 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Progressive Rethinking and Collaborative Learning: A Deep Framework for In-Loop Filtering
Jan 21, 2020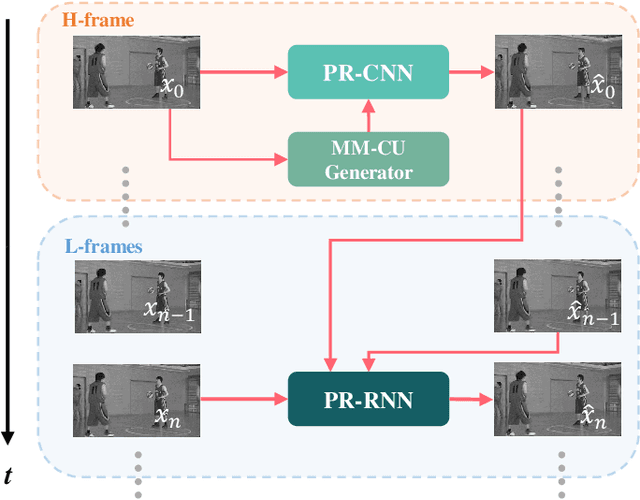
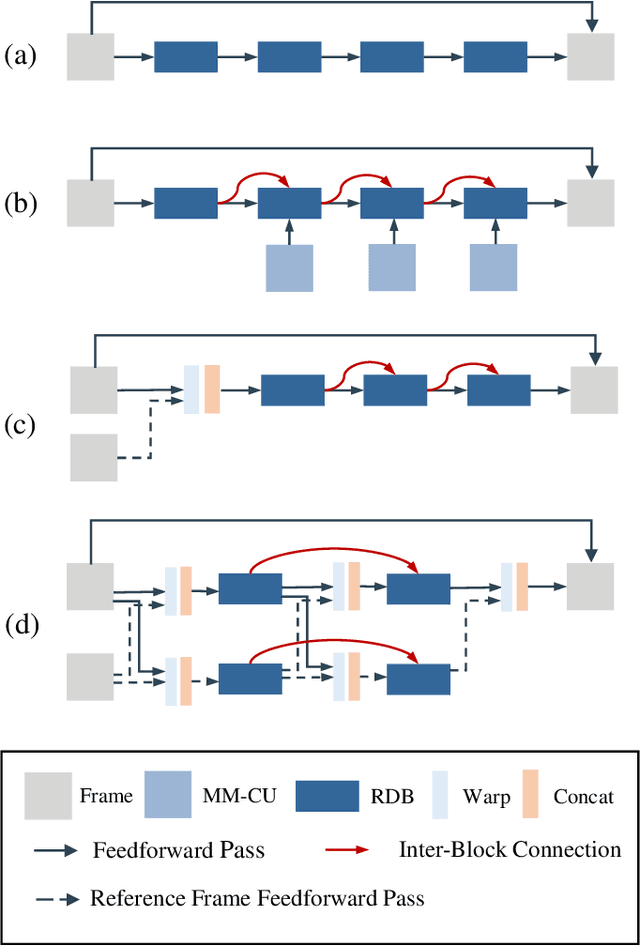
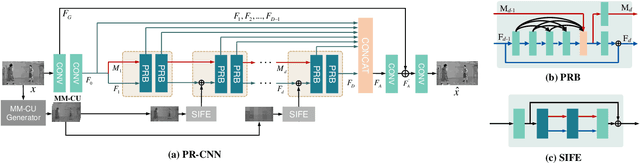
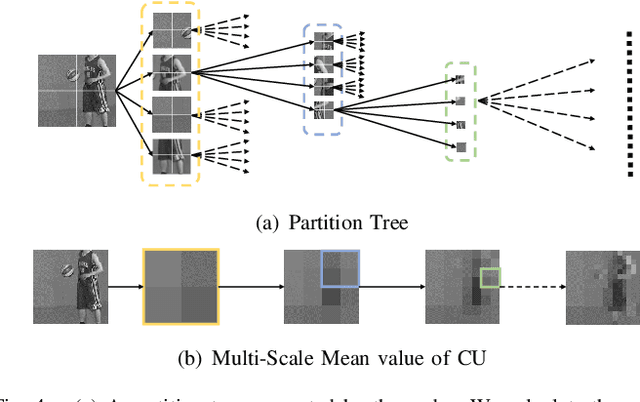
In this paper, we aim to address two critical issues in deep-learning based in-loop filter of modern codecs: 1) how to model spatial and temporal redundancies more effectively in the coding scenario; 2) what kinds of side information (side-info) can be inferred from the codecs to benefit in-loop filter models and how this side-info is injected. For the first issue, we design a deep network with both progressive rethinking and collaborative learning mechanisms to improve quality of the reconstructed intra-frames and inter-frames, respectively. For intra coding, a Progressive Rethinking Block (PRB) and its stacked Progressive Rethinking Network (PRN) are designed to simulate the human decision mechanism for effective spatial modeling. The typical cascaded deep network utilizes a bottleneck module at the end of each block to reduce the dimension size of the feature to generate the summarization of past experiences. Our designed block rethinks progressively, namely introducing an additional inter-block connection to bypass a high-dimensional informative feature across blocks to review the complete past memorized experiences. For inter coding, the model learns collaboratively for temporal modeling. The current reconstructed frame interacts with reference frames (peak quality frame and the nearest adjacent frame) progressively at the feature level. For the second issue, side-info utilization, we extract both intra-frame and interframe side-info for a better context modeling. A coarse-tofine partition map based on HEVC partition trees is built as the intra-frame side-info. Furthermore, the warped features of the reference frames are offered as the inter-frame side-info. Benefiting from our subtle design, under All-Intra (AI), Low-Delay B (LDB), Low-Delay P (LDP) and Random Access (RA) configuration, our PRNs provide 9.0%, 9.0%, 10.6% and 8.0% BD-rate reduction on average respectively.
