 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Reinforce Learning with Nonparametric Behavior Clustering
Paper and Code
Dec 15, 2017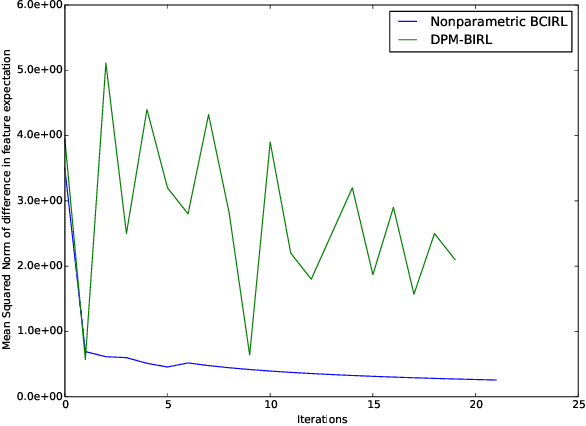

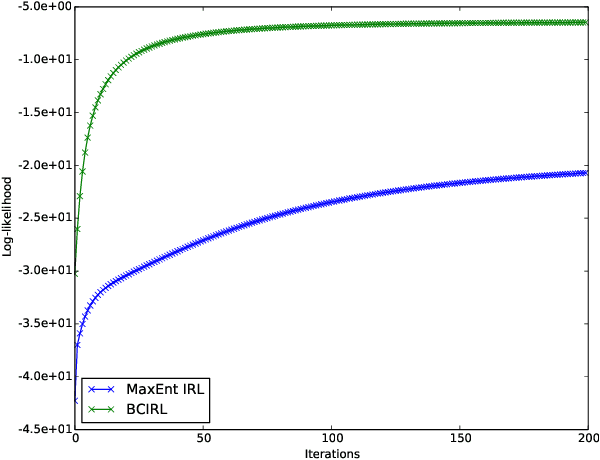
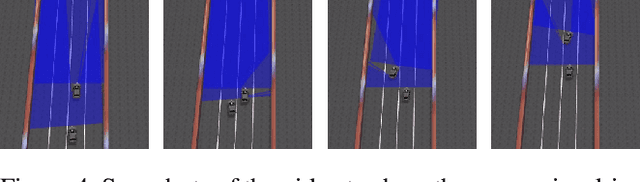
Inverse Reinforcement Learning (IRL) is the task of learning a single reward function given a Markov Decision Process (MDP) without defining the reward function, and a set of demonstrations generated by humans/experts. However, in practice, it may be unreasonable to assume that human behaviors can be explained by one reward function since they may be inherently inconsistent. Also, demonstrations may be collected from various users and aggregated to infer and predict user's behaviors. In this paper, we introduce the Non-parametric Behavior Clustering IRL algorithm to simultaneously cluster demonstrations and learn multiple reward functions from demonstrations that may be generated from more than one behaviors. Our method is iterative: It alternates between clustering demonstrations into different behavior clusters and inverse learning the reward functions until convergence. It is built upon the Expectation-Maximization formulation and non-parametric clustering in the IRL setting. Further, to improve the computation efficiency, we remove the need of completely solving multiple IRL problems for multiple clusters during the iteration steps and introduce a resampling technique to avoid generating too many unlikely clusters. We demonstrate the convergence and efficiency of the proposed method through learning multiple driver behaviors from demonstrations generated from a grid-world environment and continuous trajectories collected from autonomous robot cars using the Gazebo robot simulator.