 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Code-Based Fusion: A Volterra Neural Network Approach
Paper and Code
Apr 10, 2021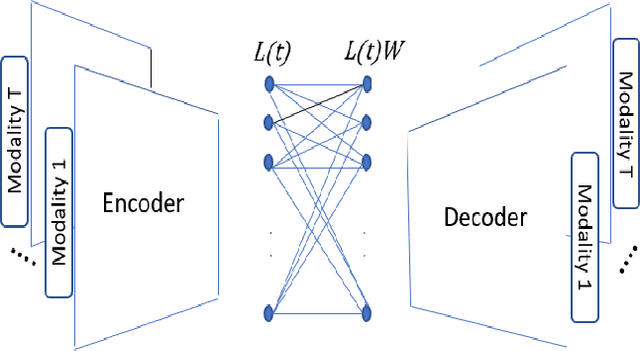
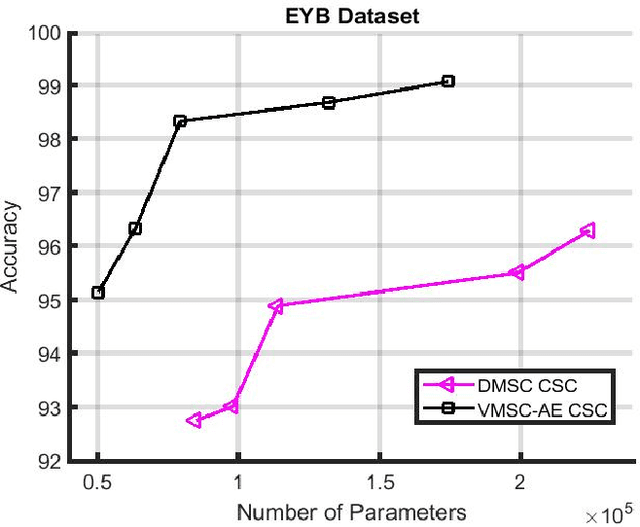
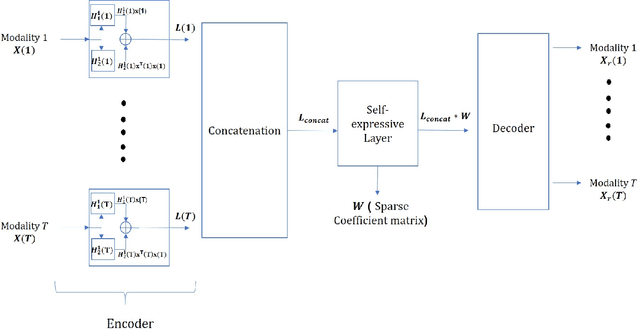
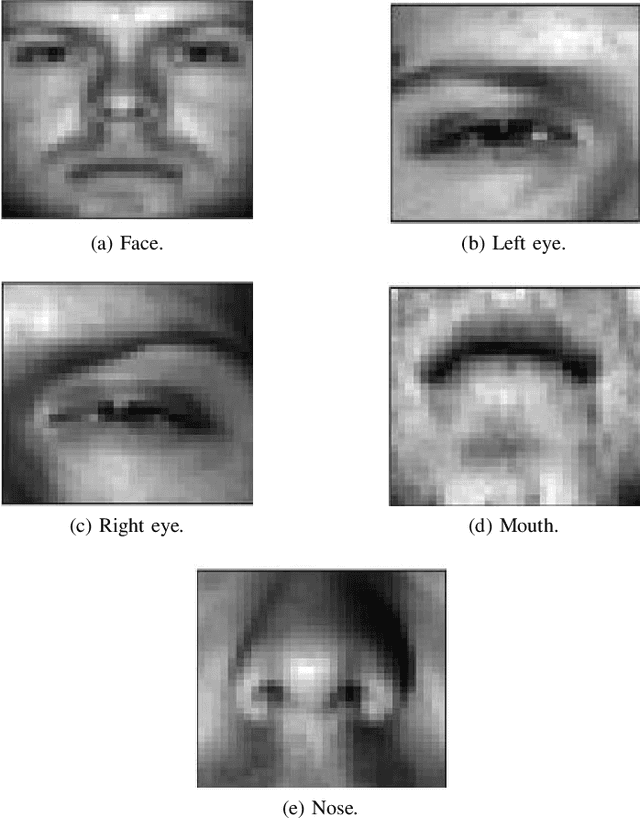
We propose a deep structure encoder using the recently introduced Volterra Neural Networks (VNNs) to seek a latent representation of multi-modal data whose features are jointly captured by a union of subspaces. The so-called self-representation embedding of the latent codes leads to a simplified fusion which is driven by a similarly constructed decoding. The Volterra Filter architecture achieved reduction in parameter complexity is primarily due to controlled non-linearities being introduced by the higher-order convolutions in contrast to generalized activation functions. Experimental results on two different datasets have shown a significant improvement in the clustering performance for VNNs auto-encoder over conventional Convolutional Neural Networks (CNNs) auto-encoder. In addition, we also show that the proposed approach demonstrates a much-improved sample complexity over CNN-based auto-encoder with a superb robust classification performance.