 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Reinforce Learning with Nonparametric Behavior Clustering
Dec 15, 2017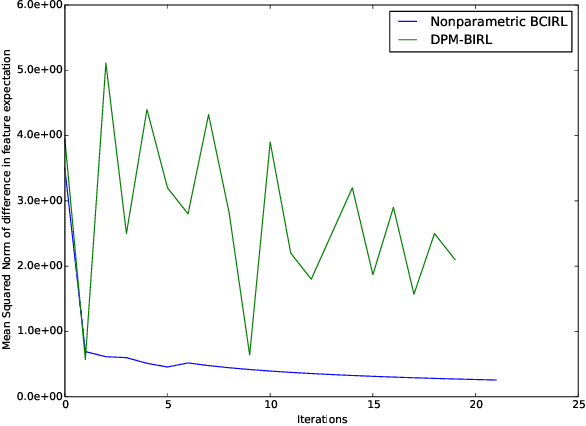

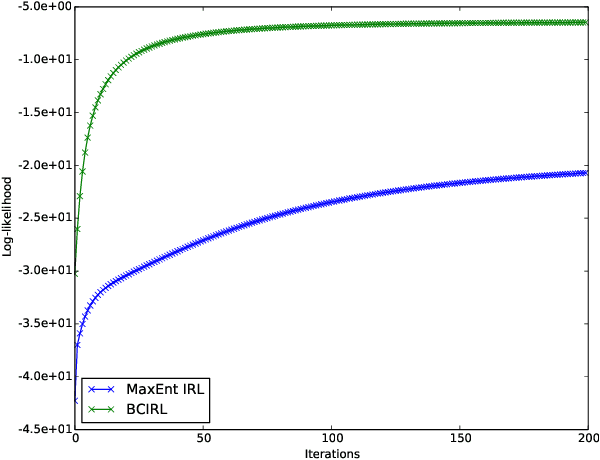
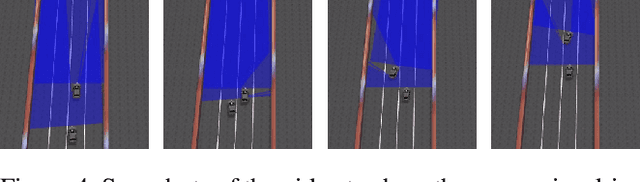
Inverse Reinforcement Learning (IRL) is the task of learning a single reward function given a Markov Decision Process (MDP) without defining the reward function, and a set of demonstrations generated by humans/experts. However, in practice, it may be unreasonable to assume that human behaviors can be explained by one reward function since they may be inherently inconsistent. Also, demonstrations may be collected from various users and aggregated to infer and predict user's behaviors. In this paper, we introduce the Non-parametric Behavior Clustering IRL algorithm to simultaneously cluster demonstrations and learn multiple reward functions from demonstrations that may be generated from more than one behaviors. Our method is iterative: It alternates between clustering demonstrations into different behavior clusters and inverse learning the reward functions until convergence. It is built upon the Expectation-Maximization formulation and non-parametric clustering in the IRL setting. Further, to improve the computation efficiency, we remove the need of completely solving multiple IRL problems for multiple clusters during the iteration steps and introduce a resampling technique to avoid generating too many unlikely clusters. We demonstrate the convergence and efficiency of the proposed method through learning multiple driver behaviors from demonstrations generated from a grid-world environment and continuous trajectories collected from autonomous robot cars using the Gazebo robot simulator.
