 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCT-Shield: A Robust Frequency Domain Defense against Malicious Image Editing
Apr 24, 2025Advancements in diffusion models have enabled effortless image editing via text prompts, raising concerns about image security. Attackers with access to user images can exploit these tools for malicious edits. Recent defenses attempt to protect images by adding a limited noise in the pixel space to disrupt the functioning of diffusion-based editing models. However, the adversarial noise added by previous methods is easily noticeable to the human eye. Moreover, most of these methods are not robust to purification techniques like JPEG compression under a feasible pixel budget. We propose a novel optimization approach that introduces adversarial perturbations directly in the frequency domain by modifying the Discrete Cosine Transform (DCT) coefficients of the input image. By leveraging the JPEG pipeline, our method generates adversarial images that effectively prevent malicious image editing. Extensive experiments across a variety of tasks and datasets demonstrate that our approach introduces fewer visual artifacts while maintaining similar levels of edit protection and robustness to noise purification techniques.
LLVD: LSTM-based Explicit Motion Modeling in Latent Space for Blind Video Denoising
Jan 10, 2025



Video restoration plays a pivotal role in revitalizing degraded video content by rectifying imperfections caused by various degradations introduced during capturing (sensor noise, motion blur, etc.), saving/sharing (compression, resizing, etc.) and editing. This paper introduces a novel algorithm designed for scenarios where noise is introduced during video capture, aiming to enhance the visual quality of videos by reducing unwanted noise artifacts. We propose the Latent space LSTM Video Denoiser (LLVD), an end-to-end blind denoising model. LLVD uniquely combines spatial and temporal feature extraction, employing Long Short Term Memory (LSTM) within the encoded feature domain. This integration of LSTM layers is crucial for maintaining continuity and minimizing flicker in the restored video. Moreover, processing frames in the encoded feature domain significantly reduces computations, resulting in a very lightweight architecture. LLVD's blind nature makes it versatile for real, in-the-wild denoising scenarios where prior information about noise characteristics is not available. Experiments reveal that LLVD demonstrates excellent performance for both synthetic and captured noise. Specifically, LLVD surpasses the current State-Of-The-Art (SOTA) in RAW denoising by 0.3dB, while also achieving a 59\% reduction in computational complexity.
GalaxyEdit: Large-Scale Image Editing Dataset with Enhanced Diffusion Adapter
Nov 21, 2024



Training of large-scale text-to-image and image-to-image models requires a huge amount of annotated data. While text-to-image datasets are abundant, data available for instruction-based image-to-image tasks like object addition and removal is limited. This is because of the several challenges associated with the data generation process, such as, significant human effort, limited automation, suboptimal end-to-end models, data diversity constraints and high expenses. We propose an automated data generation pipeline aimed at alleviating such limitations, and introduce GalaxyEdit - a large-scale image editing dataset for add and remove operations. We fine-tune the SD v1.5 model on our dataset and find that our model can successfully handle a broader range of objects and complex editing instructions, outperforming state-of-the-art methods in FID scores by 11.2\% and 26.1\% for add and remove tasks respectively. Furthermore, in light of on-device usage scenarios, we expand our research to include task-specific lightweight adapters leveraging the ControlNet-xs architecture. While ControlNet-xs excels in canny and depth guided generation, we propose to improve the communication between the control network and U-Net for more intricate add and remove tasks. We achieve this by enhancing ControlNet-xs with non-linear interaction layers based on Volterra filters. Our approach outperforms ControlNet-xs in both add/remove and canny-guided image generation tasks, highlighting the effectiveness of the proposed enhancement.
CART: Compositional Auto-Regressive Transformer for Image Generation
Nov 15, 2024

