 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Punctuation Restoration for Speech Transcripts via External Data
Paper and Code
Oct 01, 2021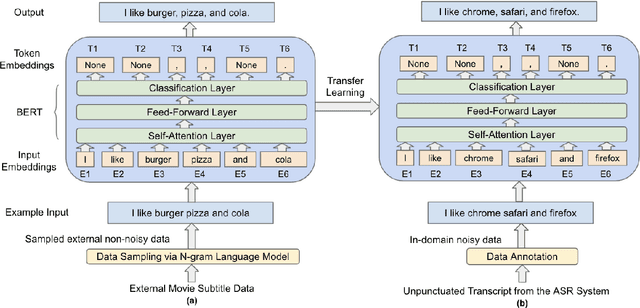

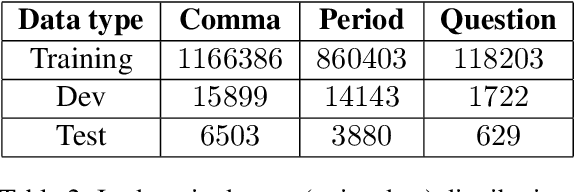

Automatic Speech Recognition (ASR) systems generally do not produce punctuated transcripts. To make transcripts more readable and follow the expected input format for downstream language models, it is necessary to add punctuation marks. In this paper, we tackle the punctuation restoration problem specifically for the noisy text (e.g., phone conversation scenarios). To leverage the available written text datasets, we introduce a data sampling technique based on an n-gram language model to sample more training data that are similar to our in-domain data. Moreover, we propose a two-stage fine-tuning approach that utilizes the sampled external data as well as our in-domain dataset for models based on BERT. Extensive experiments show that the proposed approach outperforms the baseline with an improvement of 1:12% F1 score.