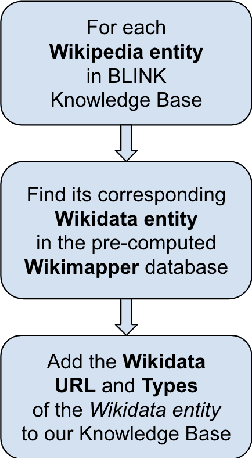
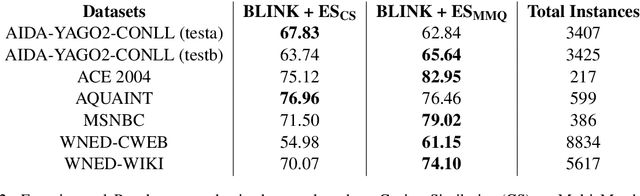
An Entity Linking system aligns the textual mentions of entities in a text to their corresponding entries in a knowledge base. However, deploying a neural entity linking system for efficient real-time inference in production environments is a challenging task. In this work, we present a neural entity linking system that connects the product and organization type entities in business conversations to their corresponding Wikipedia and Wikidata entries. The proposed system leverages Elasticsearch to ensure inference efficiency when deployed in a resource limited cloud machine, and obtains significant improvements in terms of inference speed and memory consumption while retaining high accuracy.