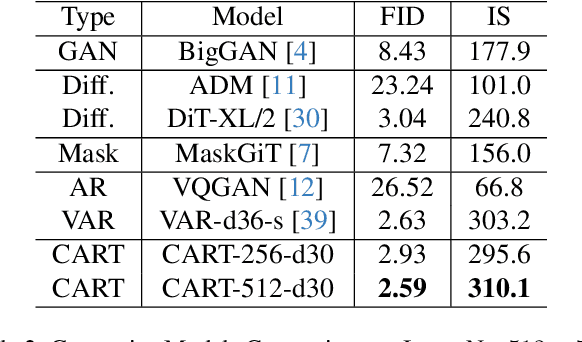

In recent years, image synthesis has achieved remarkable advancements, enabling diverse applications in content creation, virtual reality, and beyond. We introduce a novel approach to image generation using Auto-Regressive (AR) modeling, which leverages a next-detail prediction strategy for enhanced fidelity and scalability. While AR models have achieved transformative success in language modeling, replicating this success in vision tasks has presented unique challenges due to the inherent spatial dependencies in images. Our proposed method addresses these challenges by iteratively adding finer details to an image compositionally, constructing it as a hierarchical combination of base and detail image factors. This strategy is shown to be more effective than the conventional next-token prediction and even surpasses the state-of-the-art next-scale prediction approaches. A key advantage of this method is its scalability to higher resolutions without requiring full model retraining, making it a versatile solution for high-resolution image generation.
Fast OT for Latent Domain Adaptation
Oct 02, 2022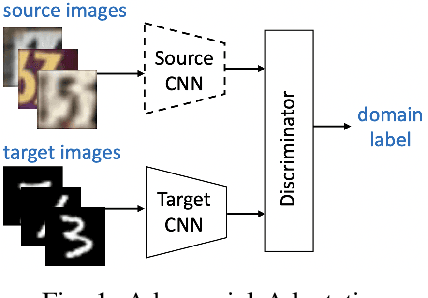
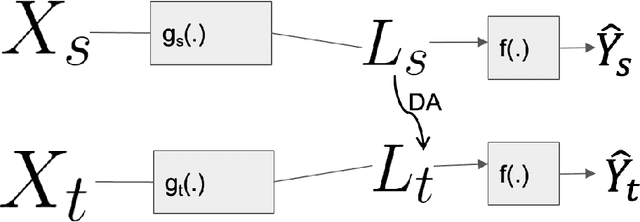
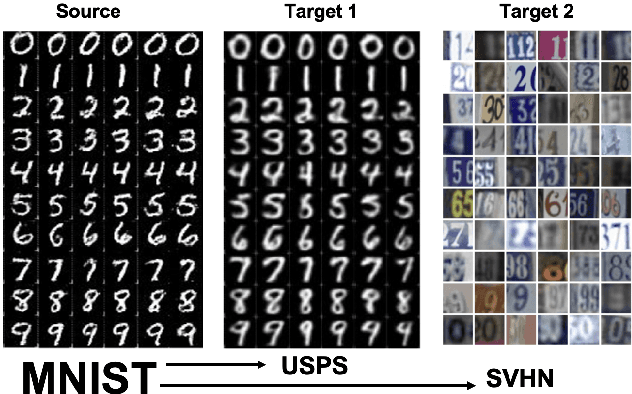
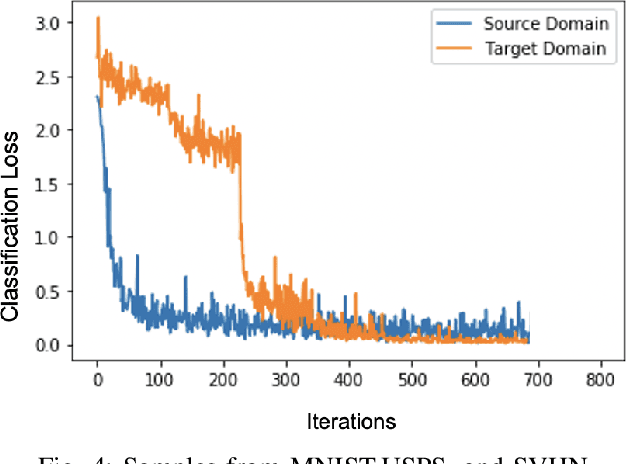
In this paper, we address the problem of unsupervised Domain Adaptation. The need for such an adaptation arises when the distribution of the target data differs from that which is used to develop the model and the ground truth information of the target data is unknown. We propose an algorithm that uses optimal transport theory with a verifiably efficient and implementable solution to learn the best latent feature representation. This is achieved by minimizing the cost of transporting the samples from the target domain to the distribution of the source domain.
Latent Code-Based Fusion: A Volterra Neural Network Approach
Apr 10, 2021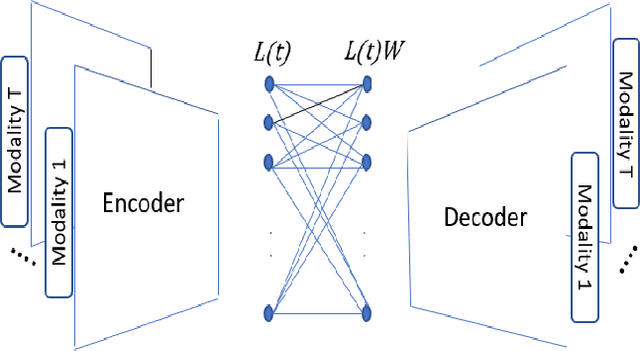
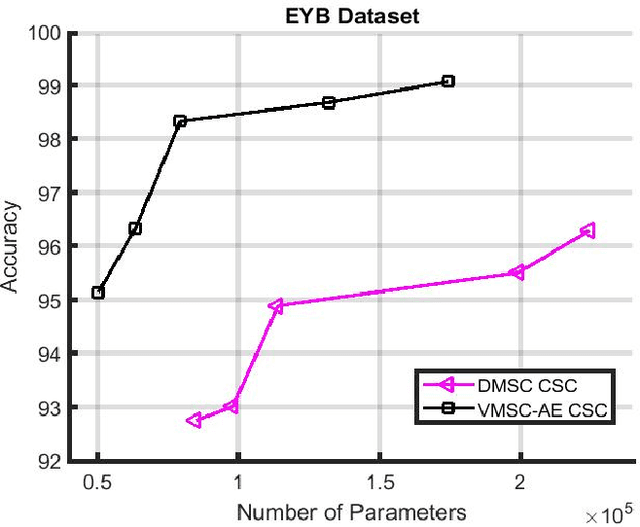
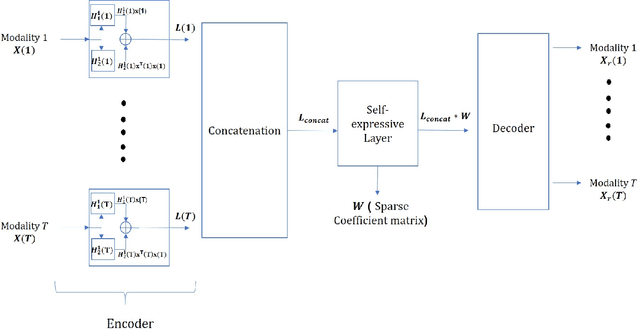
We propose a deep structure encoder using the recently introduced Volterra Neural Networks (VNNs) to seek a latent representation of multi-modal data whose features are jointly captured by a union of subspaces. The so-called self-representation embedding of the latent codes leads to a simplified fusion which is driven by a similarly constructed decoding. The Volterra Filter architecture achieved reduction in parameter complexity is primarily due to controlled non-linearities being introduced by the higher-order convolutions in contrast to generalized activation functions. Experimental results on two different datasets have shown a significant improvement in the clustering performance for VNNs auto-encoder over conventional Convolutional Neural Networks (CNNs) auto-encoder. In addition, we also show that the proposed approach demonstrates a much-improved sample complexity over CNN-based auto-encoder with a superb robust classification performance.
Conquering the CNN Over-Parameterization Dilemma: A Volterra Filtering Approach for Action Recognition
Oct 21, 2019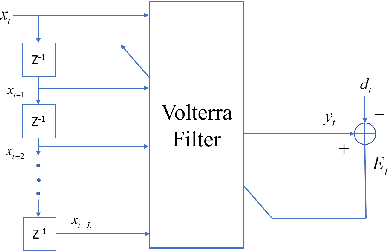
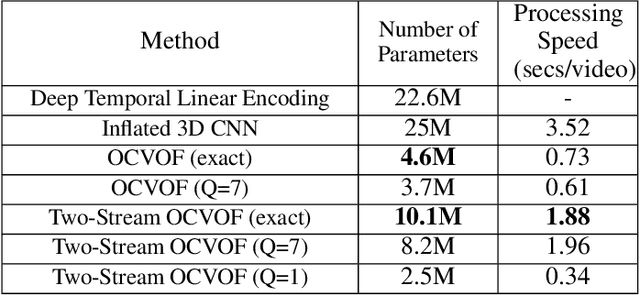