Towards Planning and Control of Hybrid Systems with Limit Cycle using LQR Trees
Nov 11, 2017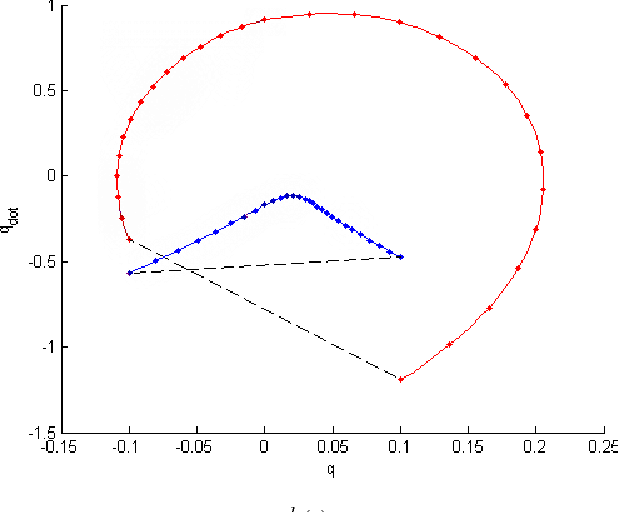
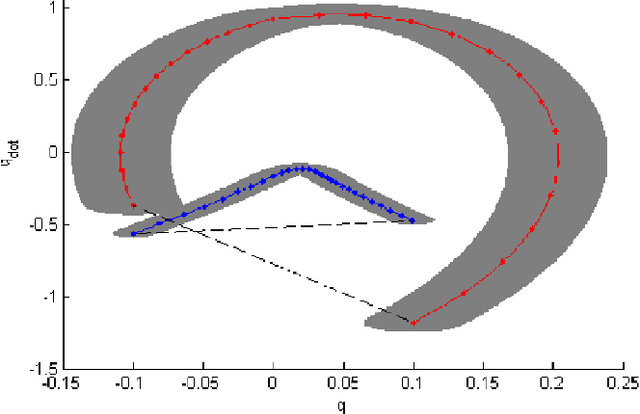

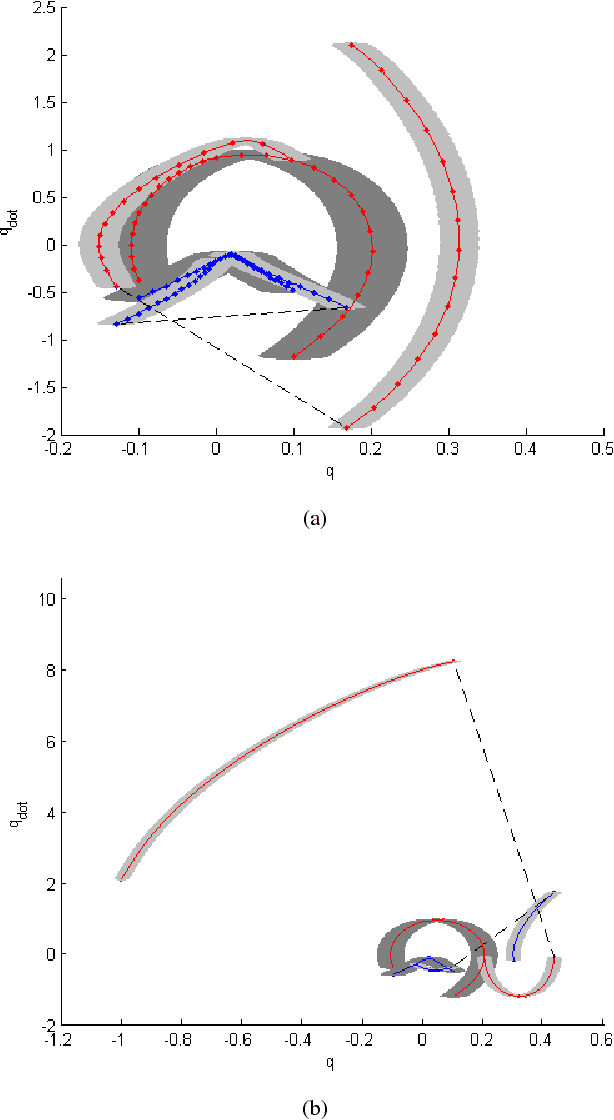
We present a multi-query recovery policy for a hybrid system with goal limit cycle. The sample trajectories and the hybrid limit cycle of the dynamical system are stabilized using locally valid Time Varying LQR controller policies which probabilistically cover a bounded region of state space. The original LQR Tree algorithm builds such trees for non-linear static and non-hybrid systems like a pendulum or a cart-pole. We leverage the idea of LQR trees to plan with a continuous control set, unlike methods that rely on discretization like dynamic programming to plan for hybrid dynamical systems where it is hard to capture the exact event of discrete transition. We test the algorithm on a compass gait model by stabilizing a dynamic walking hybrid limit cycle with point foot contact from random initial conditions. We show results from the simulation where the system comes back to a stable behavior with initial position or velocity perturbation and noise.