An Emerging Coding Paradigm VCM: A Scalable Coding Approach Beyond Feature and Signal
Jan 09, 2020
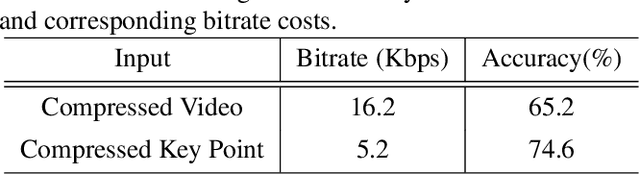

In this paper, we study a new problem arising from the emerging MPEG standardization effort Video Coding for Machine (VCM), which aims to bridge the gap between visual feature compression and classical video coding. VCM is committed to address the requirement of compact signal representation for both machine and human vision in a more or less scalable way. To this end, we make endeavors in leveraging the strength of predictive and generative models to support advanced compression techniques for both machine and human vision tasks simultaneously, in which visual features serve as a bridge to connect signal-level and task-level compact representations in a scalable manner. Specifically, we employ a conditional deep generation network to reconstruct video frames with the guidance of learned motion pattern. By learning to extract sparse motion pattern via a predictive model, the network elegantly leverages the feature representation to generate the appearance of to-be-coded frames via a generative model, relying on the appearance of the coded key frames. Meanwhile, the sparse motion pattern is compact and highly effective for high-level vision tasks, e.g. action recognition. Experimental results demonstrate that our method yields much better reconstruction quality compared with the traditional video codecs (0.0063 gain in SSIM), as well as state-of-the-art action recognition performance over highly compressed videos (9.4% gain in recognition accuracy), which showcases a promising paradigm of coding signal for both human and machine vision.
A Comprehensive Benchmark for Single Image Compression Artifacts Reduction
Sep 09, 2019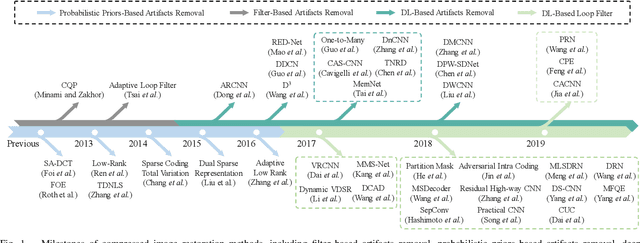
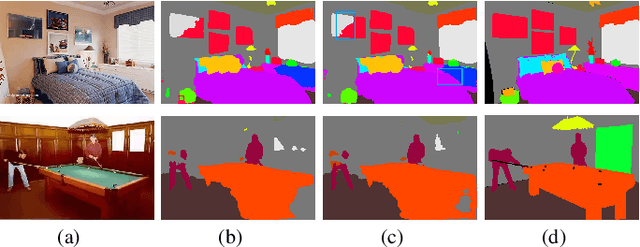
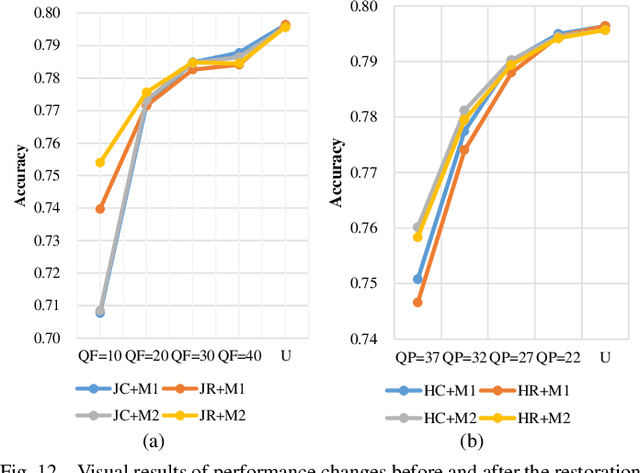
We present a comprehensive study and evaluation of existing single image compression artifacts removal algorithms, using a new 4K resolution benchmark including diversified foreground objects and background scenes with rich structures, called Large-scale Ideal Ultra high definition 4K (LIU4K) benchmark. Compression artifacts removal, as a common post-processing technique, aims at alleviating undesirable artifacts such as blockiness, ringing, and banding caused by quantization and approximation in the compression process. In this work, a systematic listing of the reviewed methods is presented based on their basic models (handcrafted models and deep networks). The main contributions and novelties of these methods are highlighted, and the main development directions, including architectures, multi-domain sources, signal structures, and new targeted units, are summarized. Furthermore, based on a unified deep learning configuration (i.e. same training data, loss function, optimization algorithm, etc.), we evaluate recent deep learning-based methods based on diversified evaluation measures. The experimental results show the state-of-the-art performance comparison of existing methods based on both full-reference, non-reference and task-driven metrics. Our survey would give a comprehensive reference source for future research on single image compression artifacts removal and inspire new directions of the related fields.