The importance of inference in Machine Learning (ML) has led to an explosive number of different proposals in ML, and particularly in Deep Learning. In an attempt to reduce the complexity of Convolutional Neural Networks, we propose a Volterra filter-inspired Network architecture. This architecture introduces controlled non-linearities in the form of interactions between the delayed input samples of data. We propose a cascaded implementation of Volterra Filter so as to significantly reduce the number of parameters required to carry out the same classification task as that of a conventional Neural Network. We demonstrate an efficient parallel implementation of this new Volterra network, along with its remarkable performance while retaining a relatively simpler and potentially more tractable structure. Furthermore, we show a rather sophisticated adaptation of this network to nonlinearly fuse the RGB (spatial) information and the Optical Flow (temporal) information of a video sequence for action recognition. The proposed approach is evaluated on UCF-101 and HMDB-51 datasets for action recognition, and is shown to outperform state of the art when trained on the datasets from scratch (i.e. without pre-training on a larger dataset).
Commuting Conditional GANs for Robust Multi-Modal Fusion
Jun 24, 2019
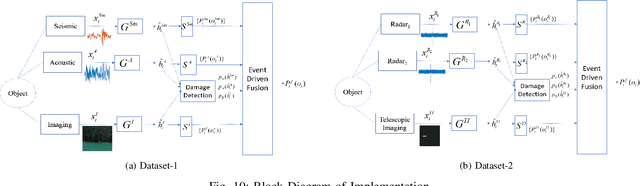
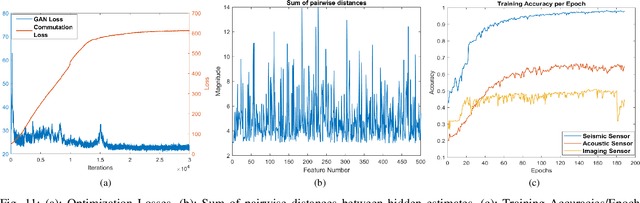

This paper presents a data driven approach to multi-modal fusion, where optimal features for each sensor are selected from a common hidden space between the different modalities. The existence of such a hidden space is then used in order to detect damaged sensors and safeguard the performance of the system. Experimental results show that such an approach can make the system robust against noisy/damaged sensors, without requiring human intervention to inform the system about the damage.