 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCART: Compositional Auto-Regressive Transformer for Image Generation
Paper and Code
Nov 15, 2024

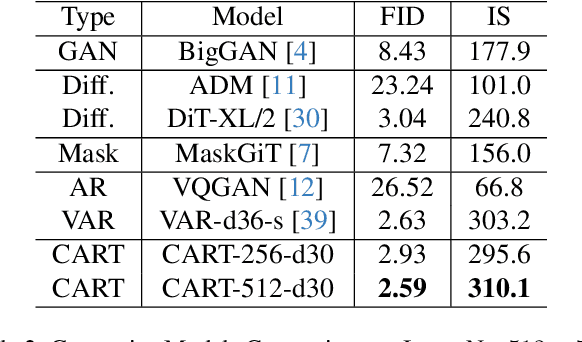

In recent years, image synthesis has achieved remarkable advancements, enabling diverse applications in content creation, virtual reality, and beyond. We introduce a novel approach to image generation using Auto-Regressive (AR) modeling, which leverages a next-detail prediction strategy for enhanced fidelity and scalability. While AR models have achieved transformative success in language modeling, replicating this success in vision tasks has presented unique challenges due to the inherent spatial dependencies in images. Our proposed method addresses these challenges by iteratively adding finer details to an image compositionally, constructing it as a hierarchical combination of base and detail image factors. This strategy is shown to be more effective than the conventional next-token prediction and even surpasses the state-of-the-art next-scale prediction approaches. A key advantage of this method is its scalability to higher resolutions without requiring full model retraining, making it a versatile solution for high-resolution image generation.