 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Still Further Progress: Chain of Thoughts for Tabular Data Leaderboard
May 19, 2025Tabular data, a fundamental data format in machine learning, is predominantly utilized in competitions and real-world applications. The performance of tabular models--such as gradient boosted decision trees and neural networks--can vary significantly across datasets due to differences in feature distributions and task characteristics. Achieving top performance on each dataset often requires specialized expert knowledge. To address this variability, practitioners often aggregate the predictions of multiple models. However, conventional aggregation strategies typically rely on static combination rules and lack instance-level adaptability. In this work, we propose an in-context ensemble framework for tabular prediction that leverages large language models (LLMs) to perform dynamic, instance-specific integration of external model predictions. Without access to raw tabular features or semantic information, our method constructs a context around each test instance using its nearest neighbors and the predictions from a pool of external models. Within this enriched context, we introduce Chain of Tabular Thoughts (CoT$^2$), a prompting strategy that guides LLMs through multi-step, interpretable reasoning, making still further progress toward expert-level decision-making. Experimental results show that our method outperforms well-tuned baselines and standard ensemble techniques across a wide range of tabular datasets.
Representation Learning for Tabular Data: A Comprehensive Survey
Apr 17, 2025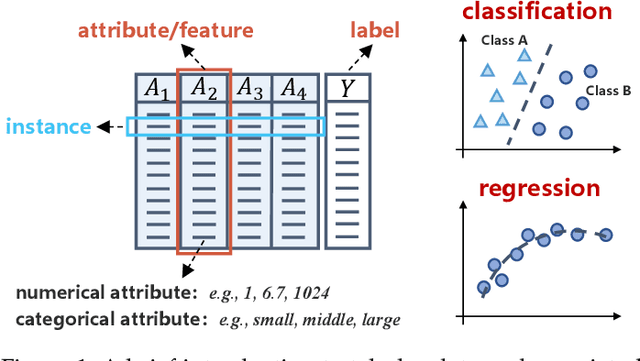
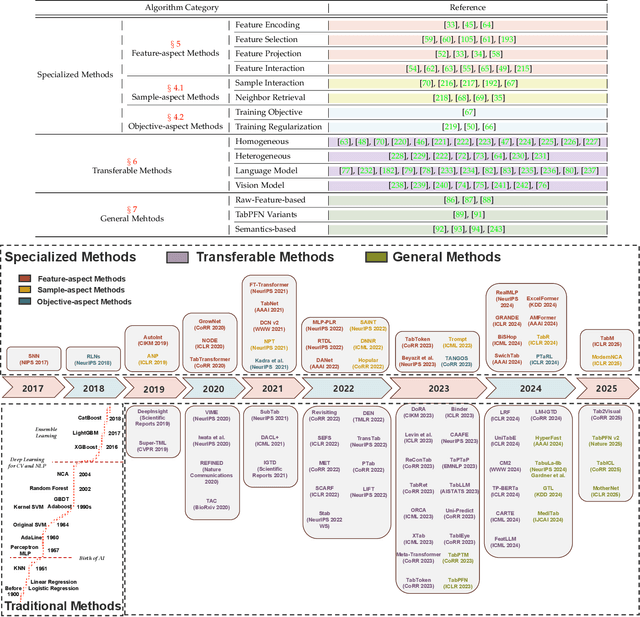
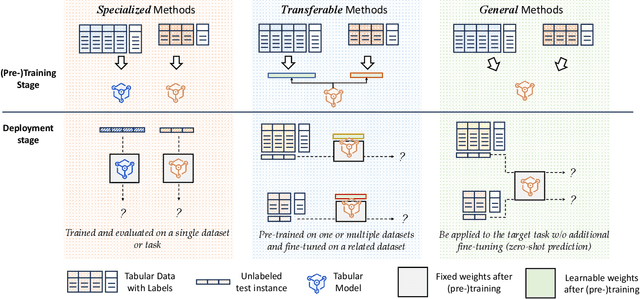
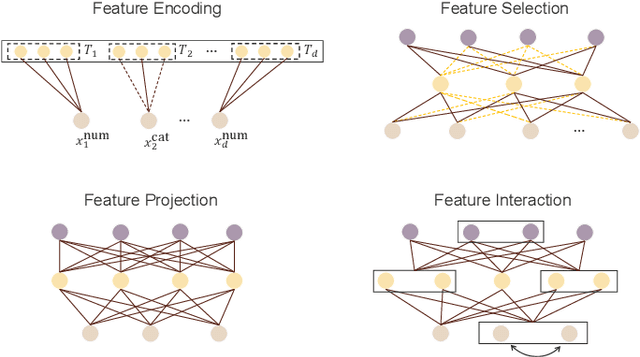
Tabular data, structured as rows and columns, is among the most prevalent data types in machine learning classification and regression applications. Models for learning from tabular data have continuously evolved, with Deep Neural Networks (DNNs) recently demonstrating promising results through their capability of representation learning. In this survey, we systematically introduce the field of tabular representation learning, covering the background, challenges, and benchmarks, along with the pros and cons of using DNNs. We organize existing methods into three main categories according to their generalization capabilities: specialized, transferable, and general models. Specialized models focus on tasks where training and evaluation occur within the same data distribution. We introduce a hierarchical taxonomy for specialized models based on the key aspects of tabular data -- features, samples, and objectives -- and delve into detailed strategies for obtaining high-quality feature- and sample-level representations. Transferable models are pre-trained on one or more datasets and subsequently fine-tuned on downstream tasks, leveraging knowledge acquired from homogeneous or heterogeneous sources, or even cross-modalities such as vision and language. General models, also known as tabular foundation models, extend this concept further, allowing direct application to downstream tasks without fine-tuning. We group these general models based on the strategies used to adapt across heterogeneous datasets. Additionally, we explore ensemble methods, which integrate the strengths of multiple tabular models. Finally, we discuss representative extensions of tabular learning, including open-environment tabular machine learning, multimodal learning with tabular data, and tabular understanding. More information can be found in the following repository: https://github.com/LAMDA-Tabular/Tabular-Survey.