Transfer from Multiple Linear Predictive State Representations (PSR)
Feb 07, 2017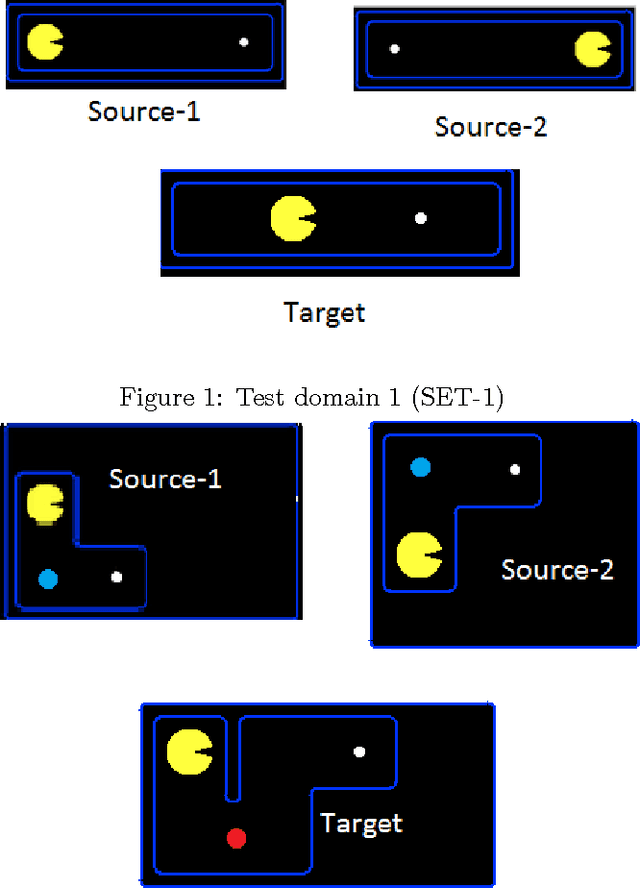

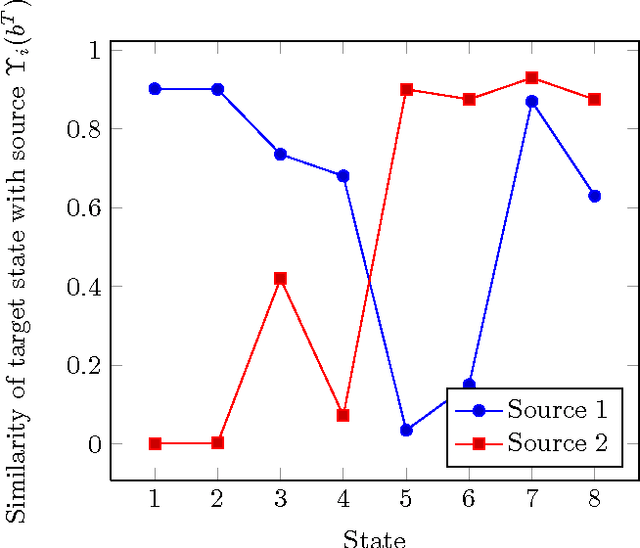
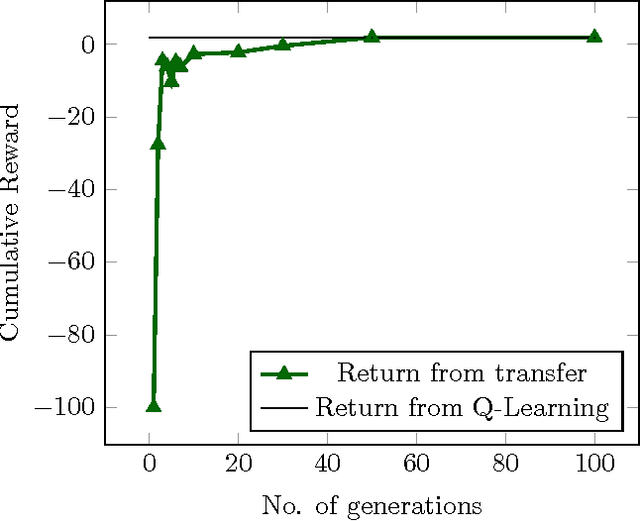
In this paper, we tackle the problem of transferring policy from multiple partially observable source environments to a partially observable target environment modeled as predictive state representation. This is an entirely new approach with no previous work, other than the case of transfer in fully observable domains. We develop algorithms to successfully achieve policy transfer when we have the model of both the source and target tasks and discuss in detail their performance and shortcomings. These algorithms could be a starting point for the field of transfer learning in partial observability.