Deep Reference Generation with Multi-Domain Hierarchical Constraints for Inter Prediction
May 16, 2019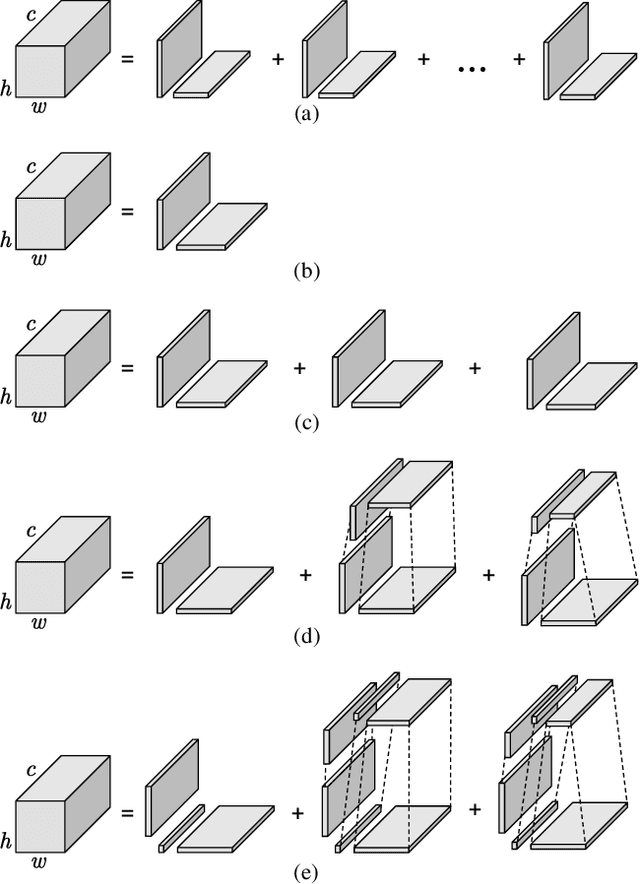
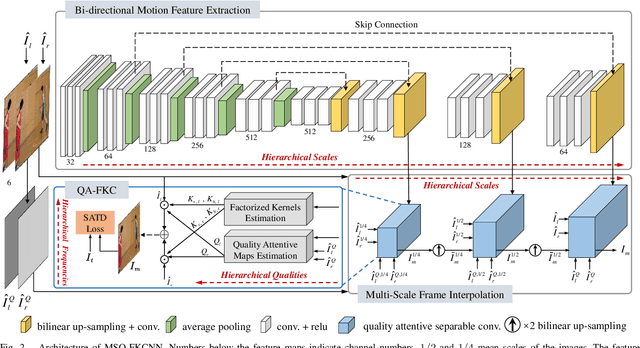
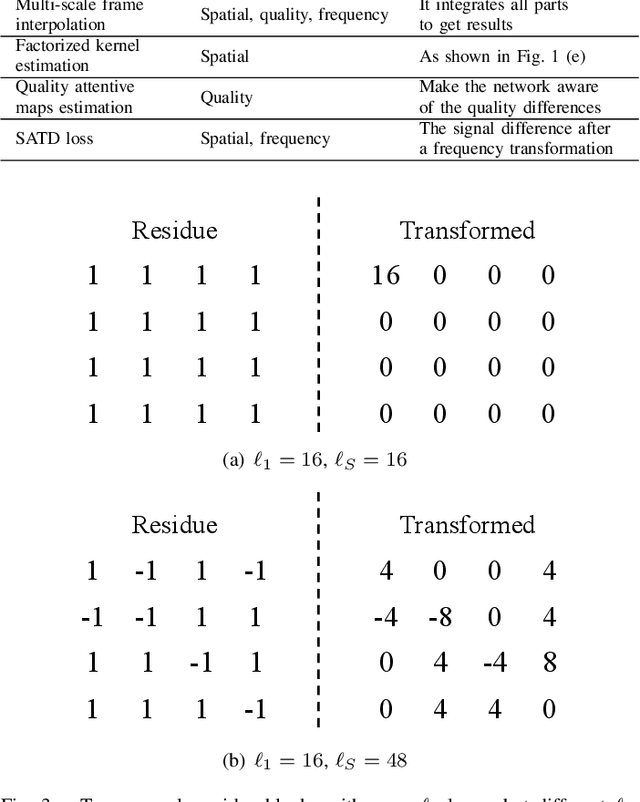
Inter prediction is an important module in video coding for temporal redundancy removal, where similar reference blocks are searched from previously coded frames and employed to predict the block to be coded. Although traditional video codecs can estimate and compensate for block-level motions, their inter prediction performance is still heavily affected by the remaining inconsistent pixel-wise displacement caused by irregular rotation and deformation. In this paper, we address the problem by proposing a deep frame interpolation network to generate additional reference frames in coding scenarios. First, we summarize the previous adaptive convolutions used for frame interpolation and propose a factorized kernel convolutional network to improve the modeling capacity and simultaneously keep its compact form. Second, to better train this network, multi-domain hierarchical constraints are introduced to regularize the training of our factorized kernel convolutional network. For spatial domain, we use a gradually down-sampled and up-sampled auto-encoder to generate the factorized kernels for frame interpolation at different scales. For quality domain, considering the inconsistent quality of the input frames, the factorized kernel convolution is modulated with quality-related features to learn to exploit more information from high quality frames. For frequency domain, a sum of absolute