A Closer Look at TabPFN v2: Strength, Limitation, and Extension
Feb 24, 2025Tabular datasets are inherently heterogeneous, posing significant challenges for developing pre-trained foundation models. The recently introduced transformer-based Tabular Prior-data Fitted Network v2 (TabPFN v2) achieves unprecedented in-context learning accuracy across multiple tabular datasets, marking a pivotal advancement in tabular foundation models. In this paper, we comprehensively evaluate TabPFN v2 on over 300 datasets, confirming its exceptional generalization capabilities on small- to medium-scale tasks. Our analysis identifies randomized feature tokens as a key factor behind TabPFN v2's success, as they unify heterogeneous datasets into a fixed-dimensional representation, enabling more effective training and inference. To further understand TabPFN v2's predictions, we propose a leave-one-fold-out approach, transforming TabPFN v2 into a feature extractor and revealing its capability to simplify data distributions and boost accuracy. Lastly, to address TabPFN v2's limitations in high-dimensional, large-scale, and many-category tasks, we introduce a divide-and-conquer mechanism inspired by Chain-of-Thought prompting, enabling scalable inference. By uncovering the mechanisms behind TabPFN v2's success and introducing strategies to expand its applicability, this study provides key insights into the future of tabular foundation models.
TabPFN Unleashed: A Scalable and Effective Solution to Tabular Classification Problems
Feb 04, 2025TabPFN has emerged as a promising in-context learning model for tabular data, capable of directly predicting the labels of test samples given labeled training examples. It has demonstrated competitive performance, particularly on small-scale classification tasks. However, despite its effectiveness, TabPFN still requires further refinement in several areas, including handling high-dimensional features, aligning with downstream datasets, and scaling to larger datasets. In this paper, we revisit existing variants of TabPFN and observe that most approaches focus either on reducing bias or variance, often neglecting the need to address the other side, while also increasing inference overhead. To fill this gap, we propose Beta (Bagging and Encoder-based Fine-tuning for TabPFN Adaptation), a novel and effective method designed to minimize both bias and variance. To reduce bias, we introduce a lightweight encoder to better align downstream tasks with the pre-trained TabPFN. By increasing the number of encoders in a lightweight manner, Beta mitigate variance, thereby further improving the model's performance. Additionally, bootstrapped sampling is employed to further reduce the impact of data perturbations on the model, all while maintaining computational efficiency during inference. Our approach enhances TabPFN's ability to handle high-dimensional data and scale to larger datasets. Experimental results on over 200 benchmark classification datasets demonstrate that Beta either outperforms or matches state-of-the-art methods.
