 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-OPT: Optimizing Inference of Large Language Models via Multi-Query Instructions in Meeting Summarization
Paper and Code
Feb 29, 2024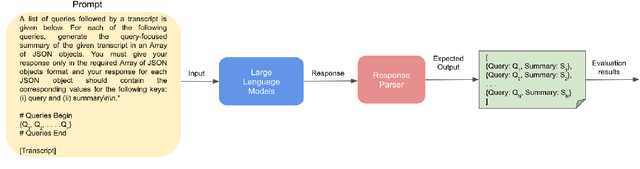

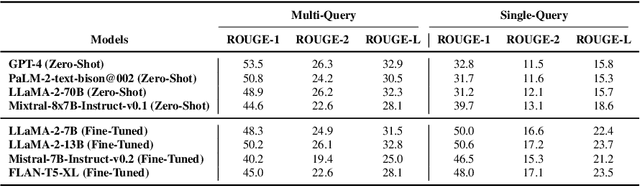
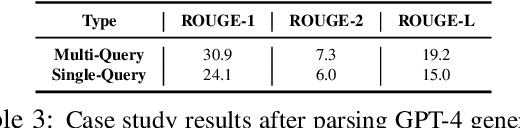
This work focuses on the task of query-based meeting summarization in which the summary of a context (meeting transcript) is generated in response to a specific query. When using Large Language Models (LLMs) for this task, a new call to the LLM inference endpoint/API is required for each new query even if the context stays the same. However, repeated calls to the LLM inference endpoints would significantly increase the costs of using them in production, making LLMs impractical for many real-world use cases. To address this problem, in this paper, we investigate whether combining the queries for the same input context in a single prompt to minimize repeated calls can be successfully used in meeting summarization. In this regard, we conduct extensive experiments by comparing the performance of various popular LLMs: GPT-4, PaLM-2, LLaMA-2, Mistral, and FLAN-T5 in single-query and multi-query settings. We observe that while most LLMs tend to respond to the multi-query instructions, almost all of them (except GPT-4), even after fine-tuning, could not properly generate the response in the required output format. We conclude that while multi-query prompting could be useful to optimize the inference costs by reducing calls to the inference endpoints/APIs for the task of meeting summarization, this capability to reliably generate the response in the expected format is only limited to certain LLMs.