transformed difference loss that performs frequency transformation is utilized to facilitate network optimization from the view of coding performance. With the well-designed frame interpolation network regularized by multi-domain hierarchical constraints, our method surpasses HEVC on average 6.1% BD-rate saving and up to 11.0% BD-rate saving for the luma component under the random access configuration.
Dual Recovery Network with Online Compensation for Image Super-Resolution
Jun 18, 2018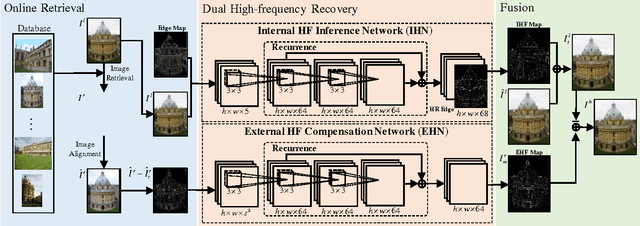
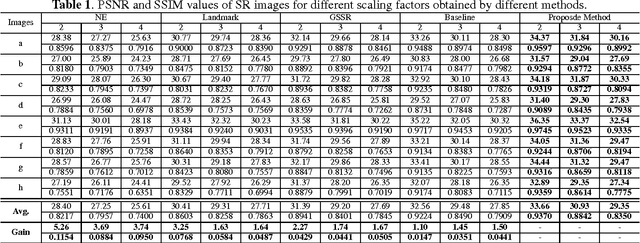

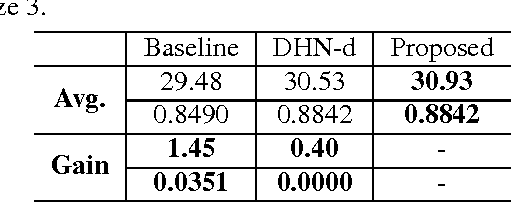
Image super-resolution (SR) methods essentially lead to a loss of some high-frequency (HF) information when predicting high-resolution (HR) images from low-resolution (LR) images without using external references. To address this issue, we additionally utilize online retrieved data to facilitate image SR in a unified deep framework. A novel dual high-frequency recovery network (DHN) is proposed to predict an HR image with three parts: an LR image, an internal inferred HF (IHF) map (HF missing part inferred solely from the LR image) and an external extracted HF (EHF) map. In particular, we infer the HF information based on both the LR image and similar HR references which are retrieved online. For the EHF map, we align the references with affine transformation and then in the aligned references, part of HF signals are extracted by the proposed DHN to compensate for the HF loss. Extensive experimental results demonstrate that our DHN achieves notably better performance than state-of-the-art SR methods.