TALENT: A Tabular Analytics and Learning Toolbox
Jul 04, 2024
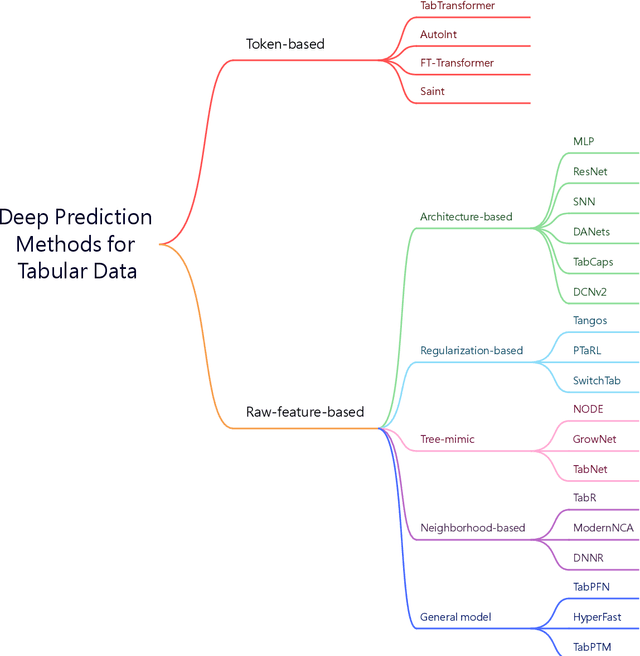
Tabular data is one of the most common data sources in machine learning. Although a wide range of classical methods demonstrate practical utilities in this field, deep learning methods on tabular data are becoming promising alternatives due to their flexibility and ability to capture complex interactions within the data. Considering that deep tabular methods have diverse design philosophies, including the ways they handle features, design learning objectives, and construct model architectures, we introduce a versatile deep-learning toolbox called TALENT (Tabular Analytics and LEarNing Toolbox) to utilize, analyze, and compare tabular methods. TALENT encompasses an extensive collection of more than 20 deep tabular prediction methods, associated with various encoding and normalization modules, and provides a unified interface that is easily integrable with new methods as they emerge. In this paper, we present the design and functionality of the toolbox, illustrate its practical application through several case studies, and investigate the performance of various methods fairly based on our toolbox. Code is available at https://github.com/qile2000/LAMDA-TALENT.
A Closer Look at Deep Learning on Tabular Data
Jul 01, 2024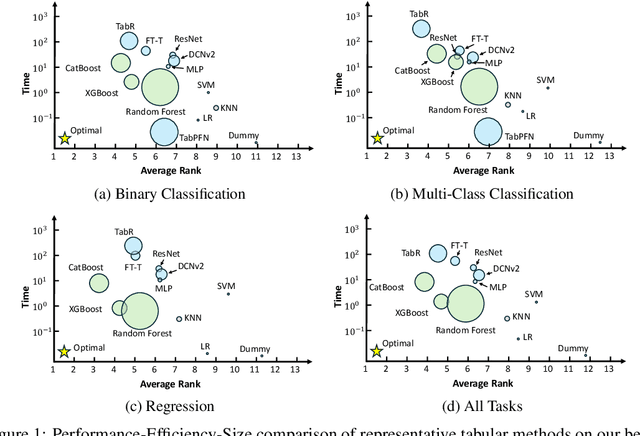
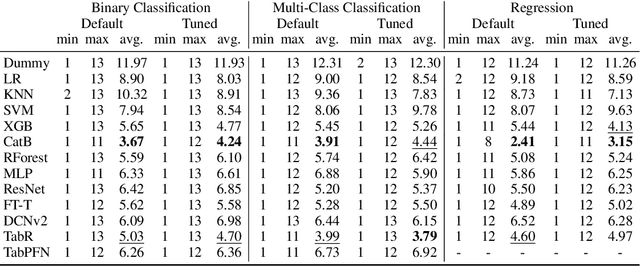
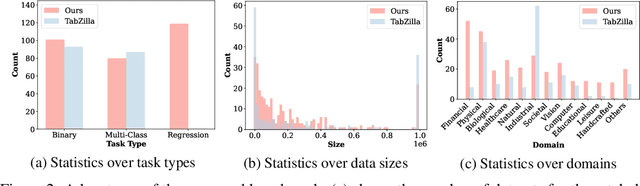
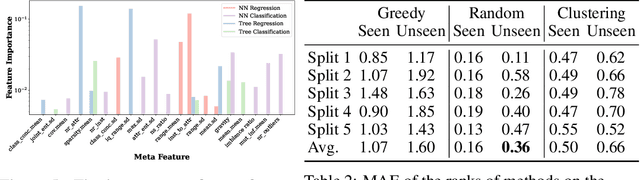
Tabular data is prevalent across various domains in machine learning. Although Deep Neural Network (DNN)-based methods have shown promising performance comparable to tree-based ones, in-depth evaluation of these methods is challenging due to varying performance ranks across diverse datasets. In this paper, we propose a comprehensive benchmark comprising 300 tabular datasets, covering a wide range of task types, size distributions, and domains. We perform an extensive comparison between state-of-the-art deep tabular methods and tree-based methods, revealing the average rank of all methods and highlighting the key factors that influence the success of deep tabular methods. Next, we analyze deep tabular methods based on their training dynamics, including changes in validation metrics and other statistics. For each dataset-method pair, we learn a mapping from both the meta-features of datasets and the first part of the validation curve to the final validation set performance and even the evolution of validation curves. This mapping extracts essential meta-features that influence prediction accuracy, helping the analysis of tabular methods from novel aspects. Based on the performance of all methods on this large benchmark, we identify two subsets of 45 datasets each. The first subset contains datasets that favor either tree-based methods or DNN-based methods, serving as effective analysis tools to evaluate strategies (e.g., attribute encoding strategies) for improving deep tabular models. The second subset contains datasets where the ranks of methods are consistent with the overall benchmark, acting as a probe for tabular analysis. These ``tiny tabular benchmarks'' will facilitate further studies on tabular data.